[웹 크롤링] 메타코드 강의 후기 - "3강 예매 가능한 기차표 찾기 프로젝트"
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
코레일 예약 페이지 주소는 아래와 같습니다.
https://www.letskorail.com/ebizprd/EbizPrdTicketPr21111_i1.do
레츠코레일 LetsKorail
한국철도공사, 레츠코레일, 승차권 예매, 기차여행상품, 운행정보 안내
www.letskorail.com
url을 복사합니다.

미래 시점의 데이터를 사용할 것이며, 2 페이지 정도 넘어간 다음에 url을 복사합니다.
url = 'https://www.letskorail.com/ebizprd/EbizPrdTicketPr21111_i1.do?&txtGoAbrdDt=20240417&txtGoHour=093200&selGoYear=2024&selGoMonth=04&selGoDay=17&selGoHour=00&txtGoPage=2&txtGoStartCode=0001&txtGoStart=%EC%84%9C%EC%9A%B8&txtGoEndCode=0020&txtGoEnd=%EB%B6%80%EC%82%B0&selGoTrain=05&selGoRoom=&selGoRoom1=&txtGoTrnNo=&useSeatFlg=&useServiceFlg=&selGoSeat=&selGoService=&txtPnrNo=&hidRsvChgNo=&hidStlFlg=&radJobId=1&SeandYo=&hidRsvTpCd=03&selGoSeat1=015&selGoSeat2=&txtPsgCnt1=1&txtPsgCnt2=0&txtMenuId=11&txtPsgFlg_1=1&txtPsgFlg_2=0&txtPsgFlg_3=0&txtPsgFlg_4=0&txtPsgFlg_5=0&txtPsgFlg_8=&chkCpn=N&txtSeatAttCd_4=015&txtSeatAttCd_3=000&txtSeatAttCd_2=000&txtGoStartCode2=&txtGoEndCode2=&hidDiscount=&hidEasyTalk=&adjcCheckYn=N'
아래 코드를 실행함으로써, 본격적인 데이터를 탐색하기 전에 필수 라이브러리들인
BeautifulSoup, selenium, ChromeDriverManager, WebdriverWait 라이브러리 등을 불러옵니다.
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
아래 코드를 통하여, Selenium 웹 드라이버를 실행하는 과정을 수행합니다.
# Selenium 웹 드라이버 실행
driver = webdriver.Chrome(service = service)
driver.get(url)
wait = WebDriverWait(driver, 10)
테이블 정보를 담는 데이터프레임을 생성합니다.
리스트 구조를 활용하여 for문을 돌면서 각 tr의 td 데이터를 담는 데이터프레임을 생성합니다.
컬럼 이름들은 다음과 같습니다.
columns = [
'구분', '열차번호', '출발시각', '도착시각', '특실/우등실', '일반실', '유아',
'자유석/입석', '인터넷특가(멤버십혜택)', '예약대기', '정차역(경유)', '차량유형/편성정보', '운임요금', '소요시간']
아래와 같이 tr 안의 td에 들어있는 값들을 하나씩 리스트에 추가하는 코드를 작성합니다.
# 데이터를 저장할 빈 리스트 생성
data_rows = []
# table_contents의 각 tr 태그(행)에 대해 반복하면서 ,td 데이터를 컬럼에 담는다.
for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# 데이터를 행으로 추가
data_rows.append(data)
마지막 코드를 통하여 데이터프레임 구조로 저장합니다.
df = pd.DataFrame(data_rows, columns = columns)
df
현재 이미지 태그의 값들은 데이터 프레임에 담기지 않은 모습을 보인다.
위에서와 마찬가지로 for문 구조를 작성하는데, 이번에는 td.find('img') 코드를 추가하여,
위에서 만든 데이터프레임에 빈 칸이 생기는 경우가 없도록 할 것입니다.
