BeautifulSoup, selenium, ChromeDriverManager, WebdriverWait 라이브러리 등을 불러옵니다.
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
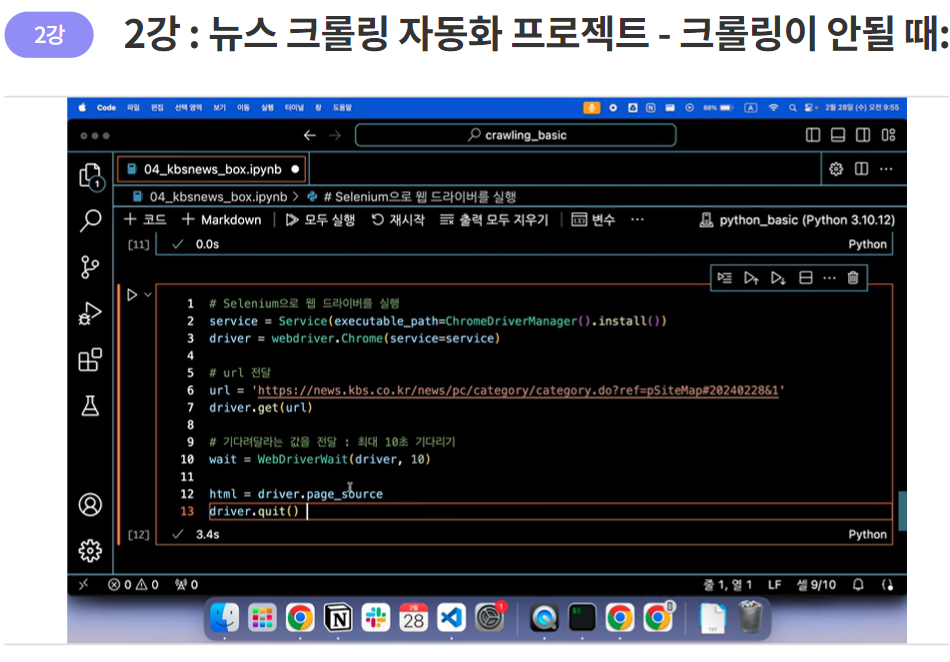
아래 코드를 통하여, Selenium 웹 드라이버를 실행하는 과정을 수행합니다.
# Selenium 웹 드라이버 실행
driver = webdriver.Chrome(service = service)
