728x90
K-means
- yellowbrick
- 선행 작업 문자형 수치형으로
- 선행 작업 scaling
#[문제 1] 필요 라이브러리 로딩
# numpy, pandas, matplotlib, seaborn, os 를 임포트 하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
# 시각화 표에서 에러나는 부분 글꼴 셋팅
plt.rc("font", family = "Malgun Gothic")
sns.set(font="Malgun Gothic",
rc={"axes.unicode_minus":False}, style='white')
# 지수표현(소수점 2자리까지 나타내기)
pd.options.display.float_format = '{:.2f}'.format
# [문제 2] 스케일링 한 데이터 불러오기
# 1. data 변수에 'scaler_data.csv' 파일을 불러와서 할당, 인코딩은 utf-8
# 2. data 변수 호출해서 상위 5개 확인해보기
data = pd.read_csv('scaler_data.csv', encoding = 'UTF -8 ')
import yellowbrick
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
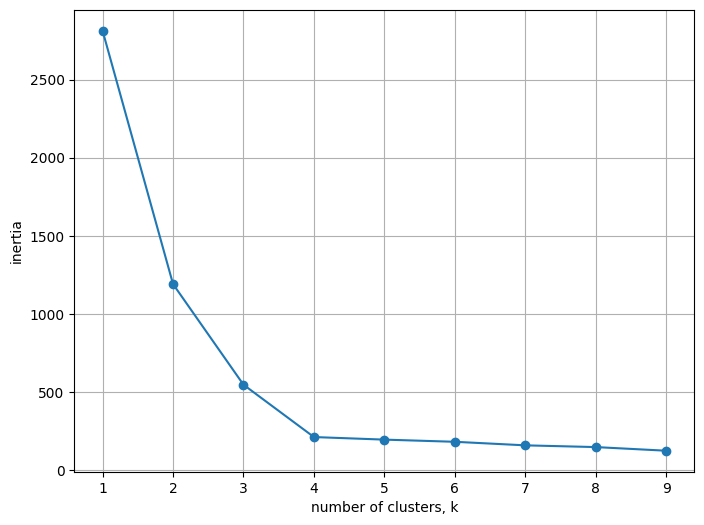
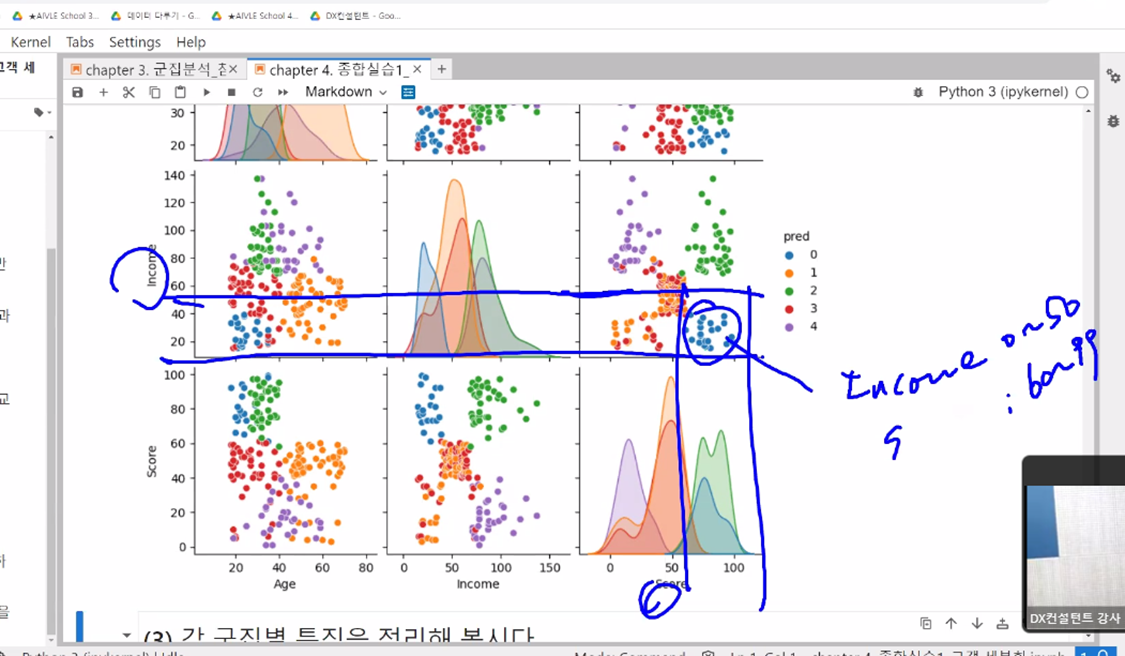
# Elbow Method 활용해서 k 값 구하기
- yellowbrick의 k-Elbow Mehod를 활용해서 최적의 k 값을 구하기(k값 결정하기 쉽게 도와주는 함수)
#Elbow Method를 통해 최적의 군집 수 도출을 해보자.
from yellowbrick.cluster import KElbowVisualizer
from sklearn.cluster import KMeans
# 1. 모델 선언하기 (random_state=2023, n_init=10 으로 설정)
model_E = KMeans(random_state=2023, n_init=10)
# 2. KElbowVisualizer 에 k-means 모델과 k값 넣어서 만들기(Elbow_M 에 할당)
# k값은 k=(3,11)사이의 값중에서 찾는 것으로 넣으면 된다.
Elbow_M = KElbowVisualizer(model_E, k=(3, 11))
# 3. Elbow 모델 학습하기(fit)
Elbow_M.fit(data)
# 4. Elbow 모델 확인하기(show()활용)
Elbow_M.show()

선행 작업 문자형 수치형으로
# 상품타입'범주를 인코딩 해보기
# loc를 활용해서 '기본,중급'을 0으로 변환/ '고급'을 1로 변환
data_choice.loc[(data_choice['상품타입']=='기본') | (data_choice['상품타입']=='중급'),'상품타입'] = 0
#---------------------------------------------------------------
data_choice.loc[data_choice['상품타입']=='고급','상품타입'] = 1
# 데이터 안의 정보는 수치형이지만 dtype은 아직 object 이다. 범주형을 수치형으로 변경해 주자!
# astype-> float64 활용해서 변경 후 확인
data_choice_n = data_choice_n.astype('float64')
선행 작업 scaling
# min-max-scaler & standard-scaler import!(sklearn의 processing 활용)
from sklearn.preprocessing import MinMaxScaler, StandardScaler
#. scaler라는 변수에 MinMaxScaler 넣어주기
scaler = MinMaxScaler()
#. 'data_choice_n'을 'scaler_data' 변수에 fit-transform으로 fit 하기!
# 각 열을 스케일링
scaler_data = scaler.fit_transform(data_choice_n)
print("scaler_data",scaler_data)
# 컬럼은 이전 dataframe('data_choice_n') 에서 그대로 가져와서 'scaler_data.columns'에 할당하기
# 컬럼 가져오기
scaler_columns = data_choice_n.columns
pd.DataFrame(scaler_data, columns = data_choice_n.columns)
# 스케일링이 잘 되었는지 'scaler_data' 데이터를 확인해보자
scaler_data = pd.DataFrame(scaler_data, columns = data_choice_n.columns)
scaler_data728x90
'데이터 - 머신러닝 비지도 학습' 카테고리의 다른 글
| 비지도 학습] PCA (0) | 2023.09.20 |
|---|---|
| 비지도 학습] k-means (0) | 2023.09.20 |