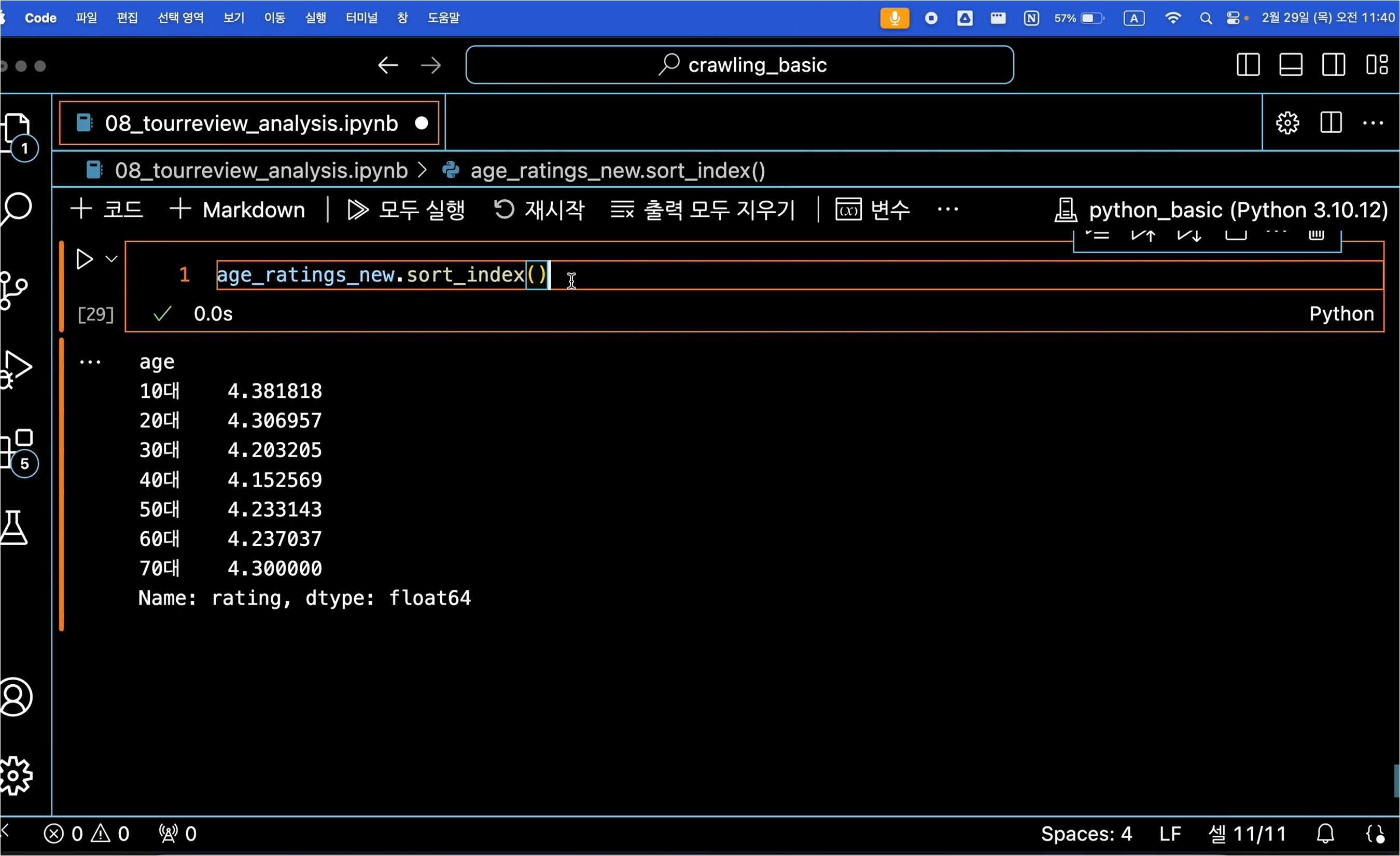
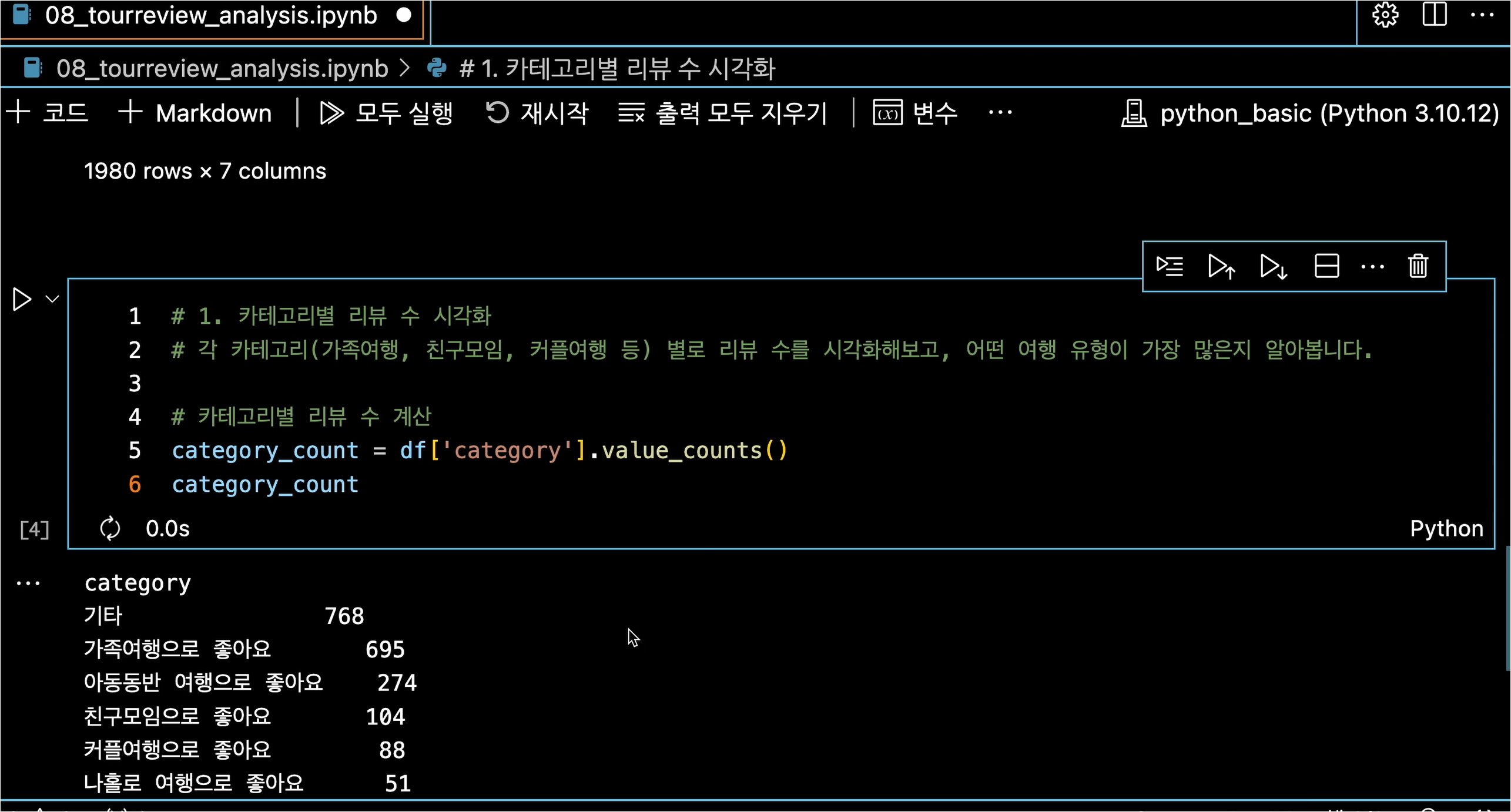
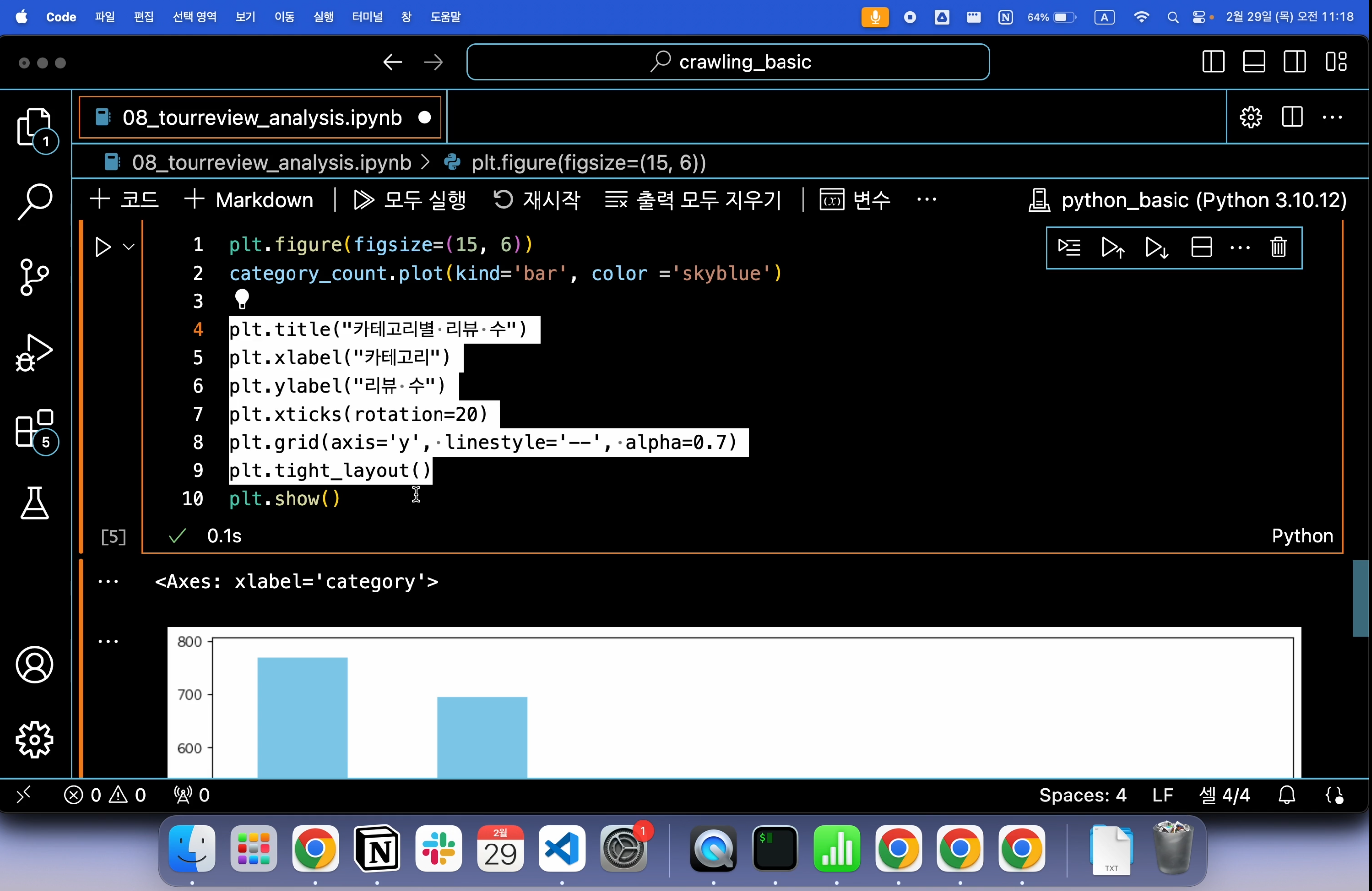
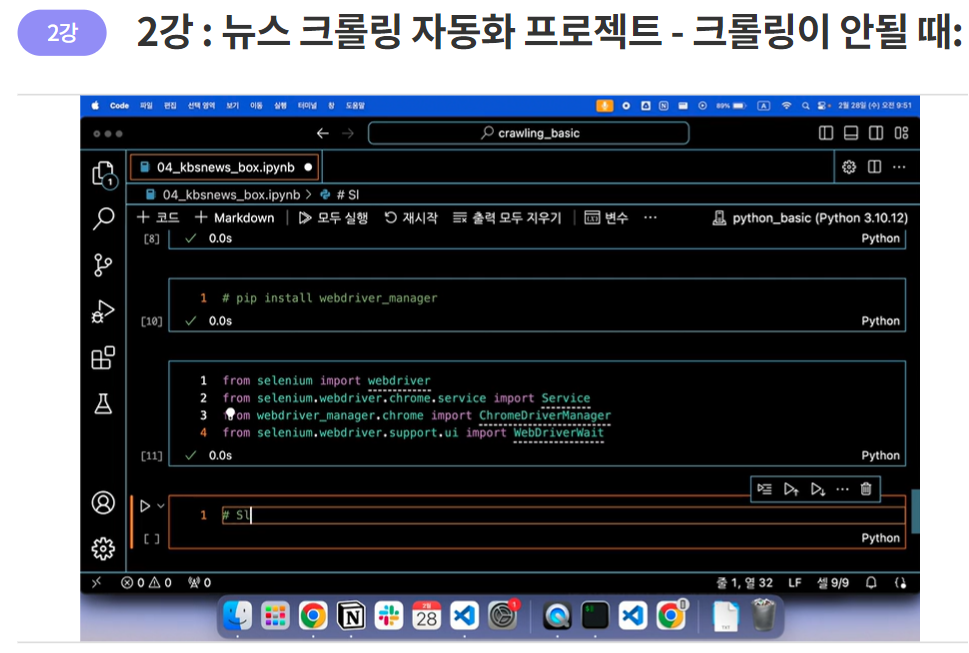
BeautifulSoup, selenium, ChromeDriverManager, WebdriverWait 라이브러리 등을 불러옵니다.