driver.get(url)
wait = WebDriverWait(driver, 10)
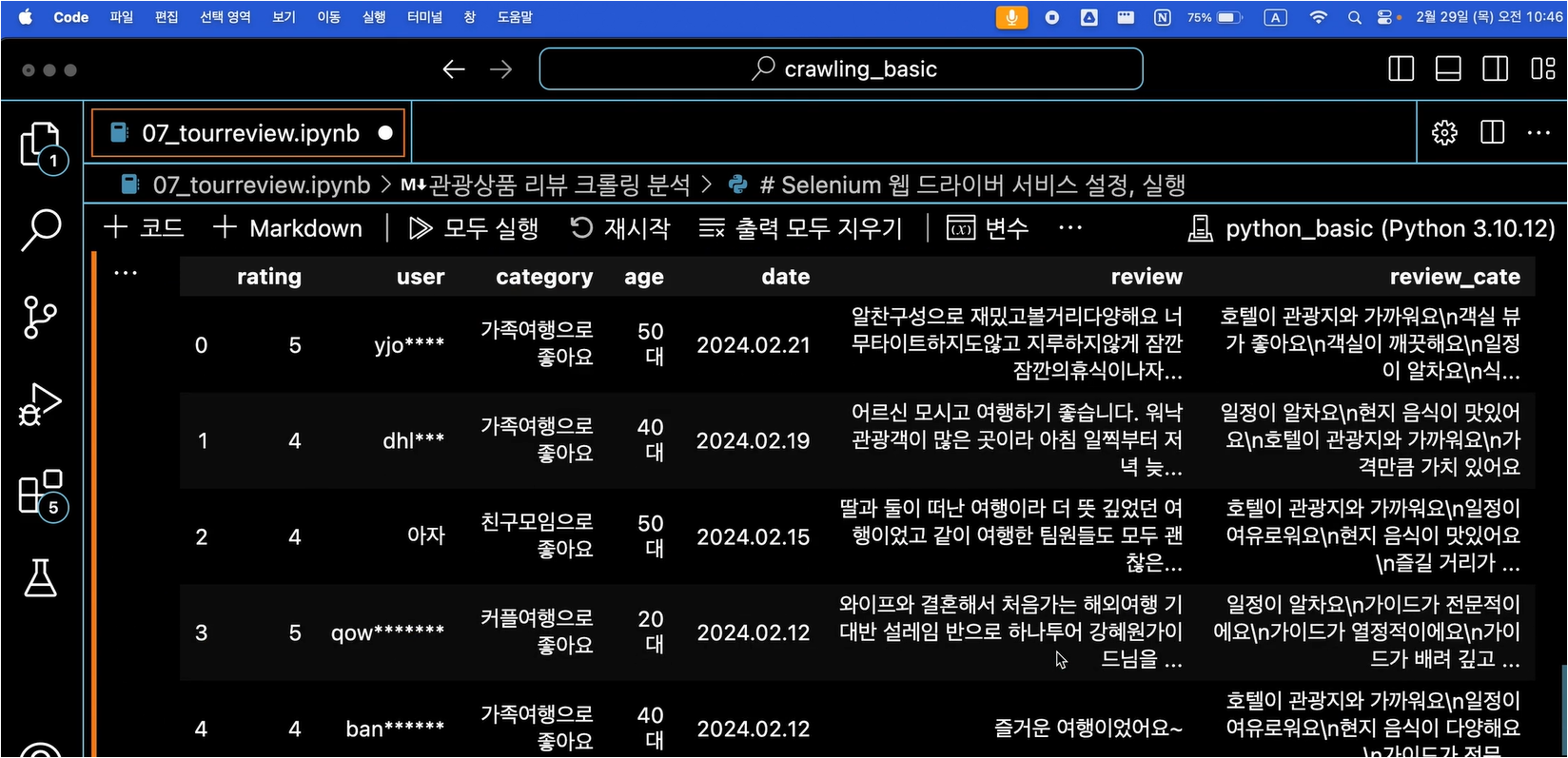
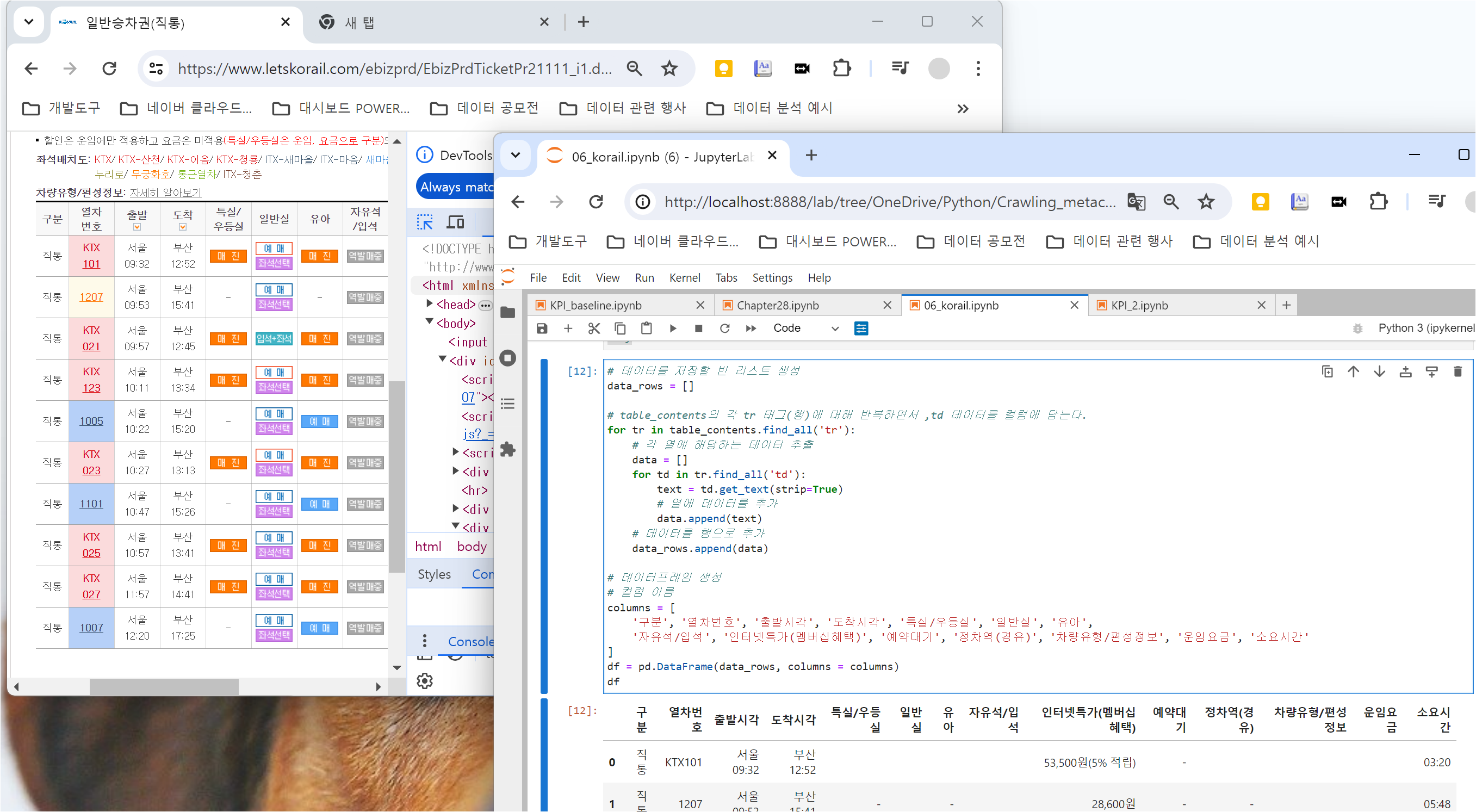
테이블 정보를 담는 데이터프레임을 생성합니다.
리스트 구조를 활용하여 for문을 돌면서 각 tr의 td 데이터를 담는 데이터프레임을 생성합니다.
아래와 같이 tr 안의 td에 들어있는 값들을 하나씩 리스트에 추가하는 코드를 작성합니다.
