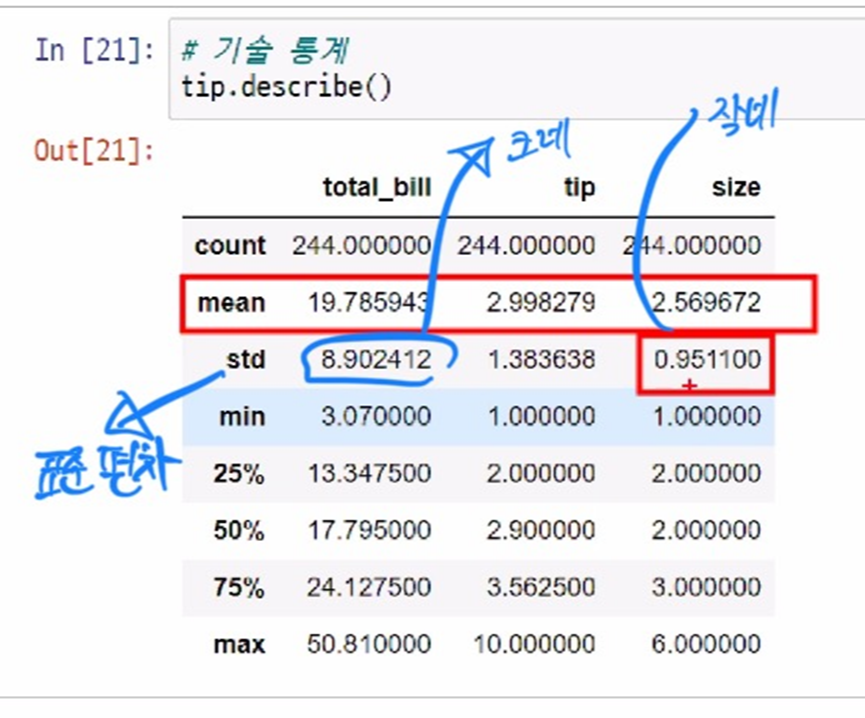
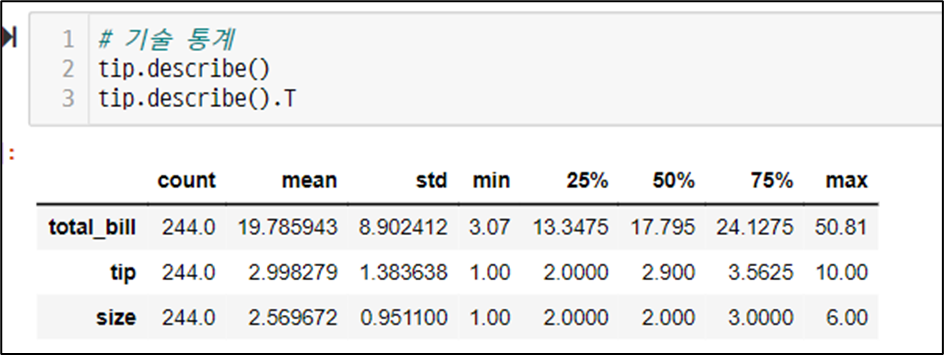
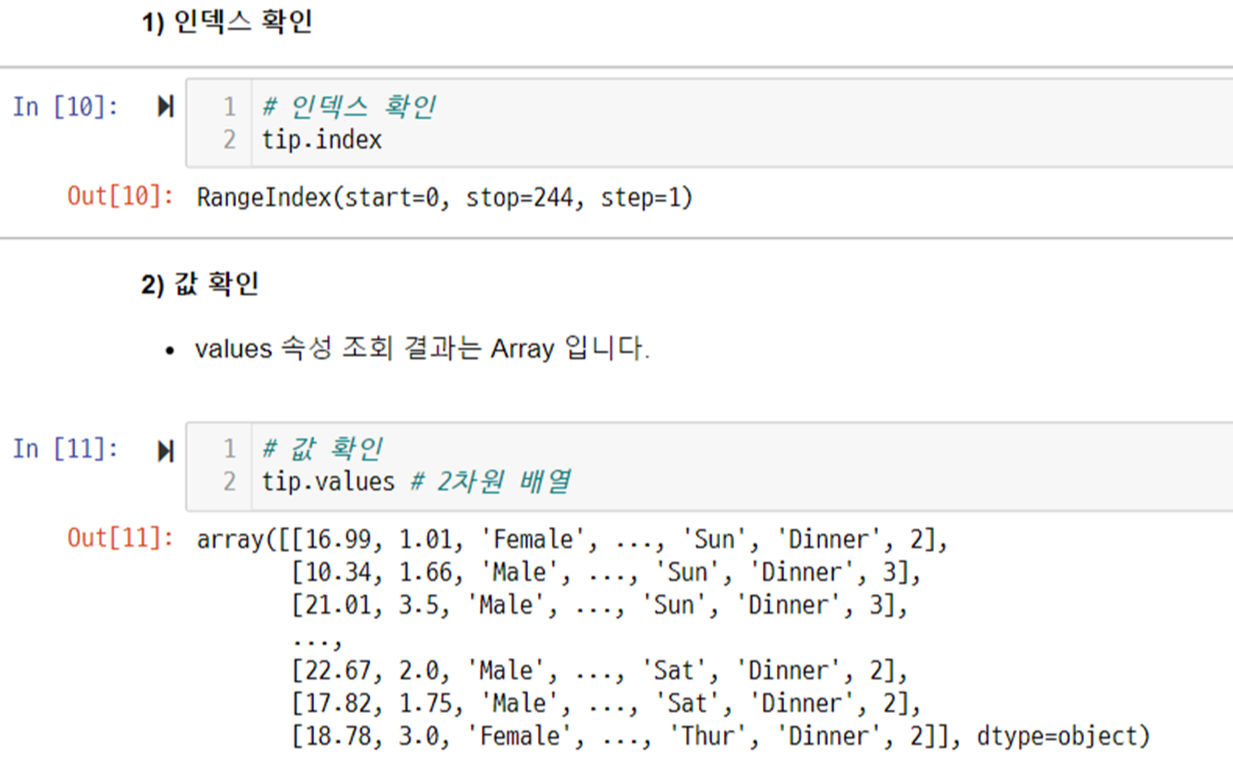
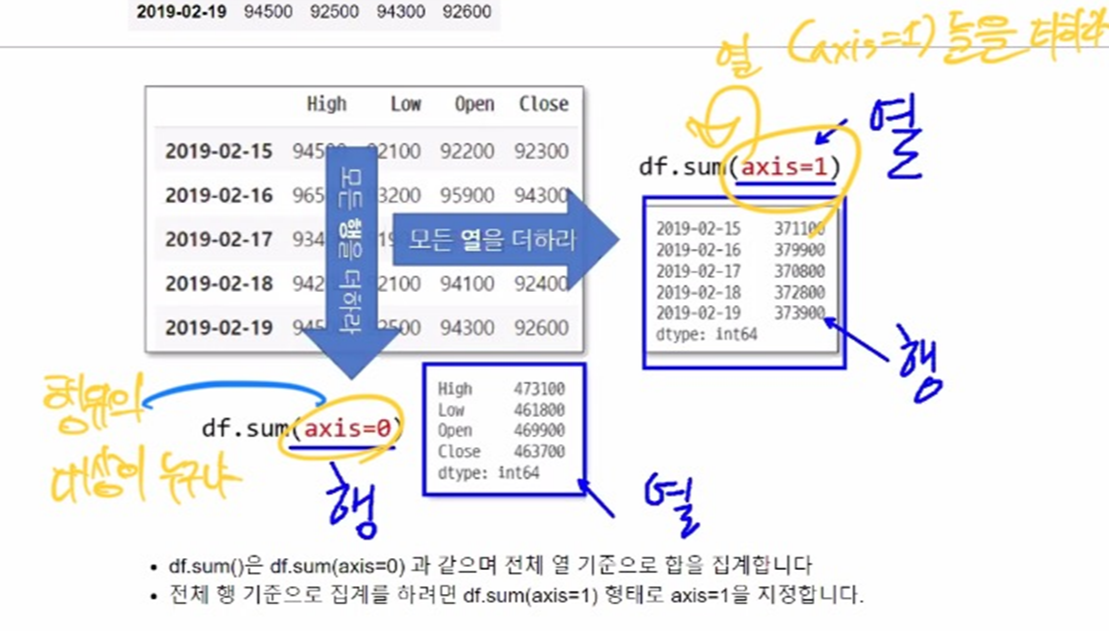
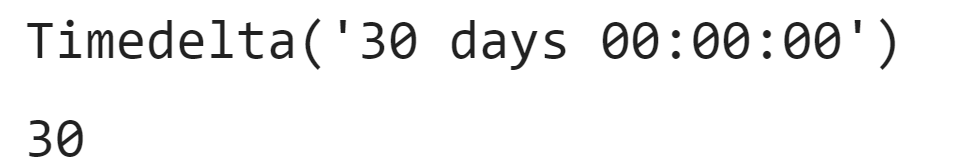# 단지 코드를 index로 전용면적 구간을 컬럼(열)으로 하여 전용면적별세대수 구하기(pivot)
# 결과를 result_5_1 저장
# 단지 코드를 index --> 컬럼으로 변경하기 : reset_index, drop = False, inplace = True
result_5_1 = group_5_1.pivot(index='단지코드', columns ='전용면적구간', values = '전용면적별세대수')
result_5_1.reset_index(inplace = True, drop = False)
display(result_5_1.head())
type(result_5_1)