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
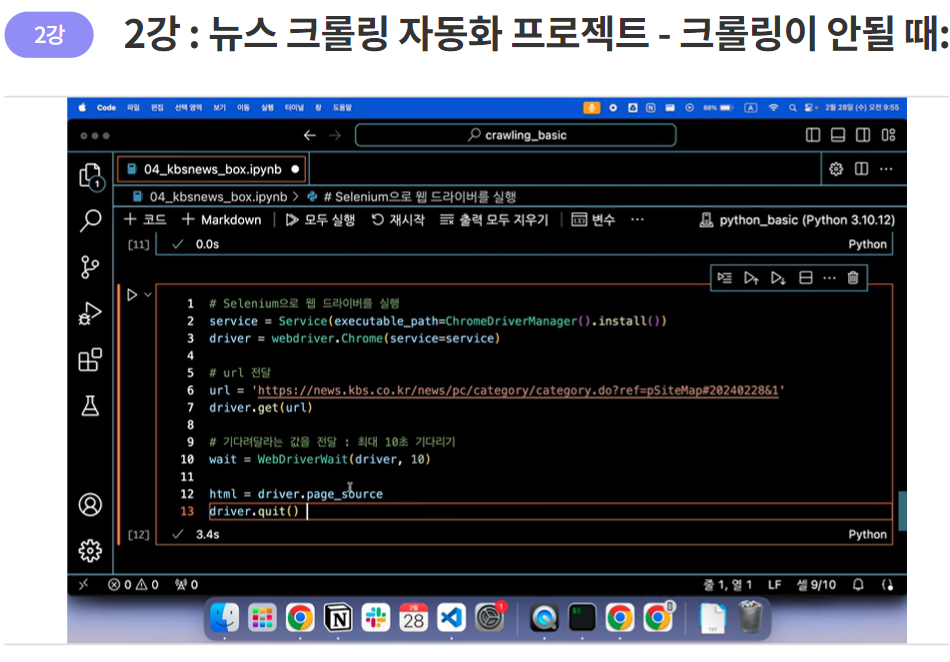
아래 코드를 통하여, Selenium 웹 드라이버를 실행하는 과정을 수행합니다.
# Selenium 웹 드라이버 실행
driver = webdriver.Chrome(service = service)
driver.get(url)
wait = WebDriverWait(driver, 10)
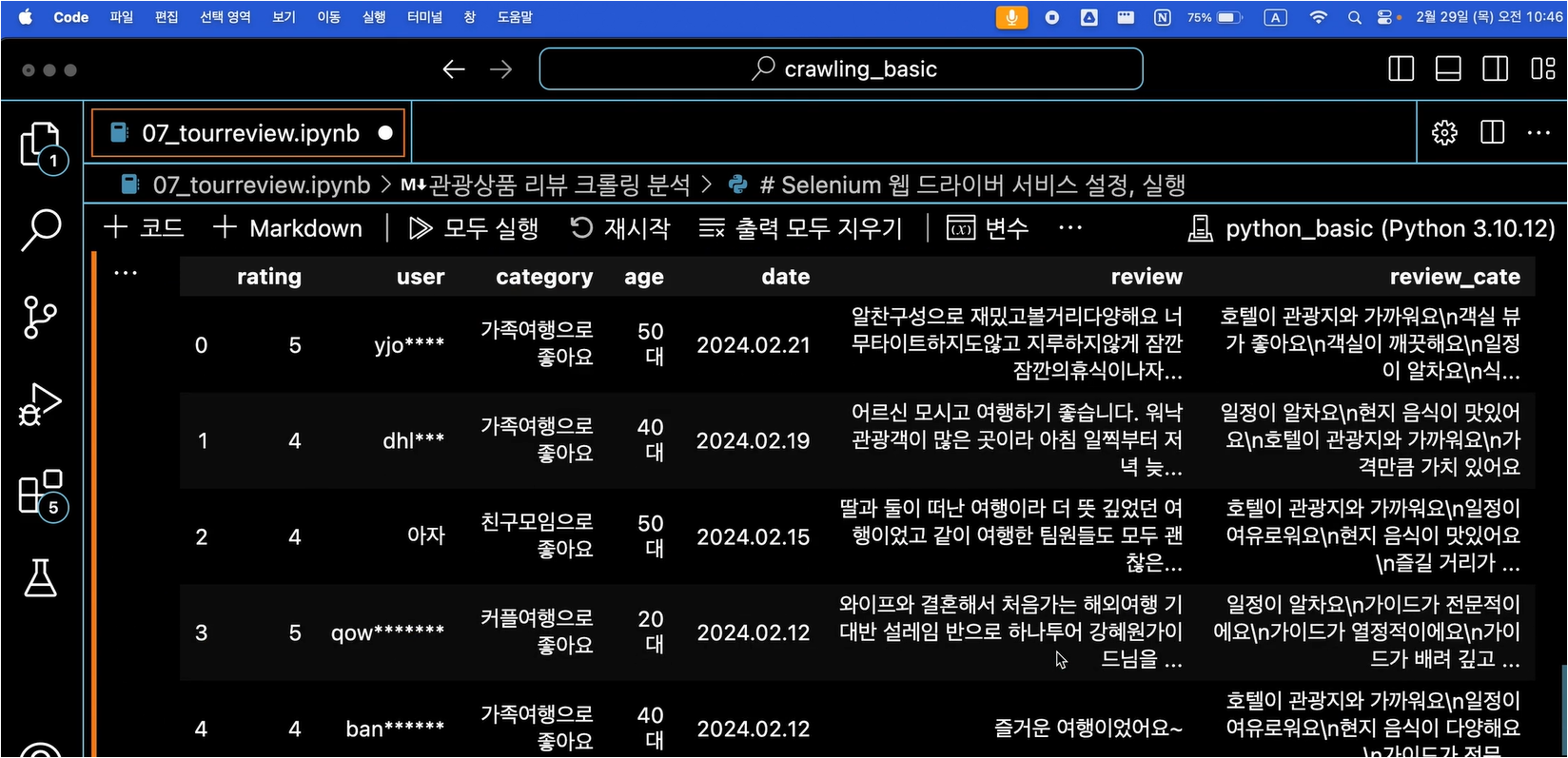
