기본 차트 그리기 plt.plot(1차원 값)
# 차트 그리기
plt.plot(data['Temp'])
# 화면에 보여주기
plt.show()
x축, y축 지정하고 그래프 그리기
import pandas as pd
import matplotlib.pyplot as plt
plt.rc('font', family = 'Malgun Gothic')
plt.rcParams['font.family']
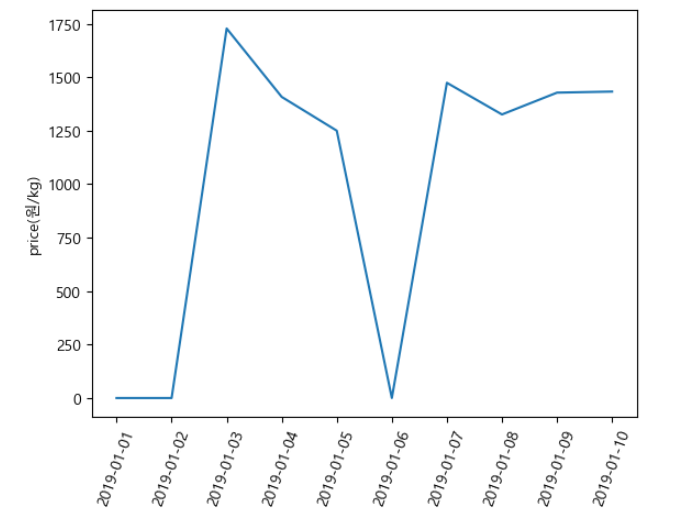
plt.plot(df['timestamp'], df['price(원/kg)])
plt.xticks(rotation=70)
plt.ylabel('price(원/kg)')
plt.show()
# 방법 2
plt.plot('Date', 'Temp', data = data)
plt.show()
시각화 axhline
train.groupby('hour').mean()['hour_bef_temperature'].plot()
plt.axhline(train.groupby('hour').mean()['hour_bef_temperature'].mean())
차트 꾸미기
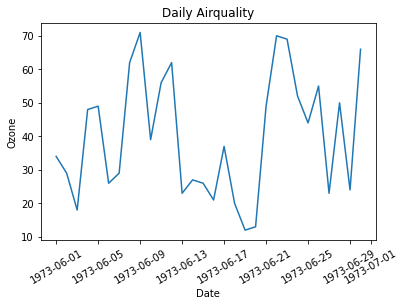
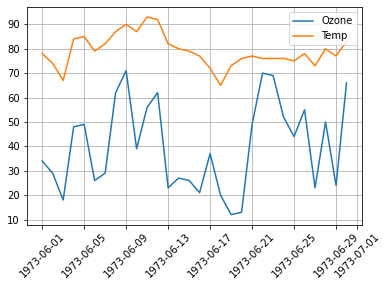
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()
라인스타일 조정
plt.plot(data['Date'], data['Ozone']
,color='green' # 칼러
, linestyle='dotted' # 라인스타일
, marker='o') # 값 마커(모양)
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
plt.show()
그래프 겹쳐서 그리기
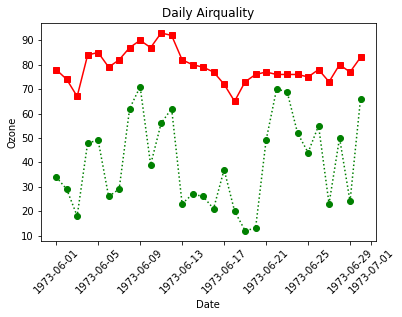
# 첫번째 그래프
plt.plot(data['Date'], data['Ozone'], color='green', linestyle='dotted', marker='o')
# 두번째 그래프
plt.plot(data['Date'], data['Temp'], color='r', linestyle='-', marker='s')
plt.xlabel('Date')
plt.ylabel('Ozone')
plt.title('Daily Airquality')
plt.xticks(rotation=45)
# 위 그래프와 설정 한꺼번에 보여주기
plt.show()
범례, 그리드 추가
plt.plot(data['Date'], data['Ozone'], label = 'Ozone') # label = : 범례추가를 위한 레이블값