# 데이터를 저장할 빈 리스트 생성
data_rows = []
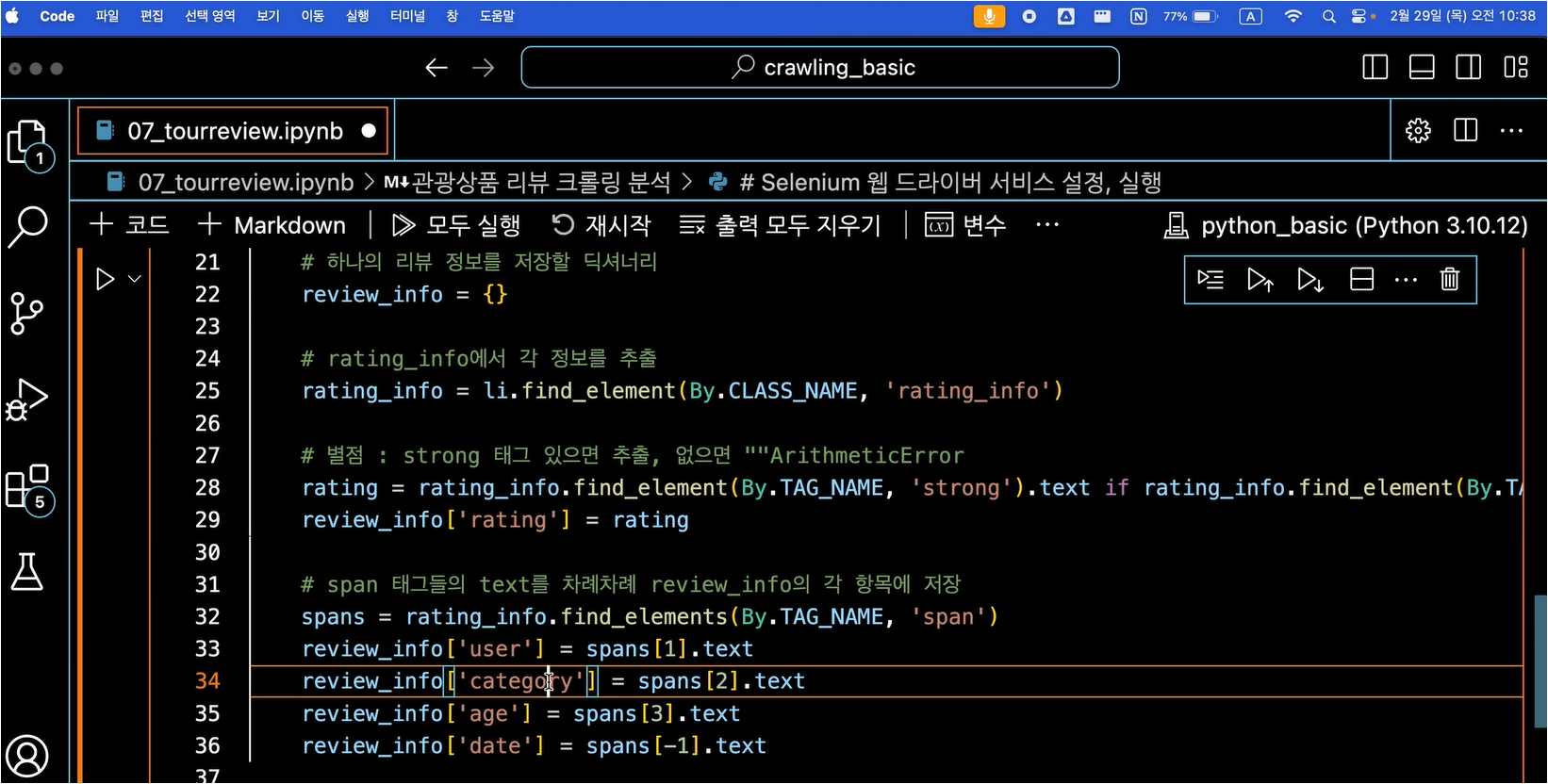
# table_contents의 각 tr 태그(행)에 대해 반복하면서 ,td 데이터를 컬럼에 담는다.for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# 데이터를 행으로 추가
data_rows.append(data)
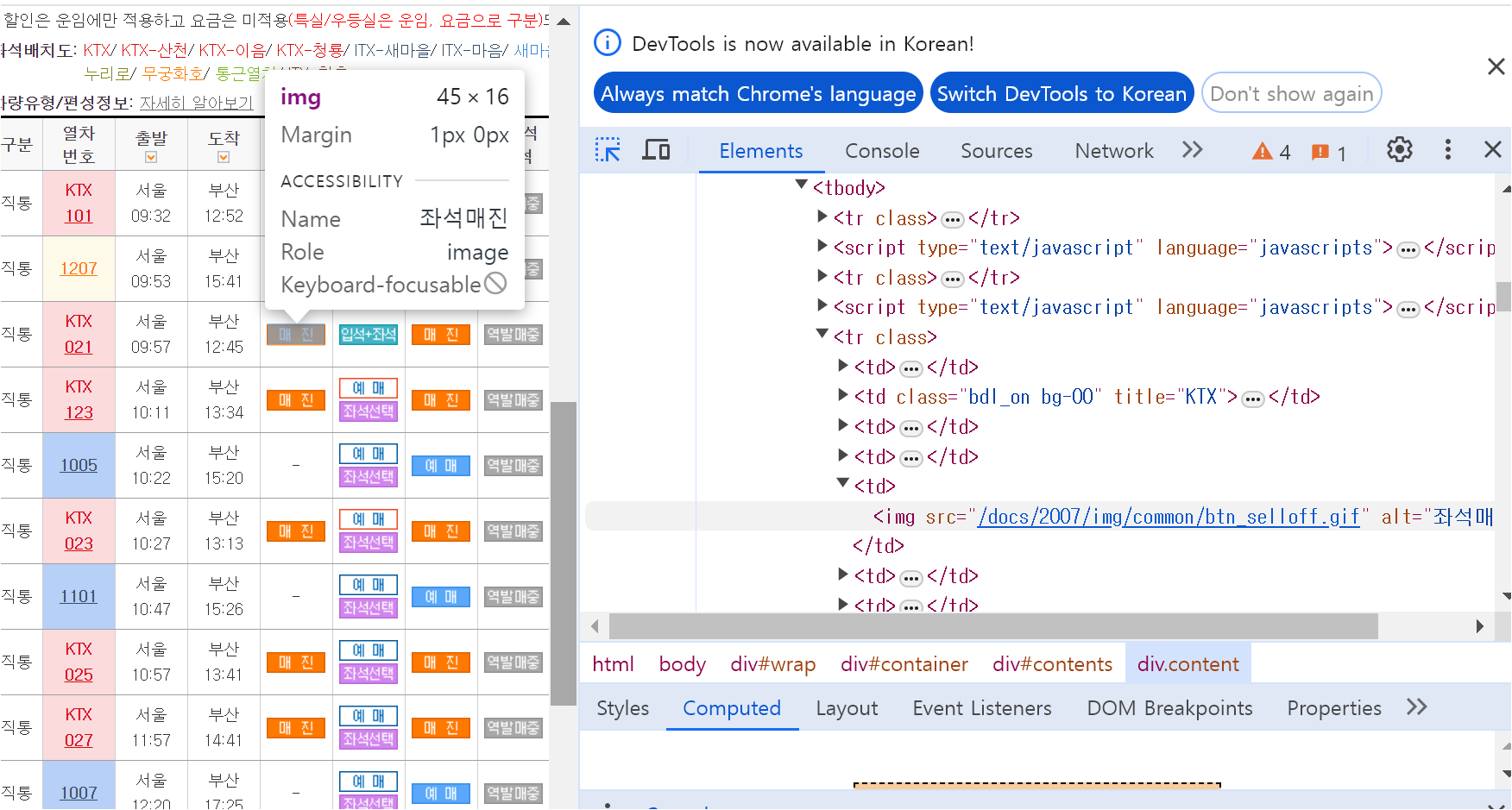
위에서와 마찬가지로 for문 구조를 작성하는데, 이번에는 td.find('img') 코드를 추가하여,