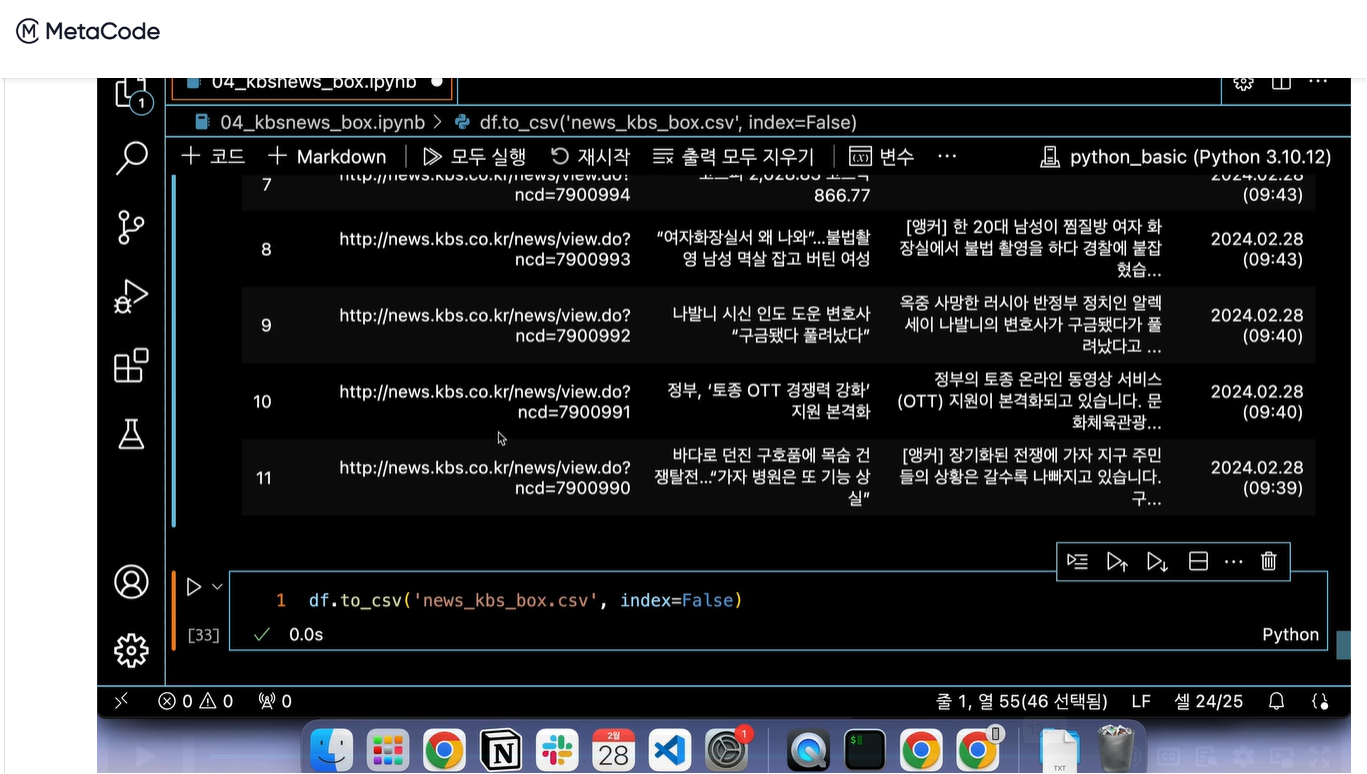
테이블 정보를 담는 데이터프레임을 생성합니다.
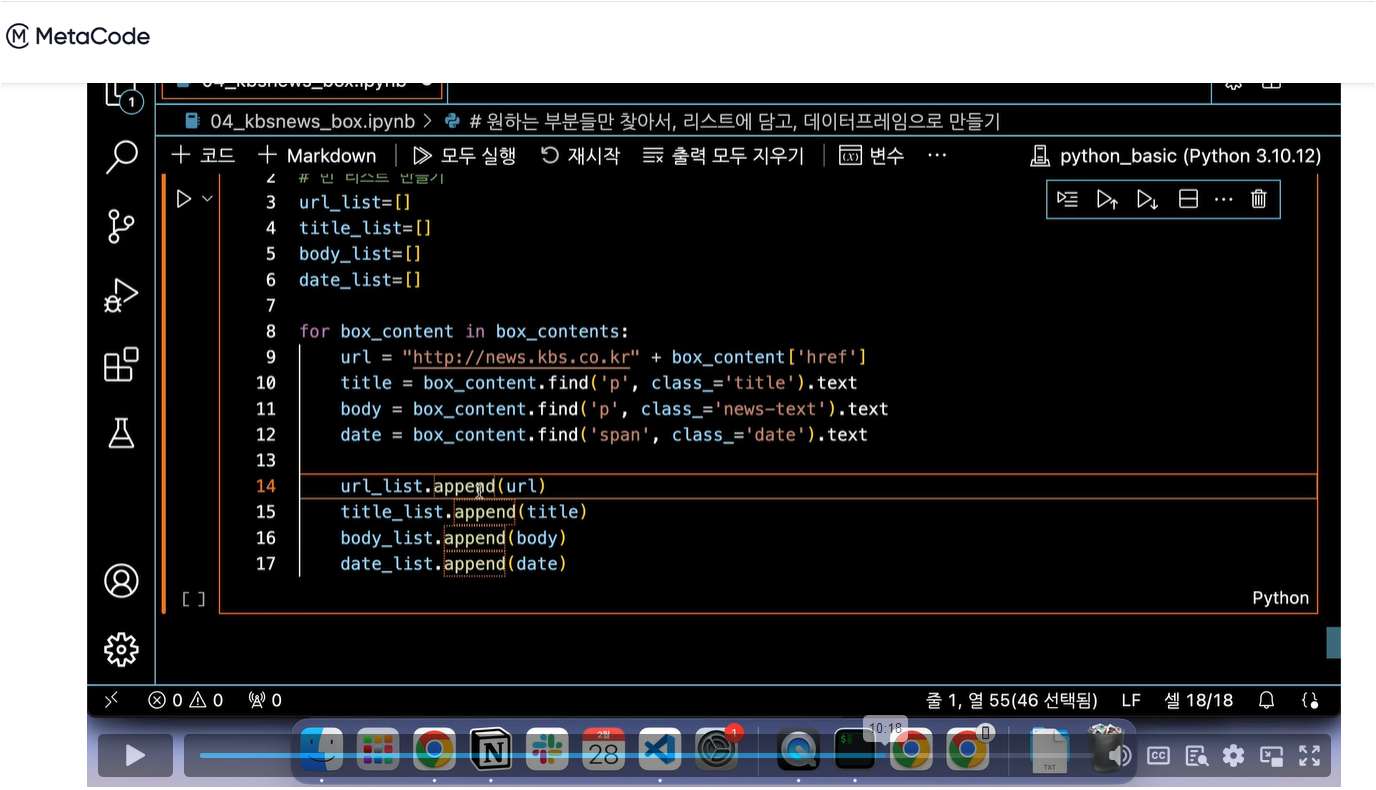
리스트 구조를 활용하여 for문을 돌면서 각 tr의 td 데이터를 담는 데이터프레임을 생성합니다.
아래와 같이 tr 안의 td에 들어있는 값들을 하나씩 리스트에 추가하는 코드를 작성합니다.
# 데이터를 저장할 빈 리스트 생성
data_rows = []