plt.plot(data['Date'], data['Temp'], label = 'Temp')
plt.legend(loc = 'upper right') # 레이블 표시하기. loc = : 위치
plt.grid()
plt.xticks(rotation=45)
plt.show()
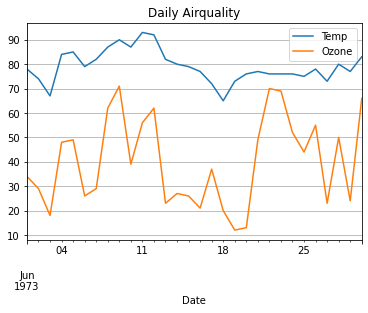
여러 개 차트 그리기, 방식 2
data.plot(x = 'Date', y = ['Temp','Ozone']
, title = 'Daily Airquality')
plt.grid()
plt.show()
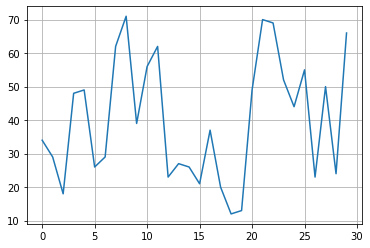
축 범위 조정
plt.plot(data['Ozone'])
# plt.ylim(0, 100)
# plt.xlim(0, 10)
plt.grid()
plt.show()
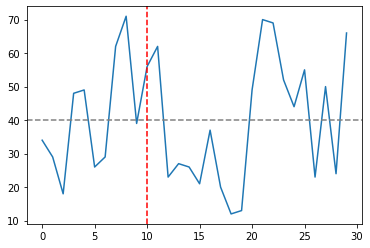
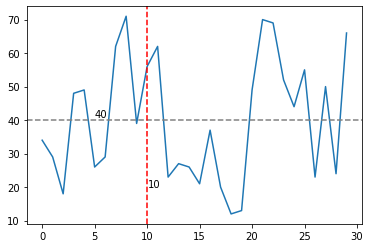
그래프 수직선, 수평선 추가
plt.plot(data['Ozone'])
plt.axhline(40, color = 'grey', linestyle = '--')
plt.axvline(10, color = 'red', linestyle = '--')
plt.show()
그래프에 텍스트 추가
plt.plot(data['Ozone'])
plt.axhline(40, color = 'grey', linestyle = '--')
plt.axvline(10, color = 'red', linestyle = '--')
plt.text(5, 41, '40')
plt.text(10.1, 20, '10')
plt.show()
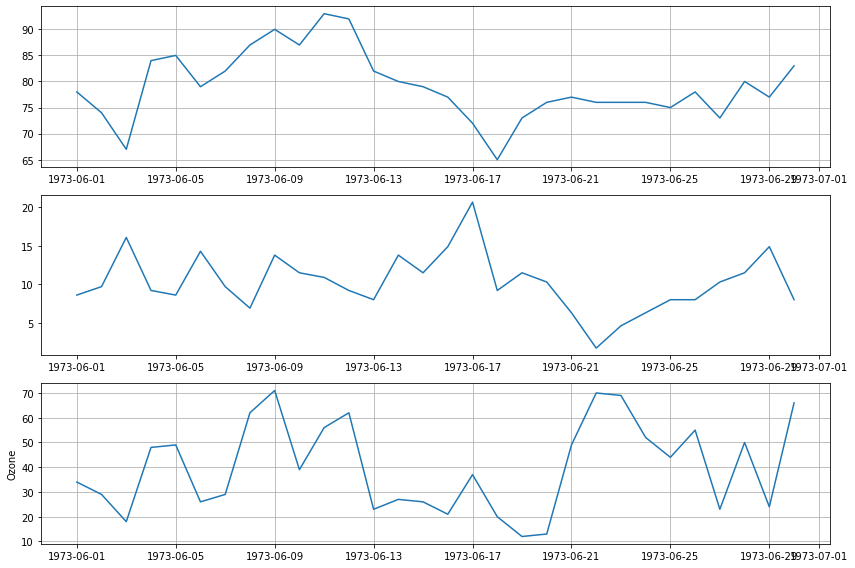
여러 그래프 나눠서 그리기
plt.figure(figsize = (12,8))
plt.subplot(3,1,1)
plt.plot('Date', 'Temp', data = data)
plt.grid()
plt.subplot(3,1,2)
plt.plot('Date', 'Wind', data = data)
plt.subplot(3,1,3)
plt.plot('Date', 'Ozone', data = data)
plt.grid()
plt.ylabel('Ozone')
plt.tight_layout() # 그래프간 간격을 적절히 맞추기
plt.show()
하나의 데이터프레임에서 여러 개의 차트 그리기
# 남녀 인구 변화
plt.plot(pop_test[['male','female']])
plt.show()