컬럼 -인덱스 변환
## save_check 데이터 프레임의 ['model_name', 'valid_data'] 컬럼을 지정하여 인덱스로 설정해 줍니다.
## 변환한 값은 result_comp 변수에 할당해 주세요.
## 참고함수: set_index
result_comp = save_check.set_index(["model_name","valid_data"])
result_comp
# reset_index 원본 데이터
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/pop_simple.csv'
pop = pd.read_csv(path)
pop.set_index('year', inplace = True)
pop.index.name = None
# 확인
pop.head()
인덱스 초기화
# pop.reset_index(drop=False)
pop.reset_index(drop=False,inplace=True)
# 확인
pop.head(10)
# reset_index 활용 drop
# 데이터 읽어오기
import pandas as pd
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
pop = pd.read_csv(path)
tip = pd.DataFrame(pop)
tip_top10 = tip.sort_values(by='total_bill',ascending=False)
tip_top10
import numpy as np
import pandas as pd
import os
import csv
import matplotlib.pyplot as plt
data = pd.read_csv('./csv/교원+1인당+학생수(구별)_20230820151017.csv',index_col=0)
data
data.index.name = None 적용
import numpy as np
import pandas as pd
import os
import csv
import matplotlib.pyplot as plt
data = pd.read_csv('./csv/교원+1인당+학생수(구별)_20230820151017.csv',index_col=0)
data.index.name = None
data
data.index.name = None 적용
import pandas as pd
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/pop_simple.csv'
pop = pd.read_csv(path)
pop.set_index('year', inplace = True)
pop.index.name = None
# 인덱스 초기화
pop.reset_index(drop=False,inplace=True)
# 확인
pop.head(10)
# 키워드를 추출하고 가장 많이 등장한 상위 10개를 세어줍니다.
keywords = competition_info_df['키워드'].str.split('|').explode()