위에서 만든 데이터프레임에 빈 칸이 생기는 경우가 없도록 할 것입니다.
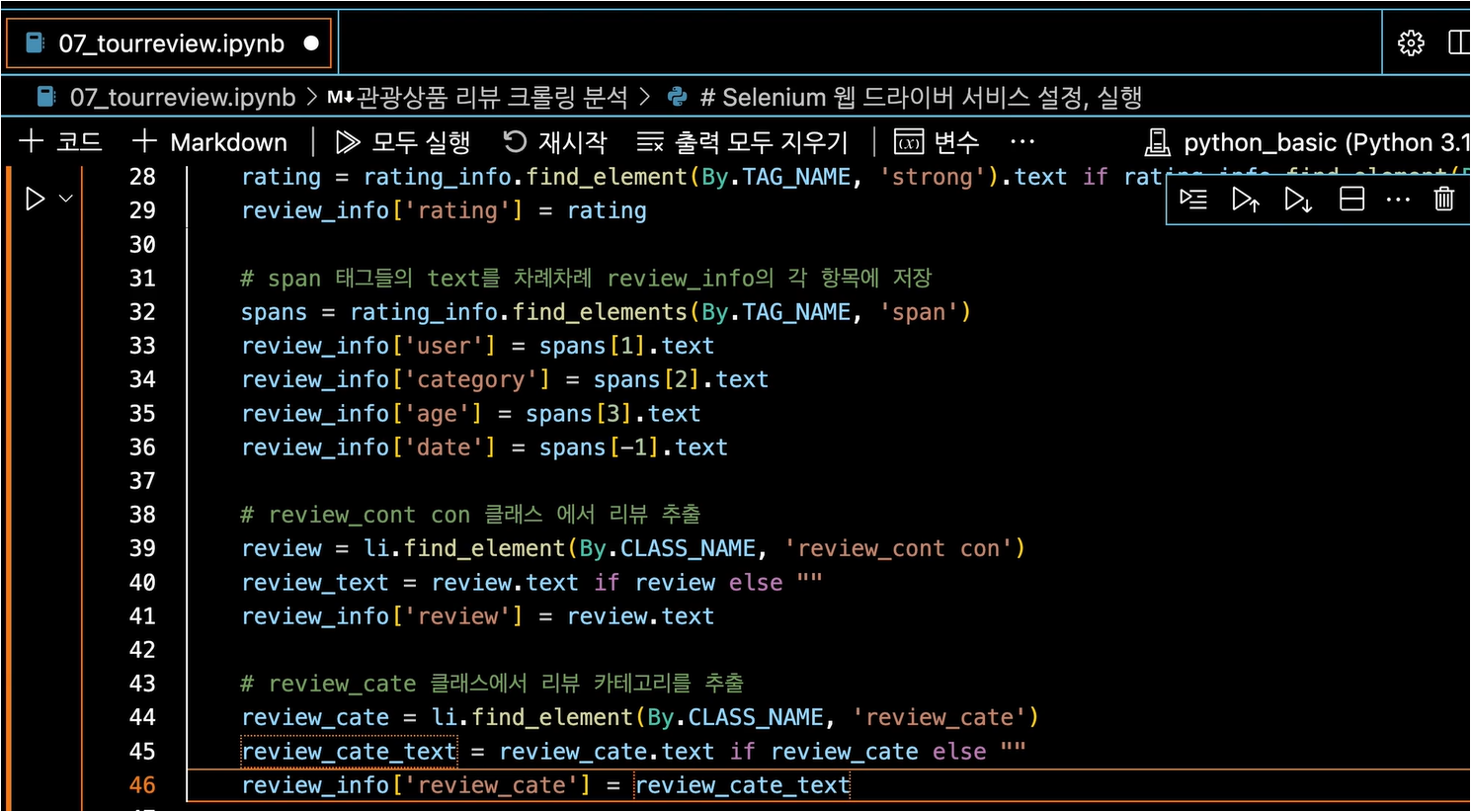
# table_contents의 각 tr 태그(행)에 대해 반복하면서, td 데이터를 컬럼에 담아준다.for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
# td 안에 있는 im 태그가 있는지 확인, alt 속성 추출
img_tag = td.find('img')
# img_tag가 존재하면if img_tag:
text = img_tag.get("alt", "")