# table_contents의 각 tr 태그(행)에 대해 반복하면서 ,td 데이터를 컬럼에 담는다.
for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# 데이터를 행으로 추가
data_rows.append(data)
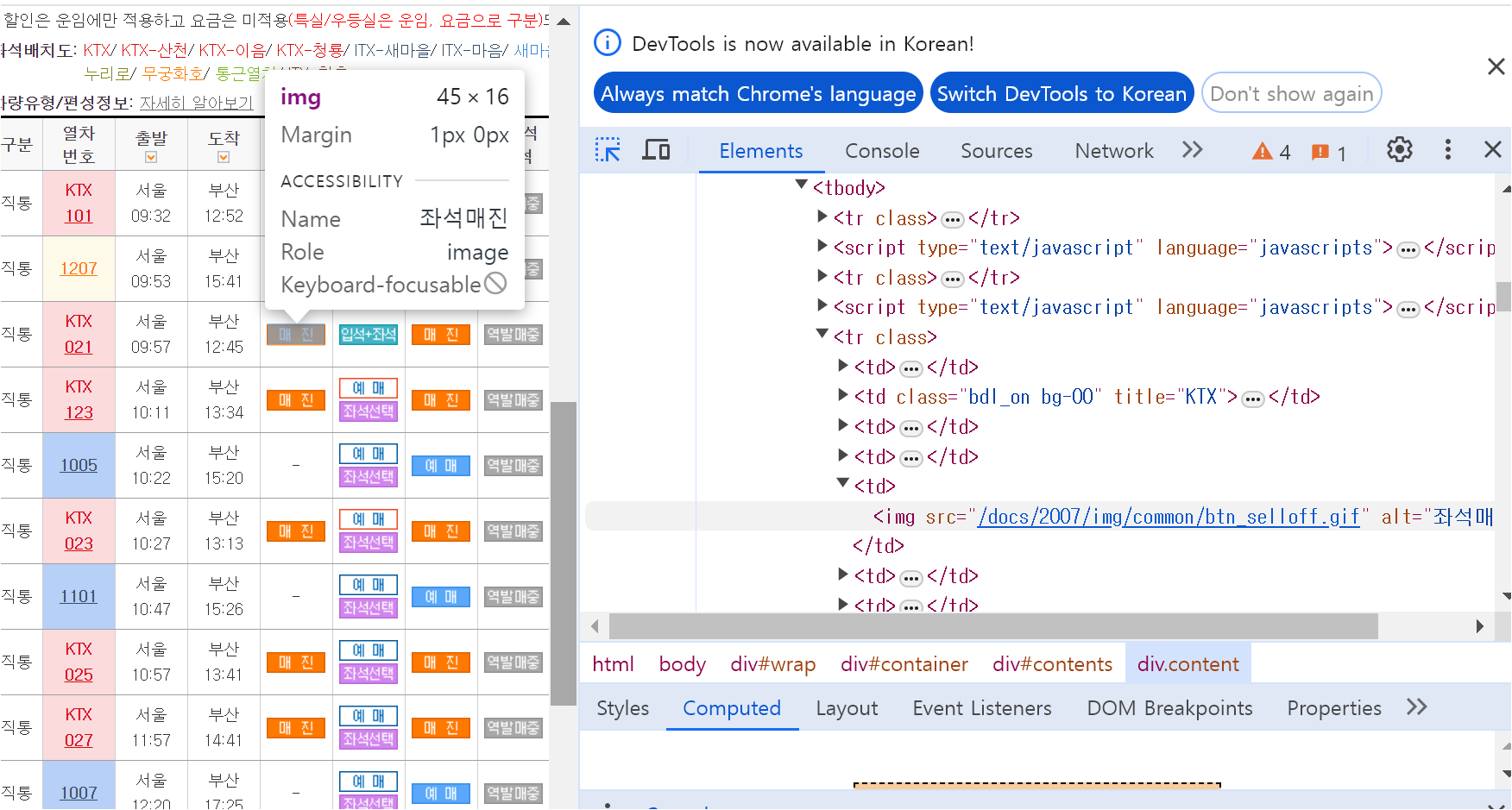
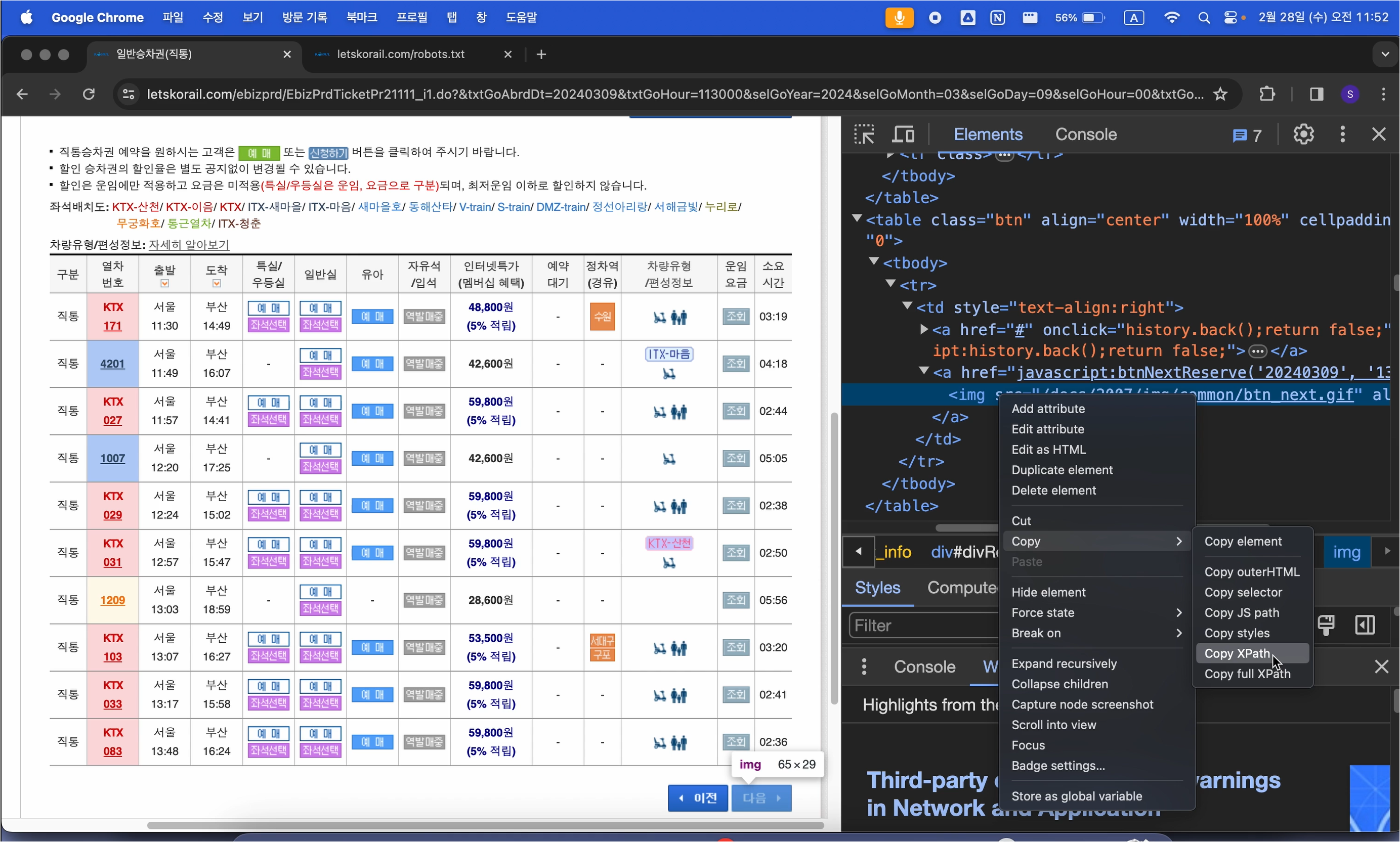
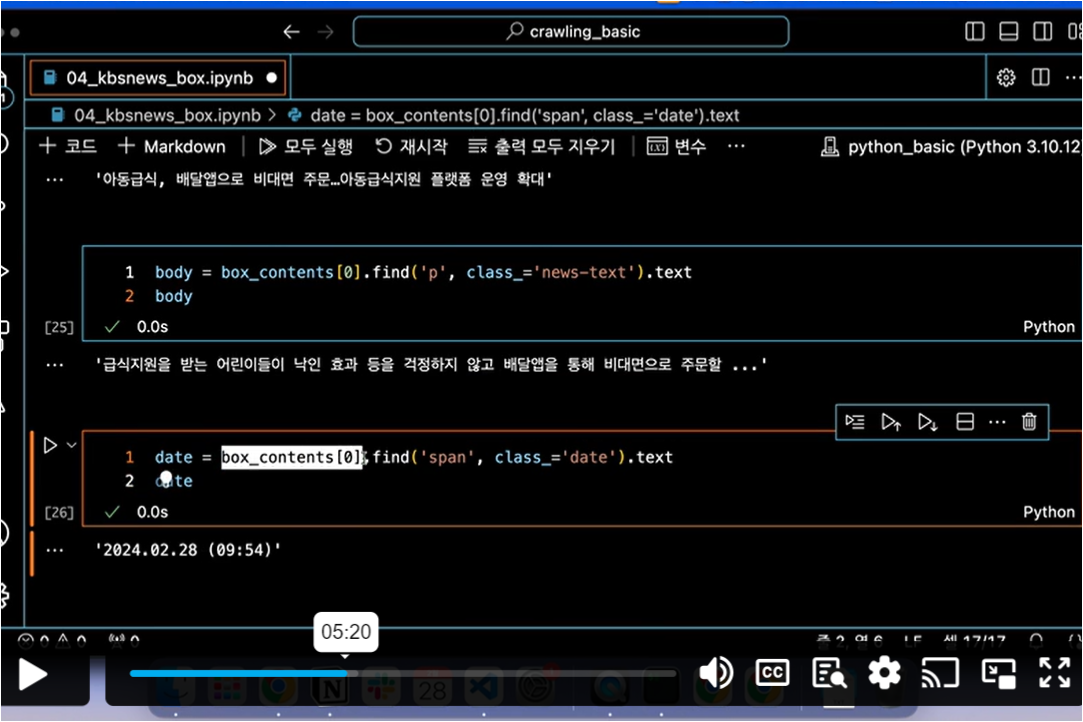
위에서와 마찬가지로 for문 구조를 작성하는데, 이번에는 td.find('img') 코드를 추가하여,
위에서 만든 데이터프레임에 빈 칸이 생기는 경우가 없도록 할 것입니다.
# table_contents의 각 tr 태그(행)에 대해 반복하면서, td 데이터를 컬럼에 담아준다.
for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
# td 안에 있는 im 태그가 있는지 확인, alt 속성 추출
img_tag = td.find('img')
# img_tag가 존재하면
if img_tag:
text = img_tag.get("alt", "")
else:
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# data, 즉 방금까지 td 태그들이 쌓인 data 리스트에 url도 하나 더 추가
data.append(url)
# 데이터를 행으로 추가
data_rows.append(data)
"if img_tag" 조건문을 추가하고 img 태그가 있는 경우에는 "img_tag.get("alt", "")" 과정이 수행되도록 합니다.
그 외의 경우에는 위에서 진행한 대로 "td.get_text(strip=True)" 과정이 진행되도록 합니다.