keyword_counts = keywords.value_counts().head(10)
print(keyowrd_counts)
조회 - 특정 - 문자와 숫자가 함께 있을 때 숫자 부분만 조회
import pandas as pd
# 예시 데이터 생성
data = {'용량': ['100ml', '250ml', '500ml', '1L', '2.5L']}
df = pd.DataFrame(data)
# '용량' 열에서 숫자 부분만 추출
df['숫자'] = df['용량'].str.extract('(\d+\.?\d*)')
df
조회 - 특정 - 컬럼에서 원하는 부분만 슬라이싱
nation_wide['식품중량'].str[0]
조회 - 특정 - 원하는 부분만 추출, "칼럼이름".str[n:n]
import pandas as pd
df = pd.read_csv('train.csv')
df.ID.str[0:6] # 여기에서 ID는 데이터프레임의 컬럼 이름
# 예시
# 단일 조건
df.loc[ df['cmpSclNm'] =='중소기업']
# 조건 여러 개
df.loc[ ( df['기업명'] == '(주)드림' ) & ( df['accNm'] == '영업이익' ) ]
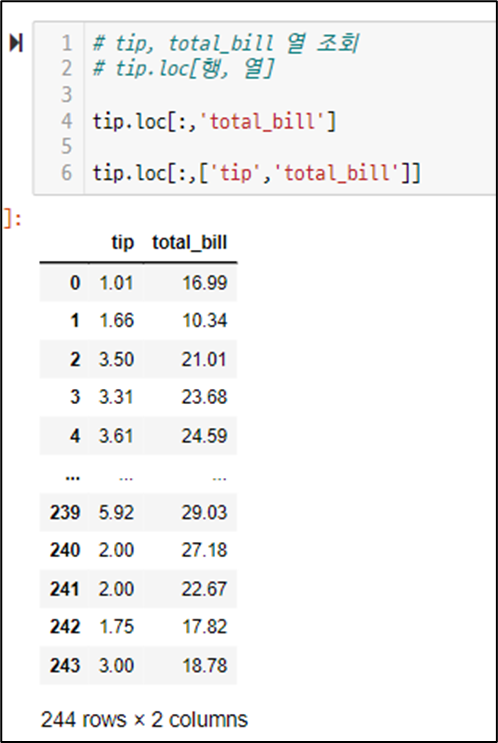
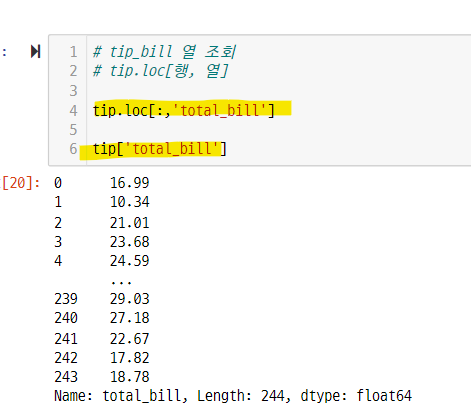
조회 - 특정 - 특정 열 조회
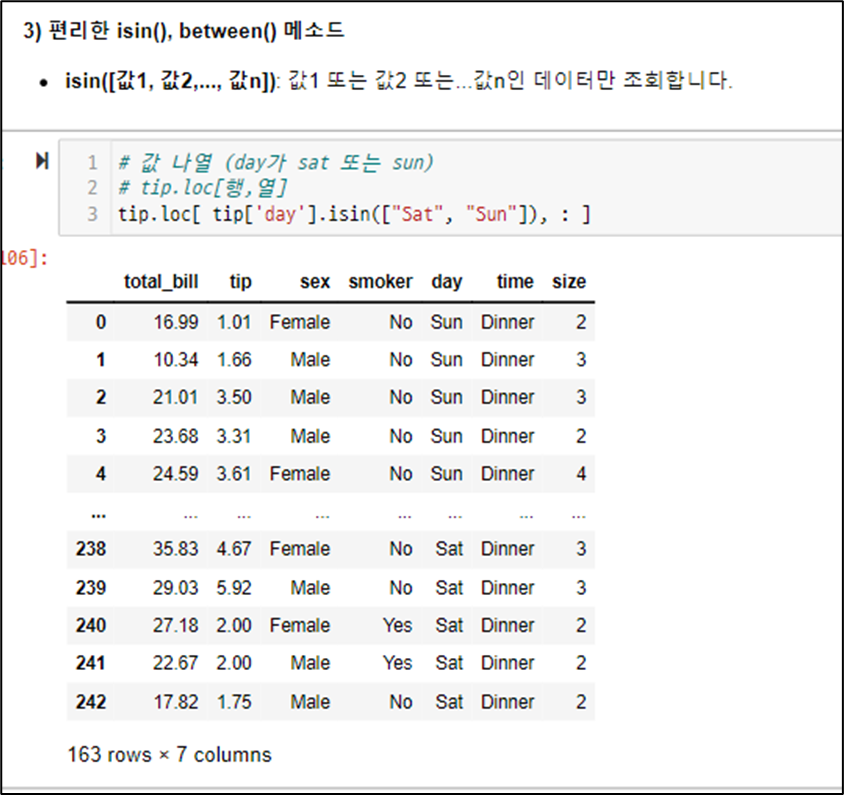
tip.loc[:,'total_bill']
조회 - 특정-여러 컬럼 선택 조회
tip.loc[:, ['tip', 'total_bill'] ]
조회 - 특정 -특정 열 조회 loc 방식 비교
조회 - 일치 -컬럼명 일치 여부 확인
target_01 = bicycle_20_01
target_06 = bicycle_20_06
feature = [ bicycle_20_01,bicycle_20_02,bicycle_20_03,bicycle_20_04,bicycle_20_05,bicycle_20_06,
bicycle_20_07,bicycle_20_08,bicycle_20_09,bicycle_20_10,bicycle_20_11,bicycle_20_12]
for i in feature:
print(target_01.columns == i.columns)
for i in feature:
print(target_06.columns == i.columns)
조회 - 컬럼의 데이터별 갯수 구하기 value_counts
df['컬럼 이름'].value_counts()
조회 - 형식 - 숫자가 아닌 행 찾기 데이터프레임
[ 데이터프레임['컬럼명'].str.isnumeric() == False ]
조회 - 형식 - 수치형인 컬럼만 추출
numeric_columns = df[ df.dtypes != 'object' ]
조회 - 형식 - 문자형인 컬럼만 추출
string_columns = df[ df.dtypes == 'object' ]