else:
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
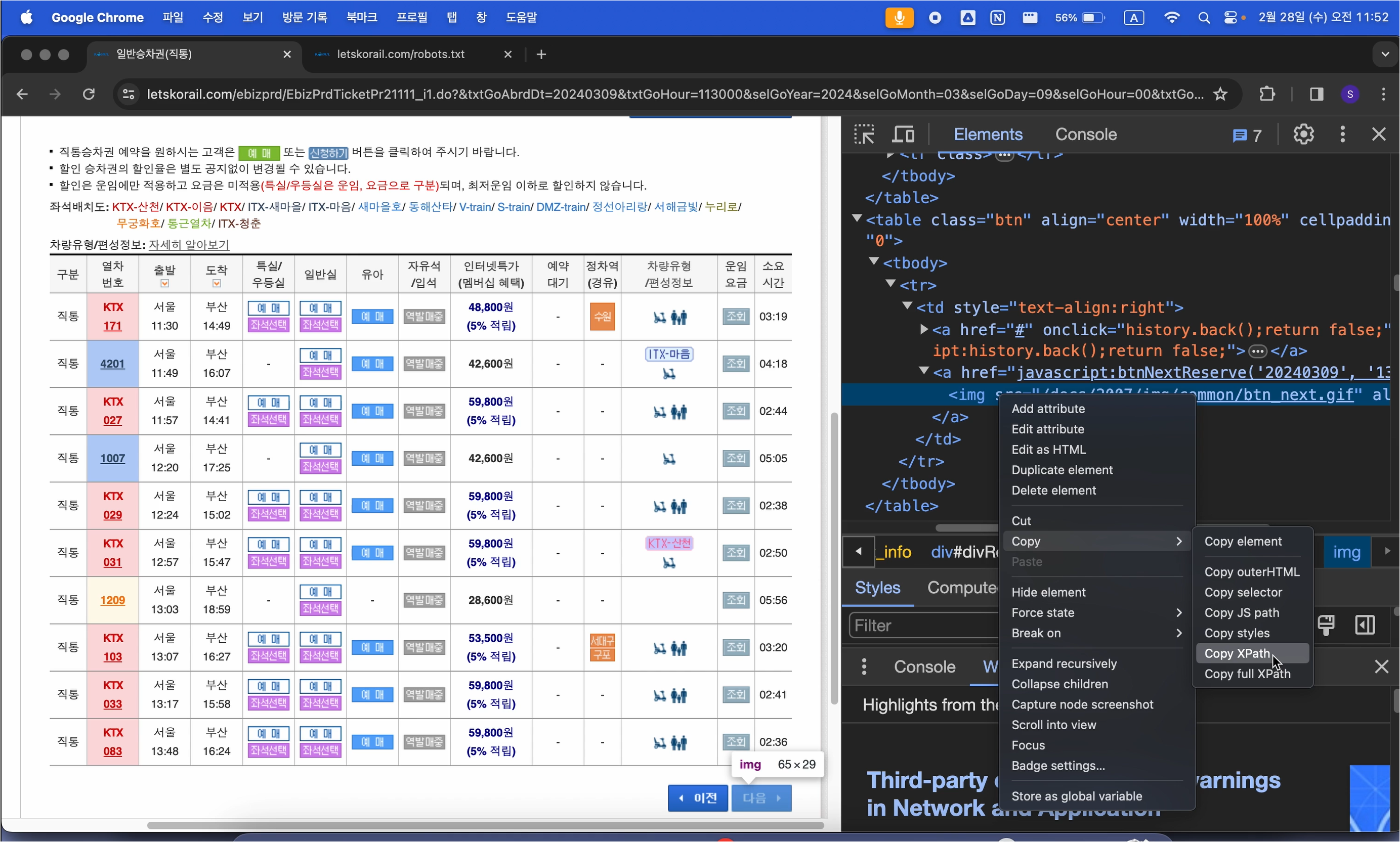
# data, 즉 방금까지 td 태그들이 쌓인 data 리스트에 url도 하나 더 추가
data.append(url)
# 데이터를 행으로 추가
data_rows.append(data)
"if img_tag" 조건문을 추가하고 img 태그가 있는 경우에는 "img_tag.get("alt", "")" 과정이 수행되도록 합니다.
