행동 추론
1] 데이터 불러오기
(1) 라이브러리
# pandas, numpy, matplotlib, seaborn, os 등 필요 라이브러리 호출
# 데이터를 나누기 위한 sklearn.model_selection 모듈의 train_test_split 함수 사용
# 모델 성능 평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 사용
# XGBClassifier 알고리즘 사용을 위한 모듈 호출
# 진척도 상황을 확인하기 위한 tqdm 라이브러리 호출
# 저장한 모델 사용을 위한 joblib 라이브러리 호출
## 그외 라이브러리는 필요에 따라 호출해서 사용하세요.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import joblib
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from xgboost import XGBClassifier
(2) 모델 호출
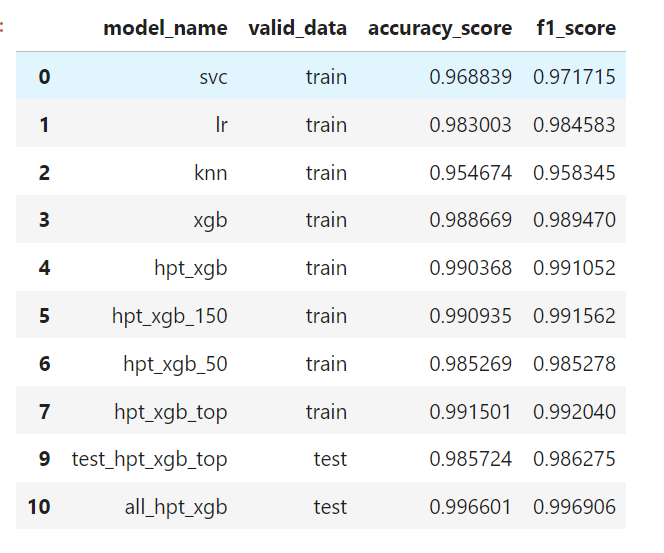
# 모델별 결과 불러오기
## 모델별 정확도를 비교 할 수 있도록 결과 저장 파일을 불러 옵니다.
## 'data' 폴더에서 /result5.csv 파일을 불러와 result 변수에 할당 합니다.
## result 변수에 할당이 잘 되었는지 확인해 주세요.
result = pd.read_csv('./data/result5.csv')
result
(3) 중요 feature 불러오기
# 중요 feature 불러오기
## 모델 정확도에 높은 영향을 미치는 feature 이름을 저장한 importance_top.pkl 파일을 불러와 importance_top에 저장 합니다.
## importance_top 변수에 할당이 잘 되었는지 확인해 주세요.
importance_top = joblib.load('importance_top.pkl')
importance_top
(4) test 데이터 불러오기
# test 데이터 불러오기
## 'data' 폴더에서 test_data.csv 파일을 불러와서 test_data 변수에 할당해 주세요.
## 잘 할당 되었는지 데이터를 확인해 주세요.
test_data = pd.read_csv('./data/test_data.csv')
test_data
(5) train 데이터 불러오기
# train 데이터 불러오기
## 'data' 폴더에서 train_data.csv 파일을 불러와서 train_data 변수에 할당해 주세요.
## 잘 할당 되었는지 데이터를 확인해 주세요.
train_data = pd.read_csv('./data/train_data.csv')
train_data
2] 데이터 합치기, 인덱스 초기화
# 데이터 합치기
## all_data 변수에 train 데이터셋과 test 데이터셋을 위/아래로 합쳐서 할당 합니다.
all_data = pd.concat([train_data, test_data])
all_data
# 데이터 인덱스 초기화
## 데이터셋을 위아래로 합치면 인덱스 중복이 발생 합니다.
## 인덱스가 중복되지 않도록 인덱스를 리셋해 주세요.
all_data.reset_index(drop=True, inplace=True)