조회 - 형식 - 숫자형 데이터, 문자형 데이터 구분
# 데이터 유형을 문자열과 숫자로 구분
is_string = df_competition['상금 정보'].apply(lambda x: isinstance(x, str))
is_numeric = df_competition['상금 정보'].apply(lambda x: isinstance(x, (int, float)))
display(is_string)
print()
# 문자열과 숫자 데이터의 개수 세기
num_strings = is_string.sum()
num_numerics = is_numeric.sum()
print("문자열 데이터 개수:", num_strings)
print("숫자형 데이터 개수:", num_numerics)
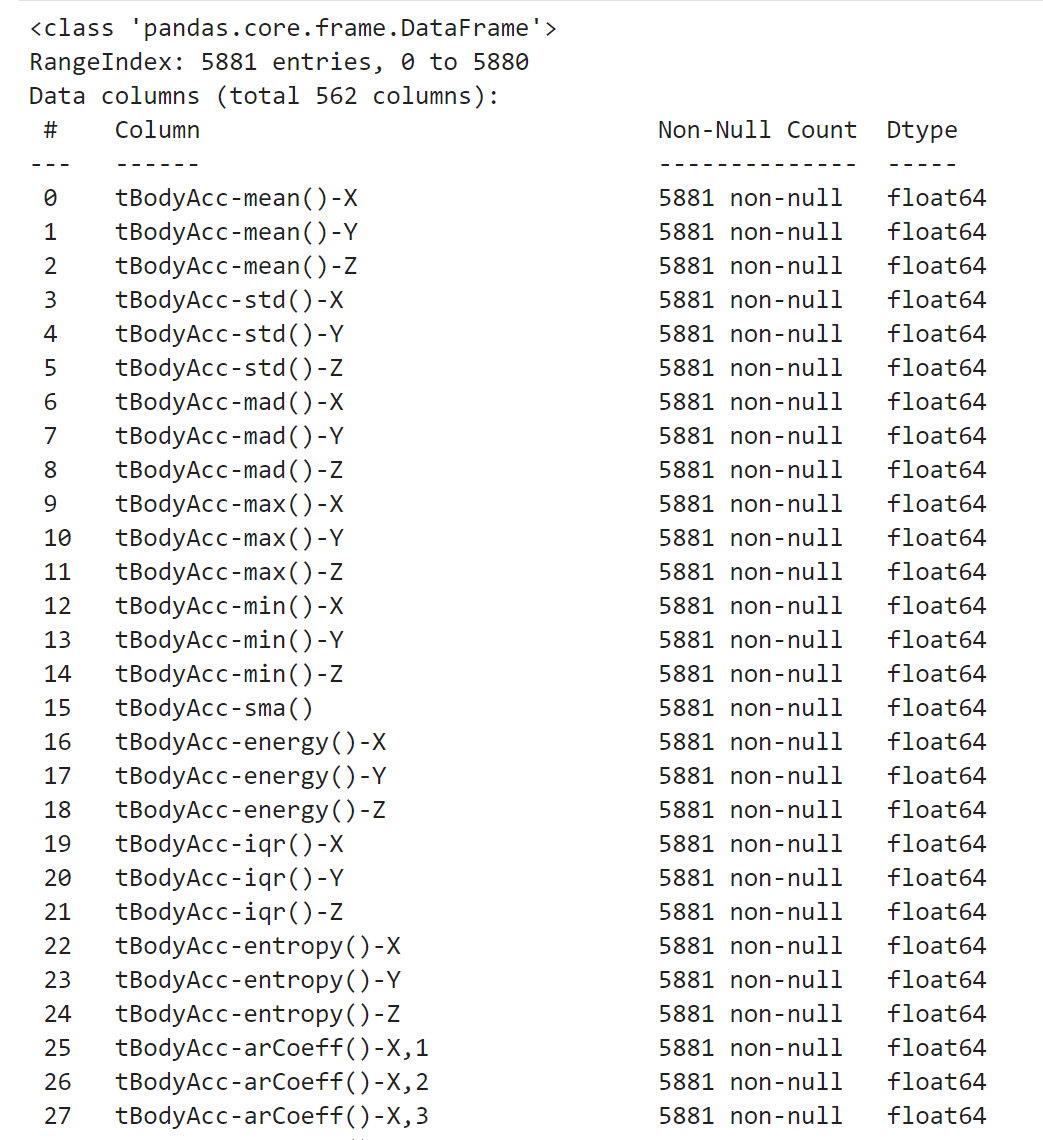
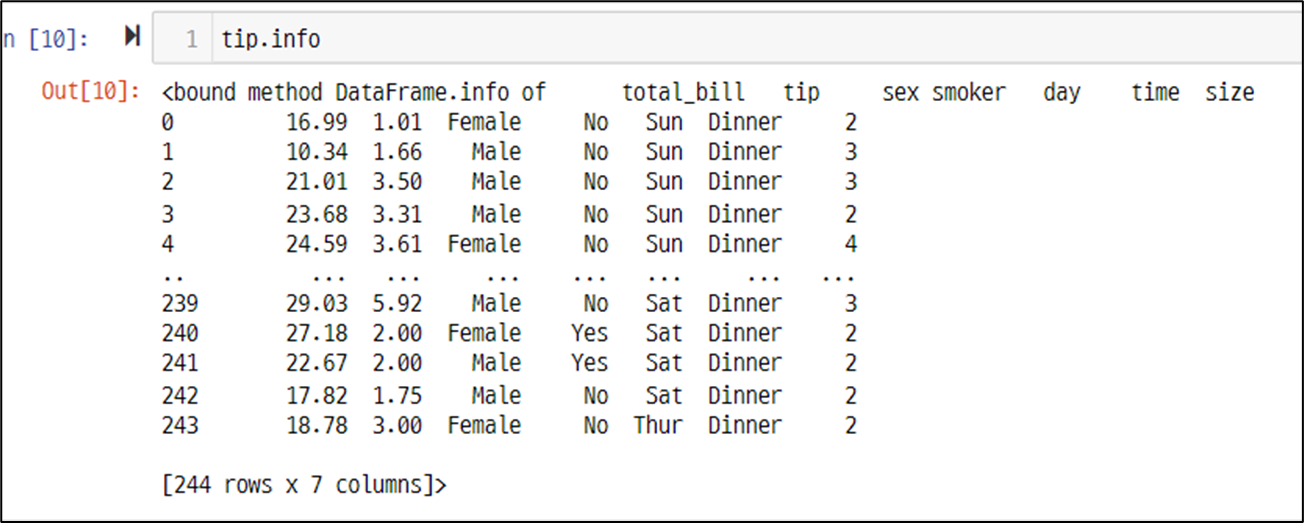
정보 확인 - info
# 데이터 기초 정보 확인2
## data 데이터프레임의 컬럼명, 데이터 개수, 타입 정보를 보기 쉽게 출력해 주세요.
## .info 파라미터: verbose=True, null_counts=True
data.info(verbose=True, null_counts=True)
verbose=True: 이 옵션을 사용하면 데이터프레임의 모든 컬럼에 대한 상세한 정보를 출력합니다. 컬럼명, 컬럼의 데이터 타입, 비어 있지 않은 값의 개수(null이 아닌 값의 개수), 메모리 사용량 등이 포함됩니다.
verbose=False: 이 옵션을 사용하면 데이터프레임의 요약 정보만 출력됩니다. 모든 컬럼의 상세한 정보는 출력되지 않으며, 데이터프레임의 크기(행과 열의 개수)와 같은 기본 정보만 표시됩니다.
# 데이터 읽어오기
import pandas as pd
import csv
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
tip = pd.read_csv(path)
# 확인
tip
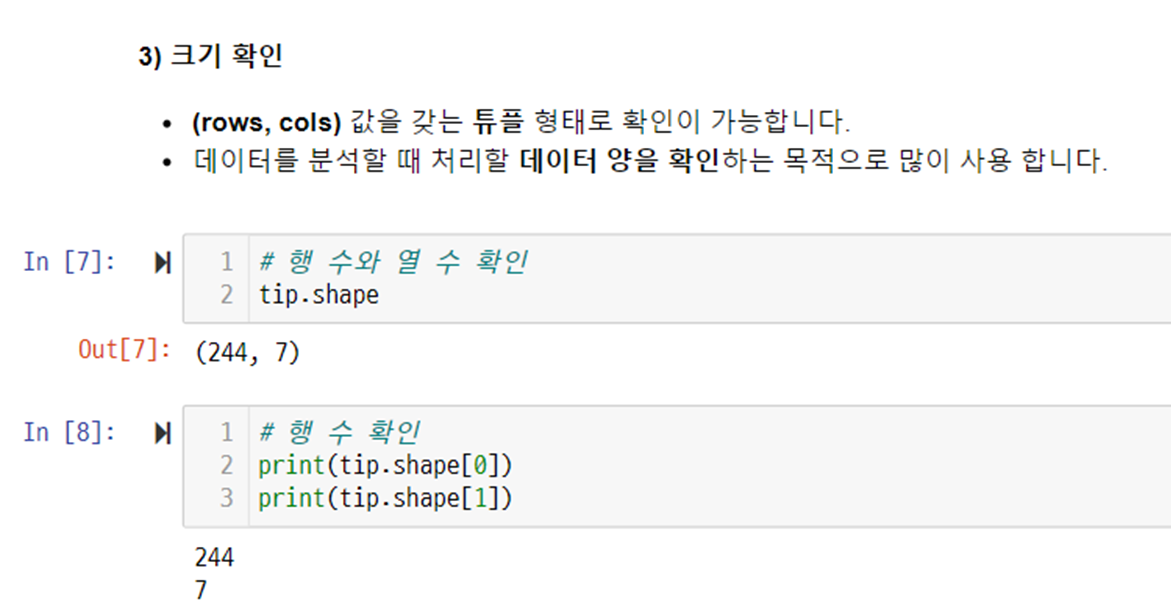
# total_bill 열 조회
tip.shape
# 데이터프레임의 특정 컬럼에서 띄어쓰기를 기준으로 앞 부분만 선택하여 기존 데이터 대체
# 예시 데이터프레임 생성
df = pd.DataFrame({
'Menu': [
'스크램블에그',
'고로케',
'카레 고등어구이',
'콩가루 배춧국',
'크림 리조또',
'돼지고기 파인애플볶음밥',
'샤인머스켓',
'고구마 스프',
'돼지고기 깻잎볶음',
'쇠갈비 찜',
'온청포 묵국',
'양배추 샐러드'
]
})
# 띄어쓰기를 기준으로 첫 부분만 선택하여 기존 데이터 대체
df['Menu'] = df['Menu'].apply(lambda x: x.split(' ')[0])
df
변경 - 데이터 - 이름에서 괄호 ( ) 부분을 제거하고 기존 값을 대체
# 괄호가 포함된 새로운 예시 데이터프레임 생성
df_with_parentheses = pd.DataFrame({