그 외의 경우에는 위에서 진행한 대로 "td.get_text(strip=True)" 과정이 진행되도록 합니다.
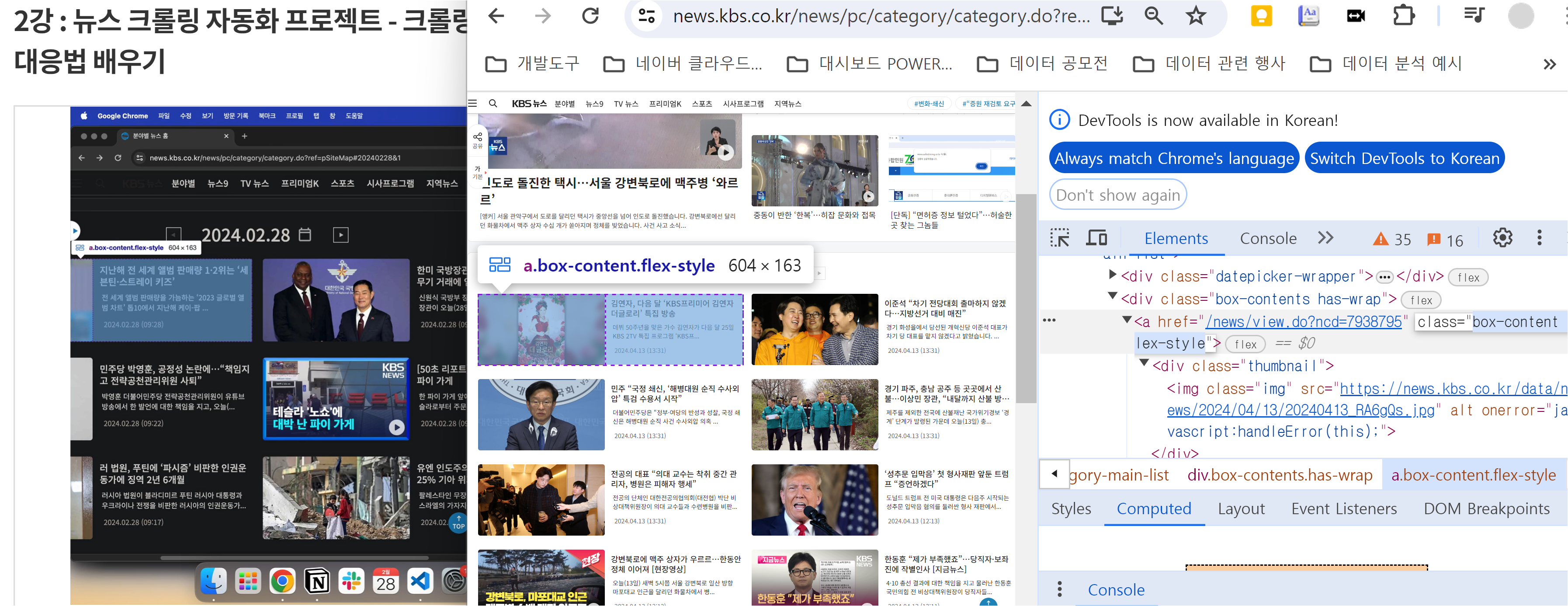
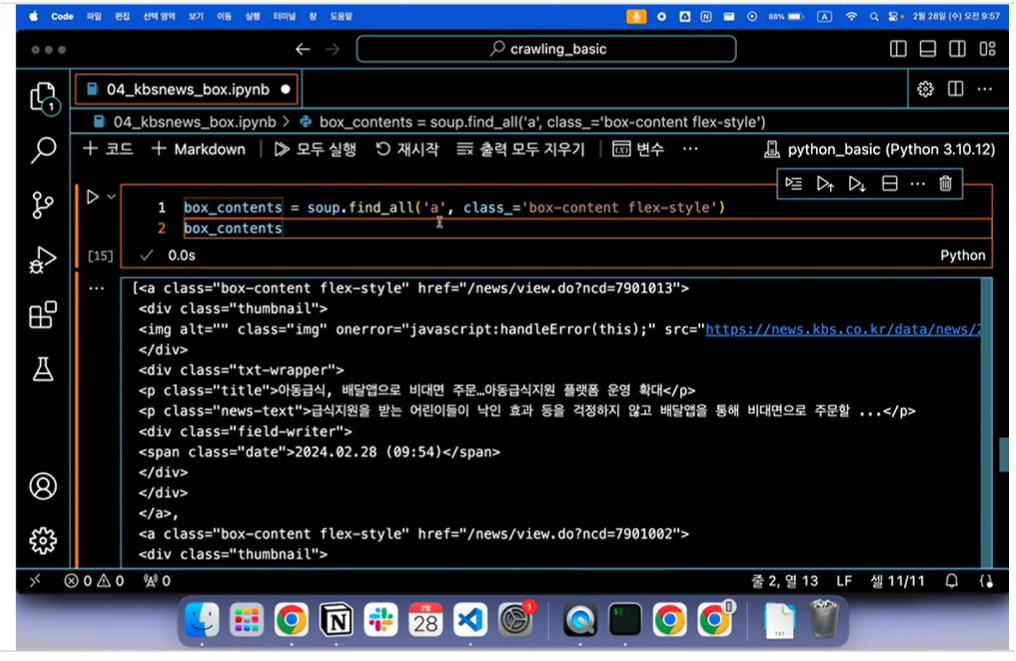
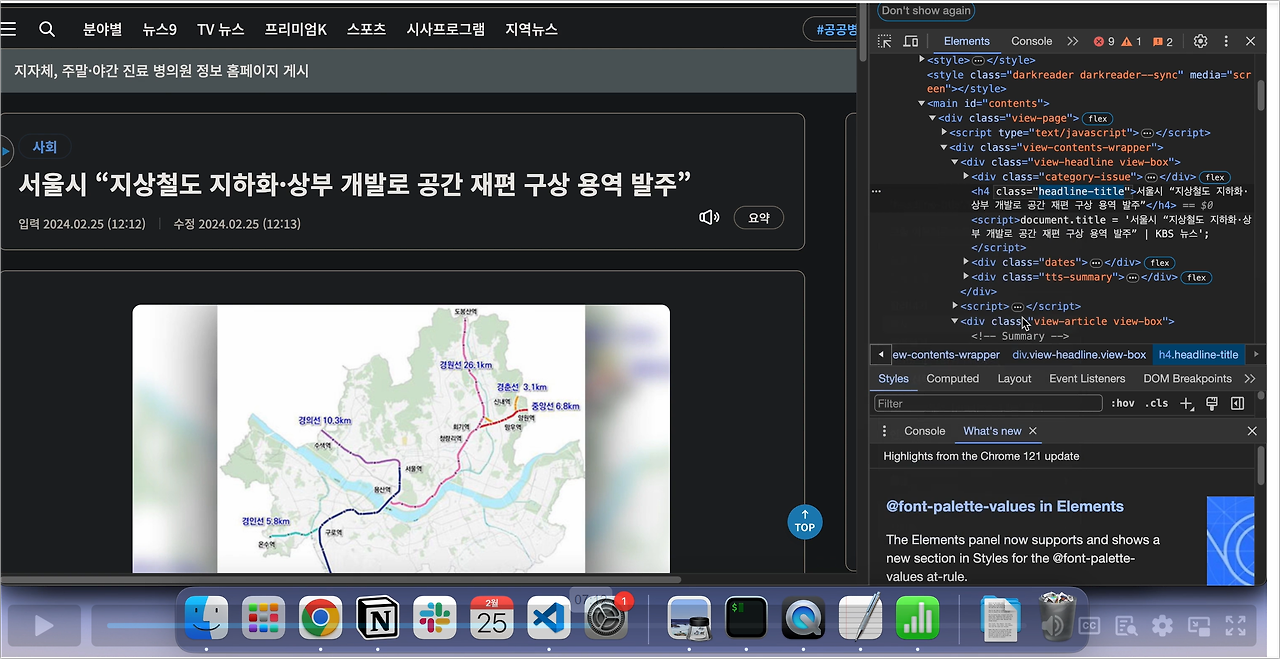
KBS 뉴스탭에서 전체 카테고리를 선택하고 일자별 뉴스 항목에 접근합니다. 먼저, 한 항목을 선택하여 페이지로 이동합니다. F12 버튼을 통해 개발자 모드에 접근하면 각 element들에 대한 자세한 정보를 얻을 수 있으며 이는 뒤에서 바로 진행할 것입니다.
하나의 요소에서 정보를 수집하는 것으로 시작하여, 추후에 여러 뉴스에서 정보를 수집하는 실습을 진행할 것입니다.