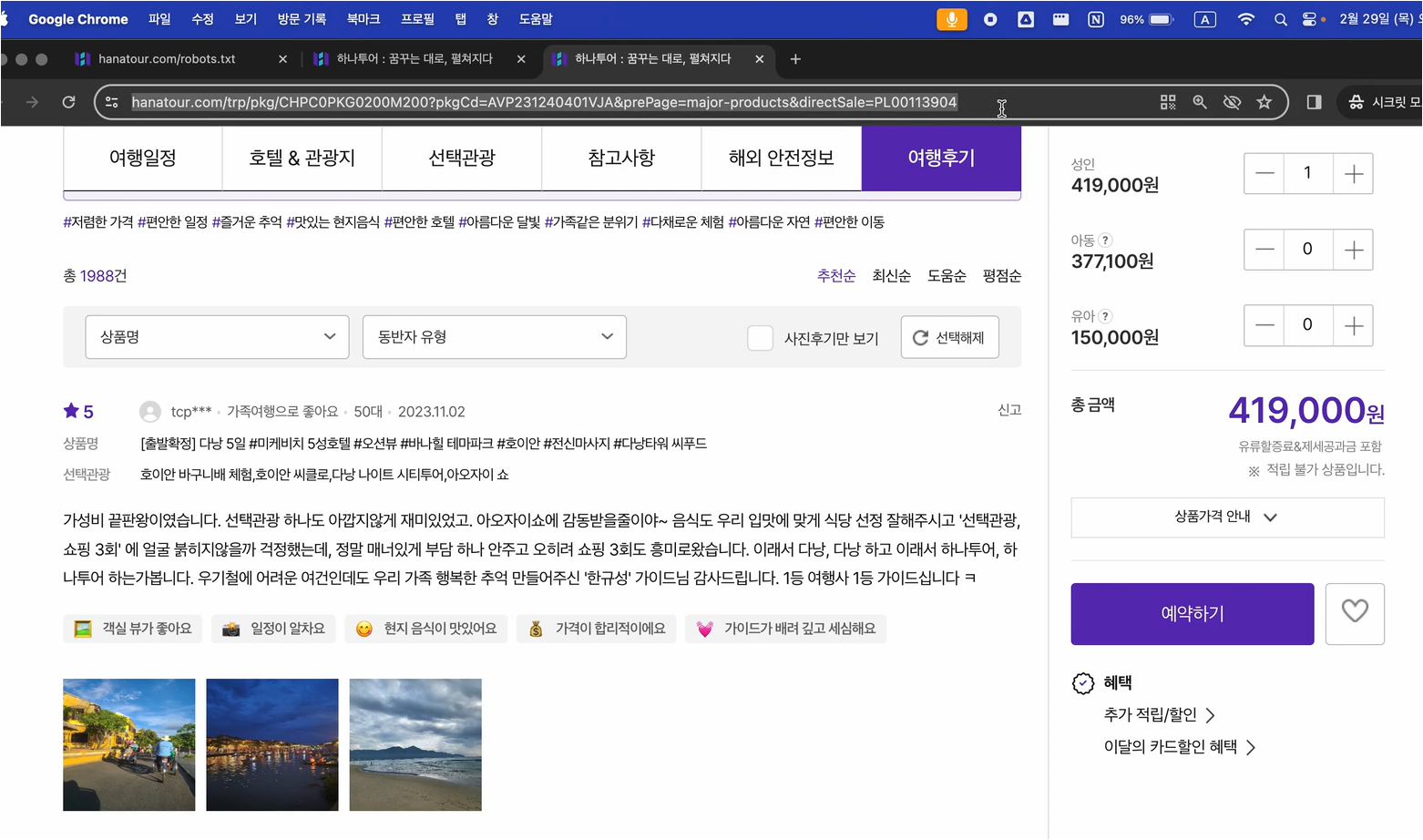
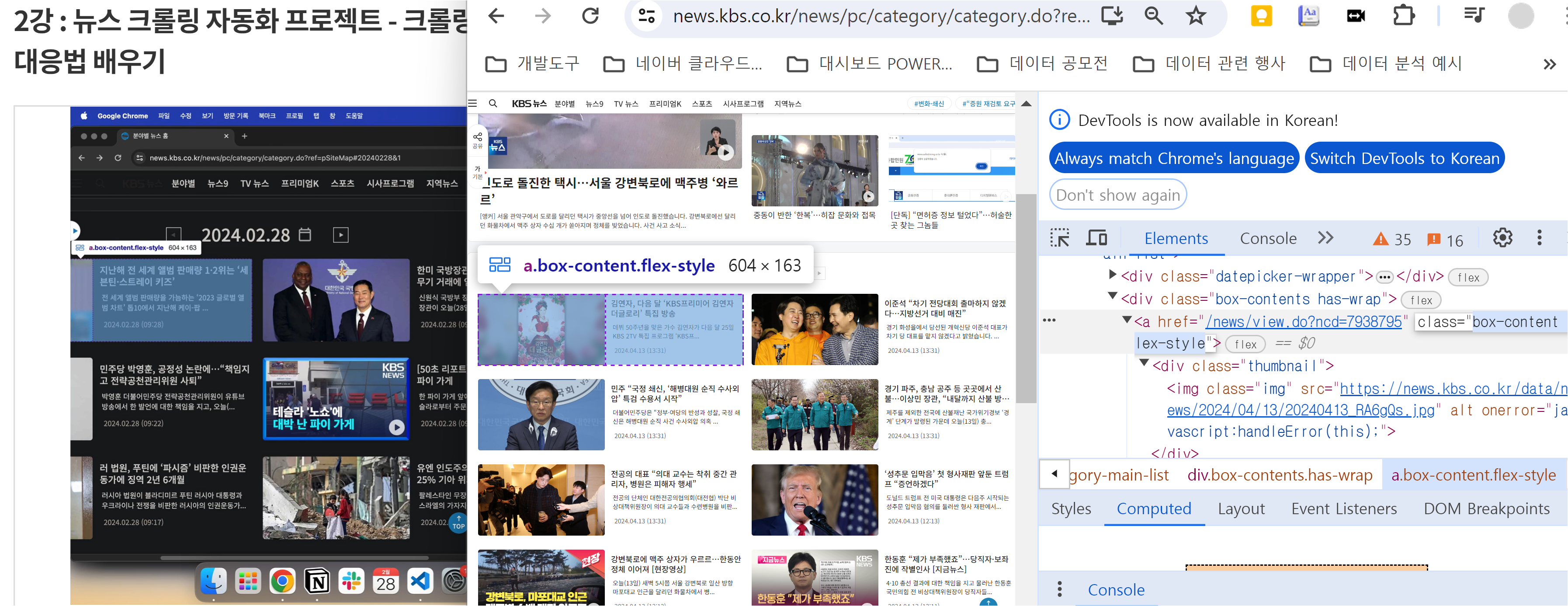
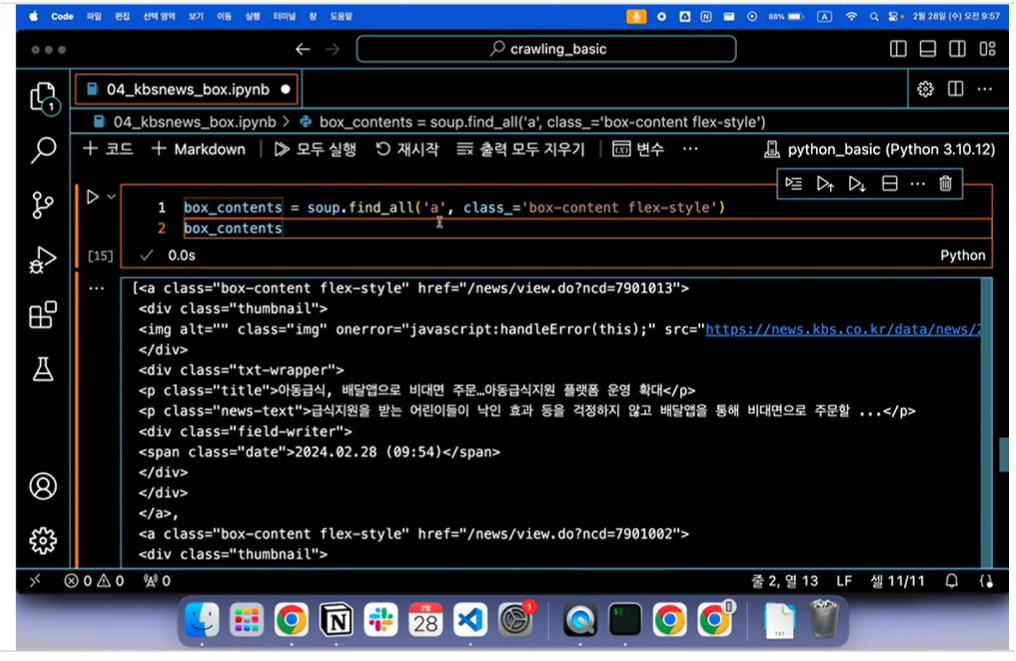
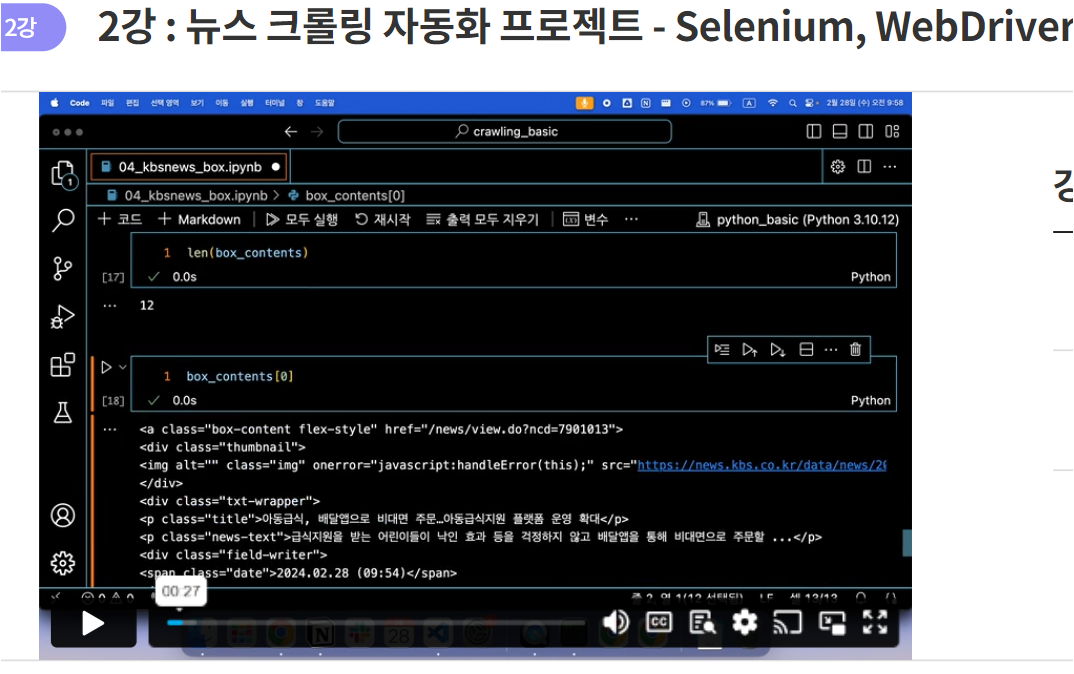
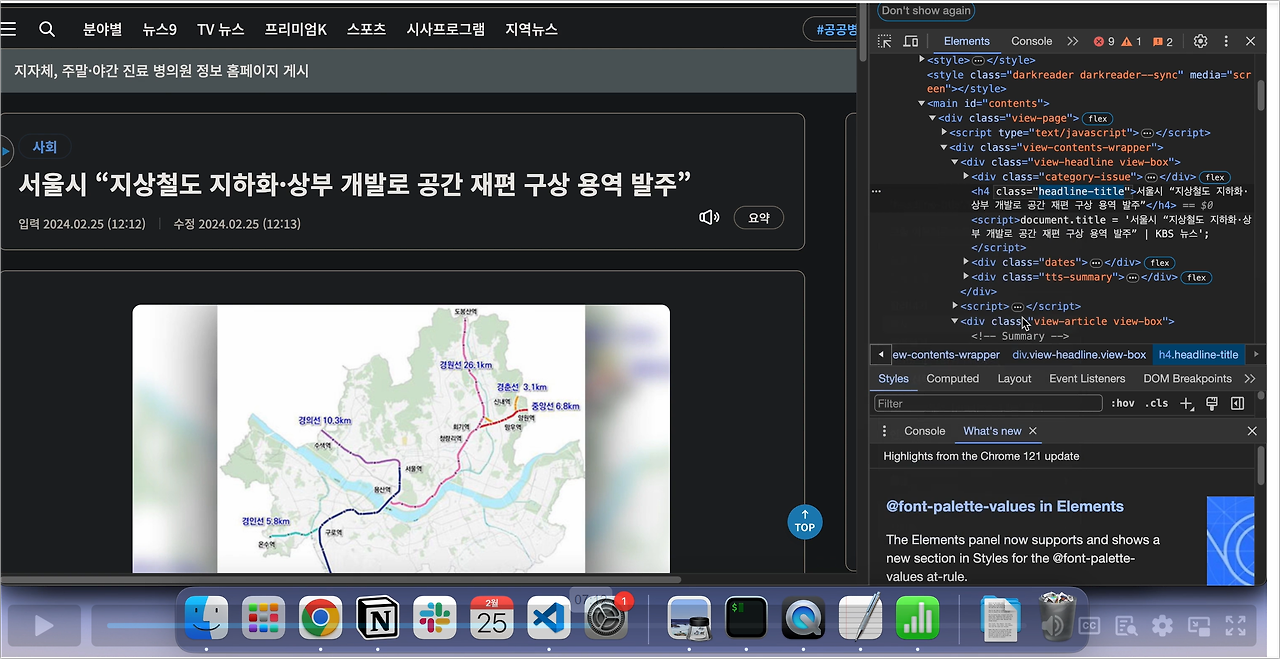
KBS 뉴스탭에서 전체 카테고리를 선택하고 일자별 뉴스 항목에 접근합니다. 먼저, 한 항목을 선택하여 페이지로 이동합니다. F12 버튼을 통해 개발자 모드에 접근하면 각 element들에 대한 자세한 정보를 얻을 수 있으며 이는 뒤에서 바로 진행할 것입니다.
하나의 요소에서 정보를 수집하는 것으로 시작하여, 추후에 여러 뉴스에서 정보를 수집하는 실습을 진행할 것입니다.