# table_contents의 각 tr 태그(행)에 대해 반복하면서, td 데이터를 컬럼에 담아준다.
for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
# td 안에 있는 im 태그가 있는지 확인, alt 속성 추출
img_tag = td.find('img')
# img_tag가 존재하면
if img_tag:
text = img_tag.get("alt", "")
else:
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# data, 즉 방금까지 td 태그들이 쌓인 data 리스트에 url도 하나 더 추가
data.append(url)
# 데이터를 행으로 추가
data_rows.append(data)
"if img_tag" 조건문을 추가하고 img 태그가 있는 경우에는 "img_tag.get("alt", "")" 과정이 수행되도록 합니다.
그 외의 경우에는 위에서 진행한 대로 "td.get_text(strip=True)" 과정이 진행되도록 합니다.
다음 버튼 활용
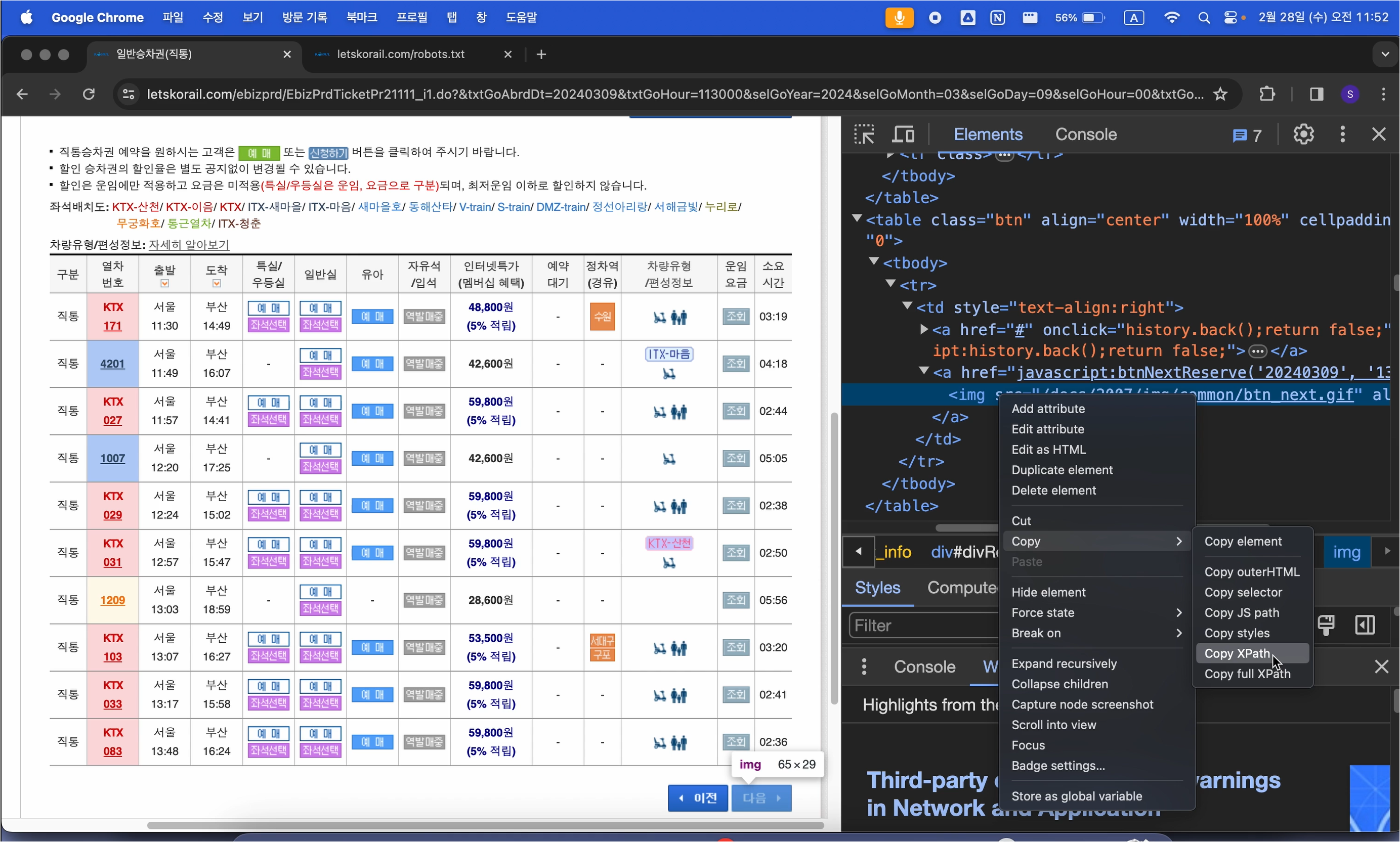
원하는 위치에 대하여 Copy XPath를 진행합니다.