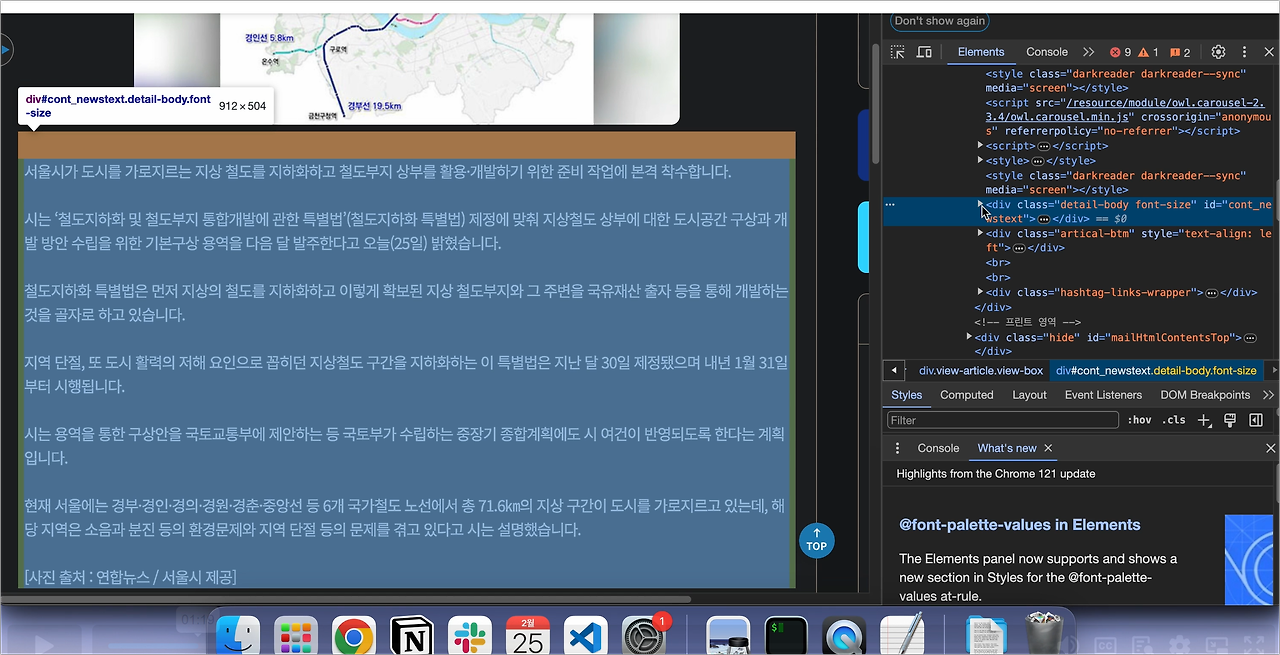
개발자 모드 F12를 통한 요소 분석
타이틀 부분은 h4로 싸여 있고 class는 "headline-title"임을 확인할 수 있습니다. 본문 부분은 "detail-body font-size"라는 클래스로 되어있음을 확인할 수 있습니다. 개발자 모드에서 접근한 뒤, 화살표 버튼을 통해 내가 원하는 요소에 대한 정보를 쉽게 얻을 수 있습니다. < br > 태그는 엔터 기능에 해당합니다.
라이브러리 호출
기본적인 라이브러리들을 호출하기 위하여 아래 코드를 실행합니다.
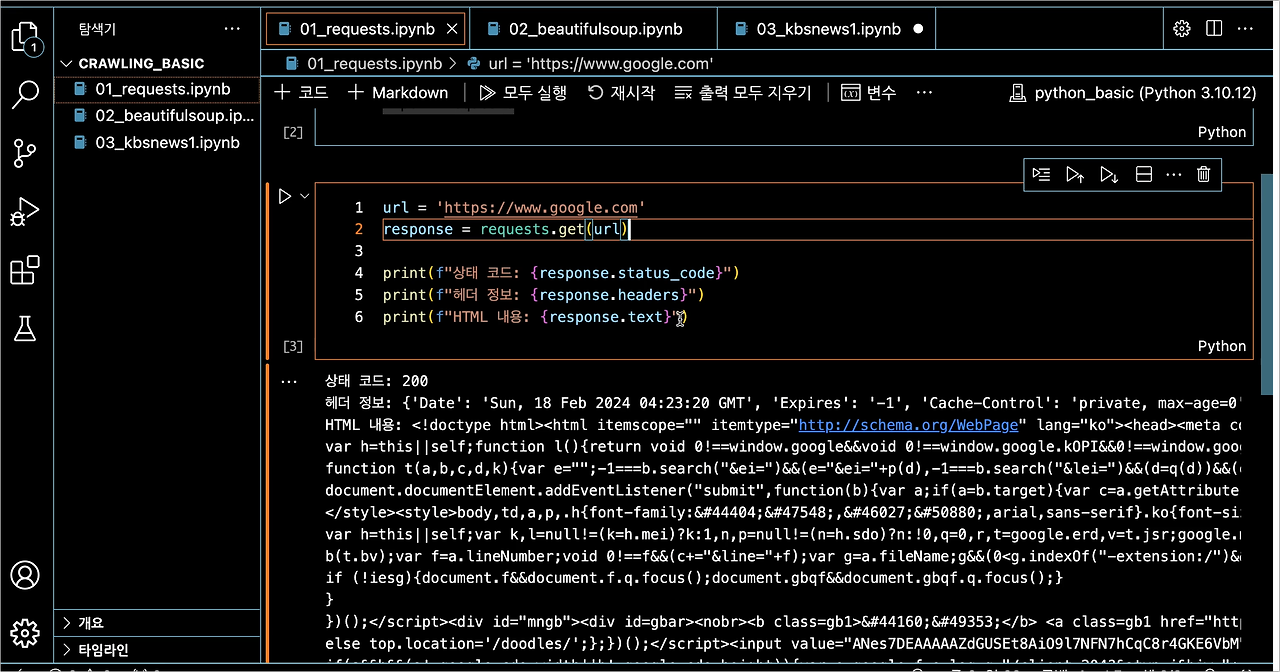
import requests
from bs4 import BeautifulSoup
위에서 호출한 requests 라이브러리를 통하여 url의 텍스트 정보를 가져올 수 있습니다.