'Menu': [
'스크램블에그(달걀)',
'고로케(감자)',
'카레(고등어)',
'콩가루(배춧국)',
'크림(리조또)',
'돼지고기(파인애플볶음밥)',
'샤인머스켓(포도)',
'고구마(스프)',
'돼지고기(깻잎볶음)',
'쇠갈비(찜)',
'온청포(묵국)',
'양배추(샐러드)'
]
})
# 괄호와 괄호 안의 내용을 제거하는 정규 표현식
regex = re.compile(r'\([^)]*\)')
# 메뉴에서 괄호 안의 내용 제거 후 띄어쓰기를 기준으로 첫 부분만 선택
df_with_parentheses['Menu'] = df_with_parentheses['Menu'].apply(lambda x: regex.sub('', x).split(' ')[0])
df_with_parentheses
변경 - 순서 - 컬럼 순서 변경
# 열 순서 변경
pop_test = pop_test[['year', 'household', 'total', 'male', 'female', 'k_total', 'k_male', 'k_female', 'f_total', 'f_male', 'f_female', 'older_65']]
변경 - 컬럼 -컬럼명을 첫 행의 값으로 변경, 첫 행 삭제
import pandas as pd
# 데이터프레임 예시 생성
data = [["Column1", "Column2", "Column3"], [1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(data)
display(df)
# 첫 번째 행을 컬럼으로 설정
df.columns = df.iloc[0]
display(df)
# 첫 번째 행 삭제
df = df.drop(df.index[0])
display(df)
# 데이터 읽어오기
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/pop_simple.csv'
pop = pd.read_csv(path)
pop.set_index('year', inplace = True)
pop.index.name = None
pop.reset_index(drop=False,inplace=True)
# 열 이름 변경
pop.rename(columns={'index':'year'}, inplace=True)
# 확인
pop.head(10)
변경 - 이름 - 컬럼 이름 변경 rename
데이터프레임.rename( columns = { '변경 전 컬럼이름' : '변경 후 컬럼이름',
'변경 전 컬럼이름' : '변경 후 컬럼이름'} )
변경 - 이름 - 변경
pop.rename(columns={'index':'year'}, inplace=True)
# 확인
pop.head()
변경 - 이름 - 컬럼명 변경, 반복문
for i in feature:
i.rename(columns = {'이동거리(M)' :'이동거리',
'이용시간(분)':'이용시간'}, inplace =True)