복사된 XPath는 "//*[@id="divResult"]/table[2]/tbody/tr/td/a[2]/img" 형태입니다.
#'다음' 버튼 찾아서 클릭
try:
next_button = driver.find_element(By.XPATH, '//*[@id="divResult"]/table[2]/tbody/tr/td/a[2]') # copy XPATH
except: #이전 버튼이 없어서 위치가 2번째가 아니라 1번째 a태그로 변경된
next_button = driver.find_element(By.XPATH, '//*[@id="divResult"]/table[2]/tbody/tr/td/a[1]') # copy XPATH
next_button.click()
time.sleep(2)
except 문에 적혀있듯이 다음 버튼을 클릭하여 넘어가면 그 이후에는 [2] 부분을 [1]로 변경하여 동작히 수행되도록 만들어 줍니다.
다음 버튼을 클릭하면 이전 버튼이 사라지기 때문에 이러한 XPath 경로의 변화가 생깁니다.
중복제거

drop_duplicates 함수를 사용하여 데이터프레임 상에서 중복되는 요소를 제거합니다.
subset 안에는 중복을 제거할 열을 선택합니다. 이번 경우에는 "출발시각"이 같은 경우를 중복으로 선택하였습니다.
뒤에서 keep = 'first' 옵션을 활용하여 중복되는 요소 중에서 가장 처음에 나온 행만 남기도록 합니다.
데이터 처리가 완료된 이후에는 df.head(20)을 통해 올바르게 작업이 수행되었는지 확인합니다.