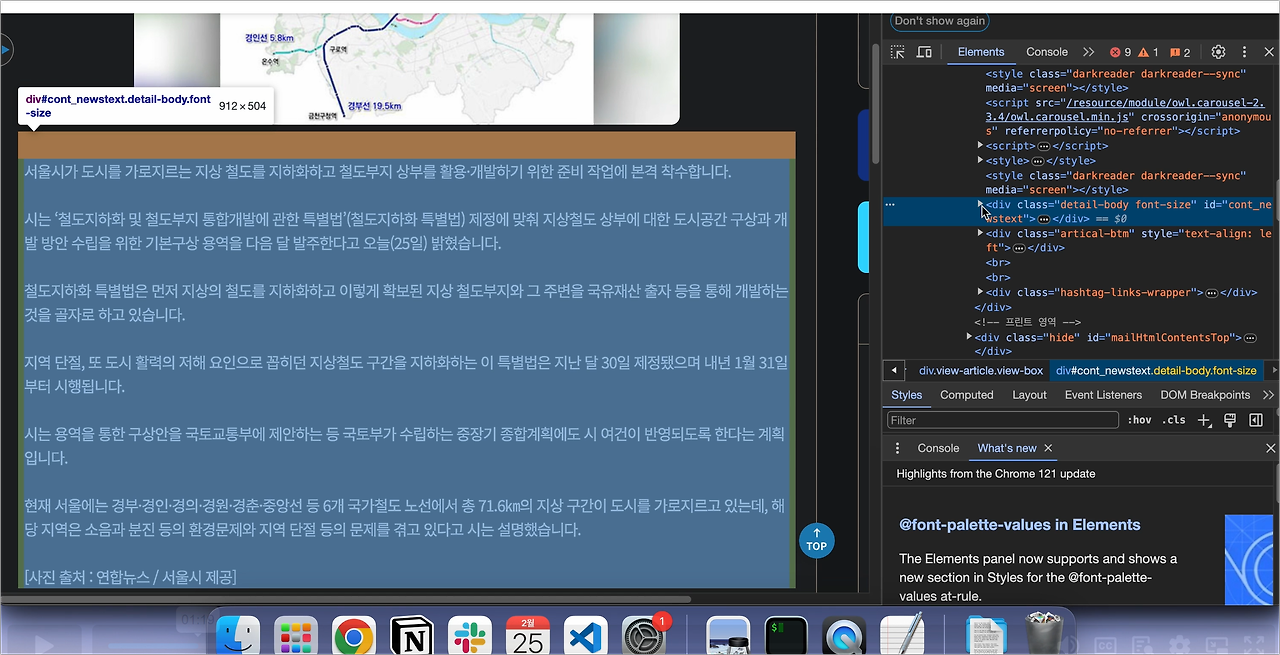
개발자 모드 F12를 통한 요소 분석
타이틀 부분은 h4로 싸여 있고 class는 "headline-title"임을 확인할 수 있습니다. 본문 부분은 "detail-body font-size"라는 클래스로 되어있음을 확인할 수 있습니다. 개발자 모드에서 접근한 뒤, 화살표 버튼을 통해 내가 원하는 요소에 대한 정보를 쉽게 얻을 수 있습니다. < br > 태그는 엔터 기능에 해당합니다.
라이브러리 호출
기본적인 라이브러리들을 호출하기 위하여 아래 코드를 실행합니다.
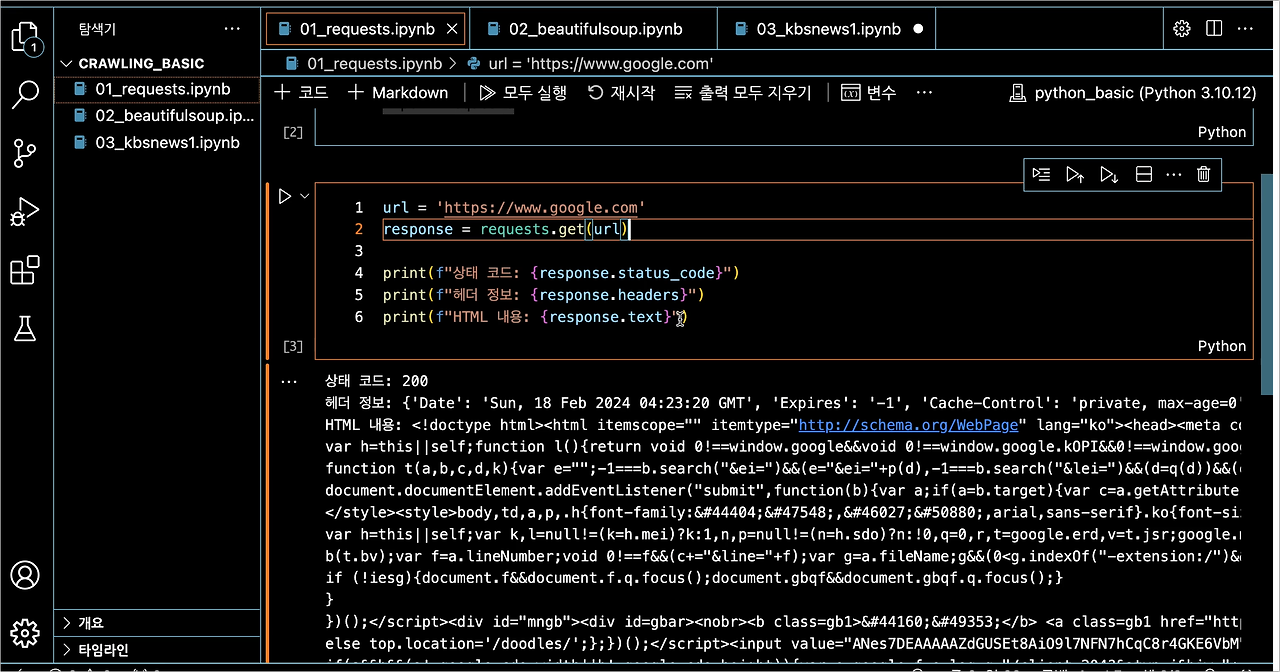
import requests
from bs4 import BeautifulSoup
위에서 호출한 requests 라이브러리를 통하여 url의 텍스트 정보를 가져올 수 있습니다.