for i in feature:
print(target_01.columns == i.columns)
변경 - 행 - 특정 컬럼에서 리스트 안에 있는 데이터와 일치하는 행만 남기기
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({
'음식명': ['잡곡밥', '땅콩연근조림', '생선까스', '김치찌개', '된장국'],
'가격': [5000, 6000, 7000, 8000, 9000]
})
# 특정 음식명만 포함하는 행을 필터링
filter_list = ['잡곡밥', '땅콩연근조림', '생선까스']
filtered_df = df[df['음식명'].isin(filter_list)]
filtered_df
import pandas as pd
# 예시 데이터프레임 생성
df = pd.DataFrame({
'열1': [1, 2, 3],
'열2': [4, 5, 6]
})
# 새로운 열 추가 및 모든 행에 동일한 텍스트 데이터 할당
df['새로운열'] = '텍스트 데이터'
print(df)
추가 - 컬럼 - 새로운 컬럼 추가
import pandas as pd
# 예시 데이터프레임 생성 (3행)
df = pd.DataFrame({
'열1': [1, 2, 3],
'열2': [4, 5, 6]
})
# 리스트를 새 열로 추가
df['새로운열'] = ['밥', '김치', '된장']
print(df)
추가 - 컬럼 - 컬럼 추가, 리스트 형태
# 리스트를 포함하는 새 열 추가
df_competition['새로운열'] = [[1, 2], [3, 4]]
# 특정 열 삭제
데이터프레임.drop('열 이름', axis=1, inplace = True)
# 여러 열 삭제
삭제할 열 리스트 = [ '열 이름 1', '열 이름 2' ]
데이터프레임.drop( columns = 삭제할 열 리스트, axis =1, inplace = True )
삭제 - 데이터프레임의 중복 컬럼 삭제
# 'A' 컬럼 중 첫 번째만 선택
new_df = df.loc[:, ~df.columns.duplicated()]
삭제 -행 - 삭제
# 특정 행 삭제
데이터프레임.drop( '행 이름', inplace = True )
# 여러 행 삭제
삭제할 행 리스트 [ '행 이름 1', '행 이름 2' ]
데이터프레임.drop( 삭제할 행 리스트, inplace = True )
# 조건 삭제
# 예시 : 30 이상인 행 삭제
데이터프레임 = 데이터프레임[ 데이터프레임['Age'] < 30]
삭제 - 행 - 컬럼명을 첫 행의 값으로 변경, 첫 행 삭제
import pandas as pd
# 데이터프레임 예시 생성
data = [["Column1", "Column2", "Column3"], [1, 2, 3], [4, 5, 6]]
df = pd.DataFrame(data)
display(df)
# 첫 번째 행을 컬럼으로 설정
df.columns = df.iloc[0]
display(df)
# 첫 번째 행 삭제
df = df.drop(df.index[0])