예약 가능한 일반실 찾기
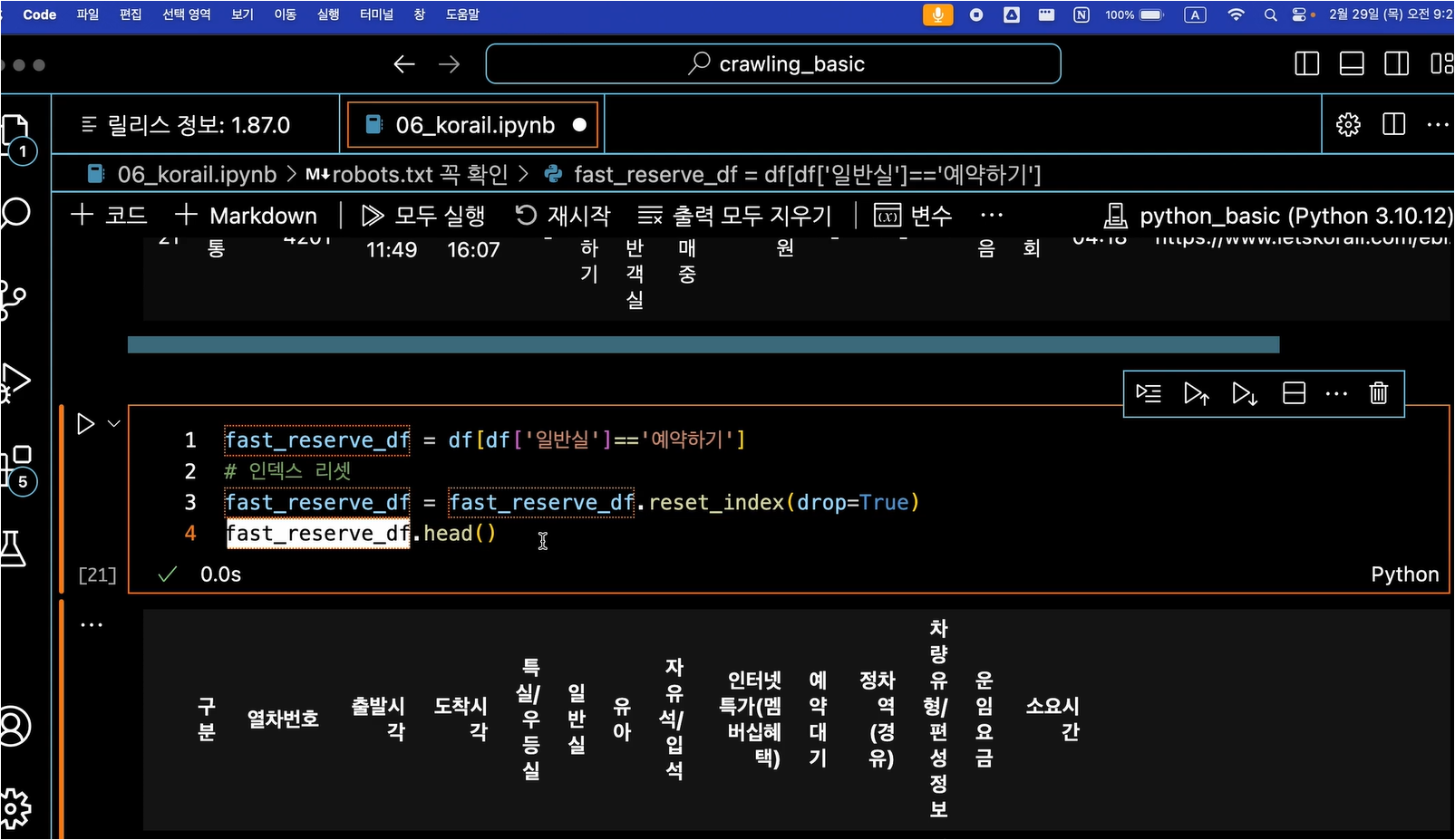
" df[ df['일반실'] == '예약하기' ] " 코드를 수행함으로써 일반실 중에서 예약이 가능한 경우만 출력하도록 합니다.
" reset_index(drop=True) "를 진행하는 이유는 원하는 값들만 가져오면서 인덱스 값들이 0, 1, 2, 4 등으로 변하기 때문입니다.
옵션은 drop=True를 넣어줌으로써 새로운 인덱스 열을 추가하지는 않고, 기존 인덱스 열의 숫자를 0, 1, 2, 3 순서로 바꾸어줍니다.
확인하는 과정은 head() 함수를 사용하여 진행합니다.
'Crawling - 메타코드' 카테고리의 다른 글
| [웹 크롤링] 메타코드 강의 후기 - "4강 관광 상품 리뷰 크롤링 및 분석 프로젝트(3), 완강 후기" (0) | 2024.04.28 |
|---|---|
| [웹 크롤링] 메타코드 강의 후기 - "4강 관광 상품 리뷰 크롤링 및 분석 프로젝트(2)" (0) | 2024.04.25 |
| [웹 크롤링] 메타코드 강의 후기 - "4강 관광 상품 리뷰 크롤링 및 분석 프로젝트(1)" (0) | 2024.04.20 |
| 메타코드 강의 후기_2강 : 뉴스 크롤링 자동화 프로젝트 - "크롤링이 안될 때", "Selenium, WebDriver 이용 크롤링" (0) | 2024.04.13 |
| 메타코드 - [ 효율적 뉴스 정보 수집 ] 메타코드 강의 후기 ( 2강 : 뉴스 크롤링 자동화 프로젝트 ) (1) | 2024.04.12 |