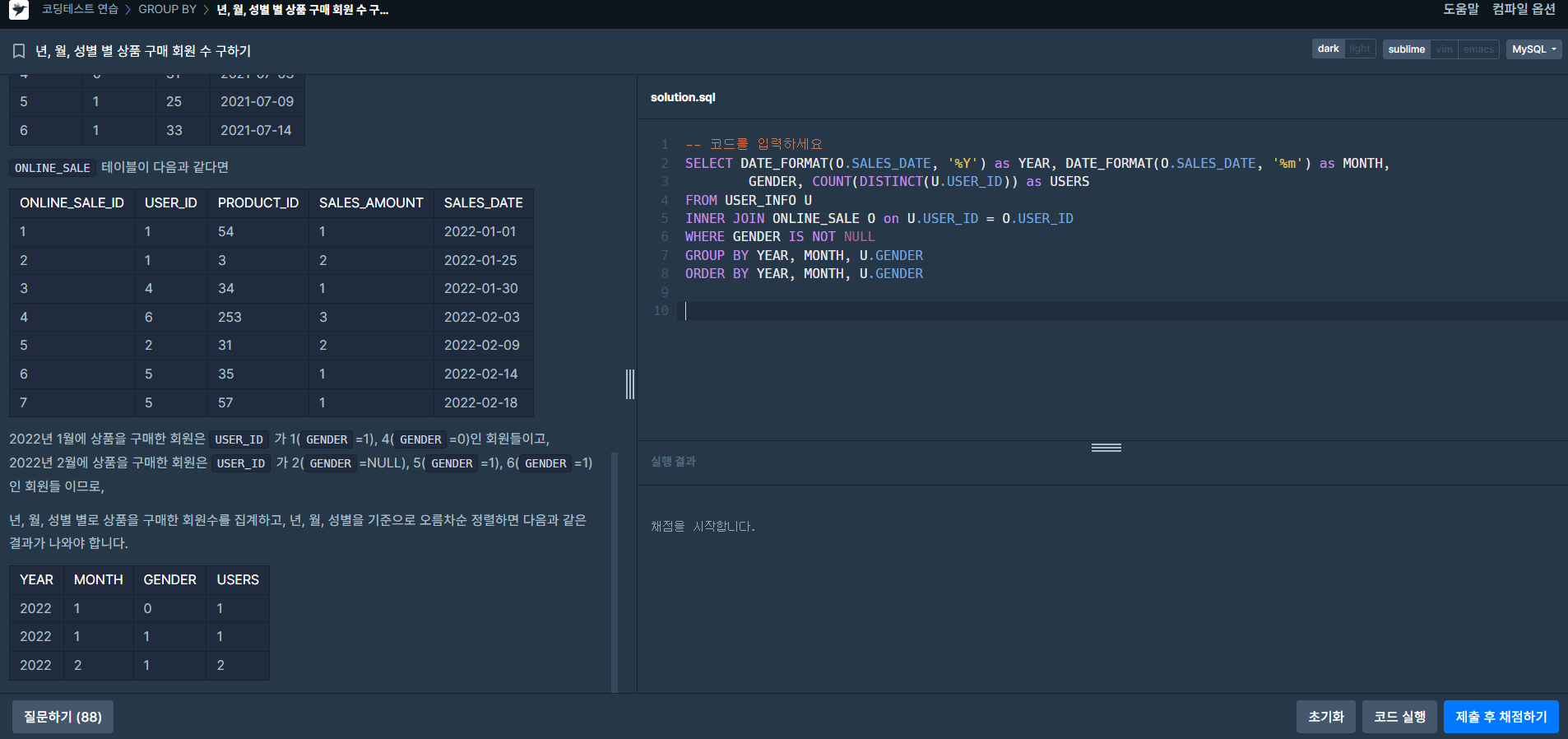
-- 코드를 입력하세요
SELECT DATE_FORMAT(O.SALES_DATE, '%Y') as YEAR, DATE_FORMAT(O.SALES_DATE, '%m') as MONTH,
GENDER, COUNT(DISTINCT(U.USER_ID)) as USERS
FROM USER_INFO U
INNER JOIN ONLINE_SALE O on U.USER_ID = O.USER_ID
WHERE GENDER IS NOT NULL
GROUP BY YEAR, MONTH, U.GENDER
ORDER BY YEAR, MONTH, U.GENDER
-- 코드를 입력하세요
SELECT I.ANIMAL_ID, I.NAME
FROM ANIMAL_INS I
INNER JOIN ANIMAL_OUTS O on I.ANIMAL_ID = O.ANIMAL_ID
ORDER BY DATEDIFF(O.DATETIME, I.DATETIME) DESC
LIMIT 2
-- 코드를 입력하세요
# "1월 2일" - "1월 1일"인 경우 1일이 아닌 2일로 계산해야 한다.
SELECT CAR_ID, ROUND(AVG(DATEDIFF(END_DATE,START_DATE)+1),1) as AVERAGE_DURATION
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY
GROUP BY CAR_ID
HAVING AVG(DATEDIFF(END_DATE, START_DATE)+1) >= 7
ORDER BY AVERAGE_DURATION DESC, CAR_ID DESC
-- 코드를 입력하세요
SELECT I.INGREDIENT_TYPE, SUM(F.TOTAL_ORDER) as TOTAL_ORDER
FROM FIRST_HALF F
INNER JOIN ICECREAM_INFO I ON F.FLAVOR = I.FLAVOR
GROUP BY INGREDIENT_TYPE
-- 코드를 입력하세요
SELECT A.APNT_NO, P.PT_NAME, A.PT_NO, D.MCDP_CD, D.DR_NAME, A.APNT_YMD
FROM PATIENT P
LEFT JOIN APPOINTMENT A ON P.PT_NO = A.PT_NO
LEFT JOIN DOCTOR D on D.DR_ID = A.MDDR_ID
WHERE (A.APNT_CNCL_YN = 'N')
AND (DATE(A.APNT_YMD) = '2022-04-13')
AND (D.MCDP_CD = 'CS')
ORDER BY A.APNT_YMD
우리 조는 어린이 식단 생성 및 이에 대한 영양 정보 제공과 이에 대한 분석 서비스를 제공할 것으로 정했다.
정보를 정리함에 있어서 CSV로 제공되는 파일 같은 경우에는 보다 빠르게 활용이 가능하여 편했는데, API를 통해 JSON으로 제공하는 파일의 경우 데이터를 얻어내는 데에 과정이 좀 더 필요하여 번거로웠다.
귀찮게 느껴지도 했지만, API를 통해 정보를 얻어내는 데에 익숙해지는 기회가 되었다.
인프라 구성도 작성
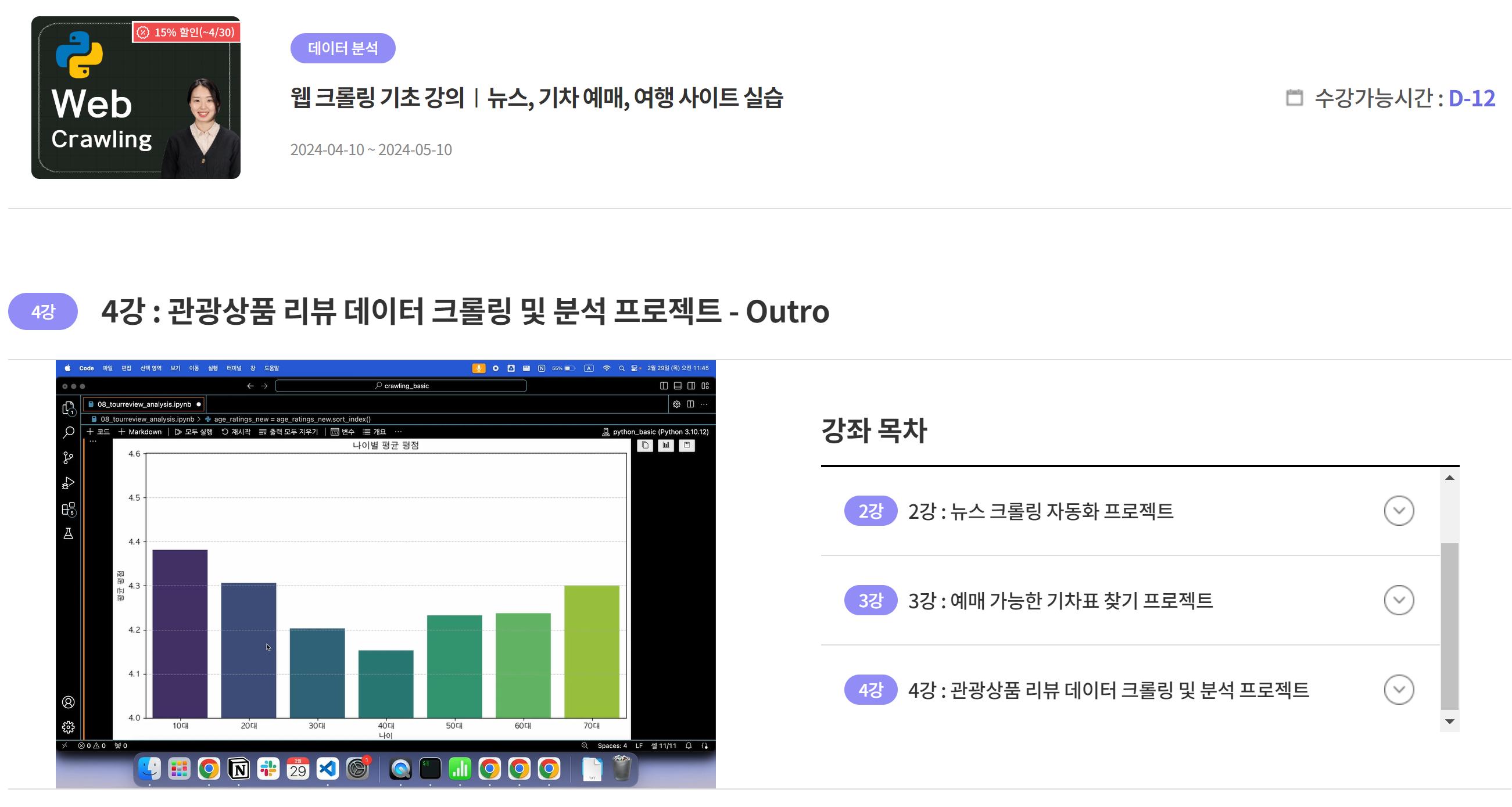
최종 산출물
나는 인프라 구성도를 작성하는 역할도 맡았는데, 이를 그리는 과정에서 처음에는 낯설기도 했다.