display(df)
삭제 - 행 -첫 번째 행을 삭제
df.drop(df.index[0)
삭제 - 행 - 중복행 제거하기
df.drop_duplicates( subset=None, keep = 'first', inplace = True, ignore_index = False)
# subset : 중복 검사를 할 때 고려해야 할 열을 지정하는 매개변수
# keep = 'first' : 중복된 행 중 어떤 행을 유지할지 지정하는 매개변수
import datetime
# '날짜' 열을 datetime 형식으로 변환
df_participate['일자'] = pd.to_datetime(df_participate['일자'])
# 월별 열 생성
df_participate['월별'] = df_participate['일자'].dt.to_period('M')
df_participate.head()
조회 - 오늘 날짜 출력
from datetime import datetime
print(datetime.today())
print(datetime.today().strftime("%Y-%m-%d %H:%M:%S"))
print(datetime.today().strftime("%Y-%m-%d"))
import pandas as pd
# UTF-8 인코딩으로 파일 읽기
df = pd.read_csv('mymeal_all.csv', encoding='utf-8')
# CP949 인코딩으로 파일 저장
df.to_csv('mymeal_all_cp949.csv', encoding='cp949', index=False)
저장 - csv로 저장
# 결과 저장
# result 변수를 인덱스 미포함하여 'result3.csv' 파일로 저장 합니다.
# 저장경로는 현재 경로의 하위 './data' 폴더로 지정해 주세요.
result.to_csv('./data/result3.csv',index=False)
저장 - 특정 위치에 csv로 저장
import pandas as pd
# 예시 DataFrame 생성
data = {'Column1': [1, 2, 3], 'Column2': [4, 5, 6]}
your_dataframe = pd.DataFrame(data)
# CSV 파일로 저장할 경로
file_path = 'path/to/your/folder/filename.csv'
# DataFrame을 CSV 파일로 저장
your_dataframe.to_csv(file_path, index=False)
저장 - Excel로 저장
df.to_excel('example.xlsx', index=False)
조회, 확인 - 특정 위치의 파일 목록 확인
import os
# 확인하고 싶은 디렉토리 경로
directory_path = 'your/directory/path'
# 디렉토리 내의 파일과 하위 디렉토리 목록 가져오기
file_list = os.listdir(directory_path)
# 파일 목록 출력
print(file_list)