AWS의 경우에는, 수업 시간에 다뤄보기도 했고, 개인적으로 배우고 싶다는 마음이 있어서 강의 또한 찾아들었기 때문에 문제가 없었지만, KT 클라우드로 그려내야 했기 때문에 낯설기도 했지만 정보를 찾아보며 결국 그려내었고 기술 코칭 시간에 문제가 없다는 피드백을 받을 수 있었다.
2차 컨설팅
12.28(목)에는 2차 컨설팅을 받았다.
저번에 합격했던 자소서에 대한 피드백을 신청했는데, 합격 자소서라 피드백이 그렇게 많을까 싶었는데, 피드백을 받다보니 고칠 부분이 많았음을 배울 수 있었다.
자기소개서는 보면 볼수록 고쳐야 하는 부분을 찾게 되므로 입사 지원을 할 때는 미리 자기소개서를 작성해두고 제출 기간이 되기 전까지 꾸준히 다시 보며 수정할 부분을 찾는 것이 좋을 거 같다는 생각을 다시 한 번 하게 되었다.
얼마 남지 않은 빅프로젝트
처음 시작할 때만 해도 시간이 엄청 남을 것이라 생각했는데, 정신없이 맡은 역할을 수행하다보니 어느덧 빅프의 마지막 일정이 머지 않게 되었다.
빅프가 끝나면, 사실상 에이블스쿨 과정도 끝나는 셈이니 긴 여정이 끝나느라 성취감이 들기도 할 거 같지만, 한편으로는 본격적으로 취업 시장에 뛰어들어야 하니 두려움이 앞서기도 한다.
나의 경우에는 회사에 지원도 하겠지만 취업이 잘 되지 않을 경우에는, 대학원에도 지원을 해볼 생각이다.
대학원도 경쟁률이 높기 때문에 이 또한 철저하게 미리미리 준비해둘 것이다.
정보처리기사 준비
에이블스쿨을 이수하는 동안, ADsP와 SQLD 자격증을 취득했다.
비전공자로서 역량을 키우기 위해 24년도 1회에 시행하는 정보처리기사 시험에 응시할 계획을 세웠다.
데이터분석가 직무를 희망하는데, 저번 면접 때 SQL 지식이 크게 모자름을 느꼈다.
SQLD 자격증에서 배운 내용에 더해 정보처리기사 과목에 있는 SQL 내용을 공부하면, 이 부분을 개선할 수 있을 거라 생각했다.
자격증이 전부인 것은 아니지만, 이 자격증을 공부하는 과정에서 필요한 이론 지식들을 흡수할 수 있을 거라 생각하고 있다.
데이콘 수상 인증서 발급, 에이블스쿨을 하면서 느낀 역량 발전
이번에 DACON에서 열린 "데이터 분석 아이디어 경진대회 - 월간 데이콘"에서의 수상한 것에 대한 인증서가 발급되었다.
그렇게 대단하지는 않다고 느낄 수 있지만, 에이블스쿨을 통해 역량이 키워짐은 느낄 수 있는 기회였다.
에이블스쿨 과정이 데이터를 다루는 기술을 늘리는 데에도 어느 정도 도움이 되었음을 느꼈다.
다만, 교육에서 알려주는 내용에 그치지 않고 스스로 필요한 부분을 찾아보고 공부할 때에 진정으로 역량을 키울 수 있으니 꾸준히 공부하기로 다짐했다.
SELECT C.CAR_ID, C.CAR_TYPE, ROUND((C.DAILY_FEE * 30 * (1 - D.DISCOUNT_RATE / 100.0))) AS FEE
FROM CAR_RENTAL_COMPANY_CAR C
INNER JOIN CAR_RENTAL_COMPANY_DISCOUNT_PLAN D ON C.CAR_TYPE = D.CAR_TYPE AND D.DURATION_TYPE = '30일 이상'
### '세단','SUV' 조건에 속하면서 11월에 대여중인 CAR_ID가 11월에 대여 중인 그룹에는 속하지 않아야 한다. ###
WHERE C.CAR_TYPE IN ('세단', 'SUV')
AND C.CAR_ID NOT IN (
SELECT H.CAR_ID
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY H
WHERE (H.START_DATE <= '2022-11-30' AND H.END_DATE >= '2022-11-01')
)
GROUP BY C.CAR_ID
HAVING FEE >= 500000 AND FEE < 2000000
ORDER BY FEE DESC, C.CAR_TYPE, C.CAR_ID DESC;
-- 코드를 입력하세요
SELECT P.PRODUCT_CODE, SUM(O.SALES_AMOUNT) * P.PRICE as SALES
FROM PRODUCT P
INNER JOIN OFFLINE_SALE O on P.PRODUCT_ID = O.PRODUCT_ID
GROUP BY P.PRODUCT_ID
ORDER BY SALES DESC, P.PRODUCT_CODE
-- 코드를 입력하세요
SELECT CAR_TYPE,COUNT(CAR_ID) as CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS LIKE '%통풍시트%'
OR OPTIONS LIKE '%열선시트%'
OR OPTIONS LIKE '%가죽시트%'
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE
import re
# 주어진 메뉴 리스트
menu_list = [
'(우유제외)스크램블에그',
'고로케',
'카레고등어구이',
'콩가루배춧국',
'크림리조또(간식)',
'돼지고기파인애플볶음밥',
'샤인머스켓',
'고구마스프',
'돼지고기깻잎볶음',
'(저염·저당)쇠갈비찜',
'온청포묵국',
'양배추샐러드(딸기드레싱)'
]
# 괄호 안의 내용을 제거하는 정규 표현식
regex = re.compile(r'\([^)]*\)')
# 메뉴에서 괄호 안의 내용 제거
cleaned_menu = [regex.sub('', menu).strip() for menu in menu_list]
cleaned_menu
# 단지 코드를 index로 전용면적 구간을 컬럼(열)으로 하여 전용면적별세대수 구하기(pivot)
# 결과를 result_5_1 저장
# 단지 코드를 index --> 컬럼으로 변경하기 : reset_index, drop = False, inplace = True
result_5_1 = group_5_1.pivot(index='단지코드', columns ='전용면적구간', values = '전용면적별세대수')
result_5_1.reset_index(inplace = True, drop = False)
display(result_5_1.head())
type(result_5_1)
컬럼 -인덱스 변환
## save_check 데이터 프레임의 ['model_name', 'valid_data'] 컬럼을 지정하여 인덱스로 설정해 줍니다.
## 변환한 값은 result_comp 변수에 할당해 주세요.
## 참고함수: set_index
result_comp = save_check.set_index(["model_name","valid_data"])
result_comp
# reset_index 원본 데이터
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/pop_simple.csv'
pop = pd.read_csv(path)
pop.set_index('year', inplace = True)
pop.index.name = None
# 확인
pop.head()
인덱스 초기화
# pop.reset_index(drop=False)
pop.reset_index(drop=False,inplace=True)
# 확인
pop.head(10)
# reset_index 활용 drop
# 데이터 읽어오기
import pandas as pd
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
pop = pd.read_csv(path)
tip = pd.DataFrame(pop)
tip_top10 = tip.sort_values(by='total_bill',ascending=False)
tip_top10
import numpy as np
import pandas as pd
import os
import csv
import matplotlib.pyplot as plt
data = pd.read_csv('./csv/교원+1인당+학생수(구별)_20230820151017.csv',index_col=0)
data
data.index.name = None 적용
import numpy as np
import pandas as pd
import os
import csv
import matplotlib.pyplot as plt
data = pd.read_csv('./csv/교원+1인당+학생수(구별)_20230820151017.csv',index_col=0)
data.index.name = None
data
data.index.name = None 적용
import pandas as pd
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/pop_simple.csv'
pop = pd.read_csv(path)
pop.set_index('year', inplace = True)
pop.index.name = None
# 인덱스 초기화
pop.reset_index(drop=False,inplace=True)
# 확인
pop.head(10)