all_data
'WALKING_UPSTAIRS' 행동분류에 영향을 미치는 중요 feature 도출
1] X, Y 데이터 나누기
# X, Y 데이터 나누기
## 모델 학습을 위해 feature(X) 데이터와 target(Y) 데이터를 나누어 주어야 합니다.
## target(Y)을 분리를 위해 all_data['Activity'] 값을 숫자로 변환 할 때 'WALKING_UPSTAIRS' 만 인식 할 수 있도록 숫자를 구성해야 합니다.
## [TIP]: {'STANDING':0, 'SITTING':0, 'LAYING':0, 'WALKING':0, 'WALKING_UPSTAIRS':1, 'WALKING_DOWNSTAIRS':0}
## 변환된 결과를 all_y_map 변수에 할당 합니다.
## all_data 데이터에서 2일차에서 선정한 중요도가 높은 feature 들만 골라 all_x 변수에 할당 합니다.
## 중요도가 높은 feature 들의 이름은 .pkl 파일에서 불러와 importance_top 변수에 저장되어 있습니다.
all_y_map = all_data['Activity'].map({'STANDING':0, 'SITTING':0, 'LAYING':0, 'WALKING':0, 'WALKING_UPSTAIRS':1, 'WALKING_DOWNSTAIRS':0})
all_x = all_data[importance_top]
2] 학습 데이터 나누기
# 학습 데이터 나누기
## 학습에 필요한 all_x 와 all_y_map 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: all_x_train, all_x_val, all_y_train, all_y_val
all_x_train, all_x_val, all_y_train, all_y_val = train_test_split(all_x,all_y_map,train_size=0.7,random_state=2023)
3] AI 모델링 및 결과 예측
# AI 모델링 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 walkingup_model 변수에 모델을 생성 및 초기화 합니다.
## 파라미터는 최종 조정 파라미터를 사용하고, random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 all_x_val 데이터의 결과를 예측하여 walkingup_pred 변수에 할당 합니다.
walkingup_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
walkingup_model.fit(all_x_train, all_y_train)
walkingup_pred = walkingup_model.predict(all_x_val)
walkingup_pred
4] 성능 평가
# walkingup_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(all_y_val,walkingup_pred))
print('\n confusion_matrix: \n',confusion_matrix(all_y_val,walkingup_pred))
print('\n classification_report: \n',classification_report(all_y_val,walkingup_pred))
5] 예측결과 저장
# walkingup_xgb_model 예측결과 저장
## result 데이터프레임 12번 인덱스에 'walkingup_xgb'(모델명), 'all'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[12] = ['walkingup_xgb', 'all', accuracy_score(all_y_val,walkingup_pred), f1_score(all_y_val,walkingup_pred, average = 'macro')]
result
모델 정확도 개선
1] 데이터프레임 생성
# feature 명 데이터 파일 생성
## up_importance_sort 데이터프레임 변수를 생성 및 초기화 합니다.
up_importance_sort = pd.DataFrame()
2] feature 명 할당
# feature 명 할당
## up_importance_sort['feature_name'] 열에 walkingup_model 학습에 사용한 all_x 데이터프레임의 모든 feature 명을 할당 합니다.
up_importance_sort['feature_name'] = all_x.columns
up_importance_sort
3] feature 중요도 할당
# feature importances 할당
## up_importance_sort['feature_importance'] 열에 walkingup_model 모델의 feature_importances 를 할당해 줍니다.
## 참고함수: feature_importances_
up_importance_sort['feature_importance'] = walkingup_model.feature_importances_
up_importance_sort
4] 중요도 순으로 인덱스 재정렬
# 중요도 순으로 인덱스 재 정렬
## up_importance_sort 데이터프레임을 up_importance_sort['feature_importance'] 순으로 내림차순 정열 합니다.
## 정렬 후 결과를 확인 합니다.
up_importance_sort.sort_values(by='feature_importance', ascending=False, inplace=True)
up_importance_sort
5] 인덱스 초기화
# 데이터 인덱스 초기화
## 인덱스가 순서대로 나열 되도록 인덱스를 리셋해 주세요.
up_importance_sort.reset_index(drop=True, inplace=True)
up_importance_sort
최적의 Feature Selection 찾기
1] 데이터프레임 생성 및 최적의 Feature Selection 찾기
# 최적의 Feature Selection 찾기
## acc 데이터 프레임을 생성 및 초기화 합니다.(컬럼 지정: columns=['accuracy_score'])
## 전체 feature는 561개에서 도출한 Top feature 개수를(예: 141개) 선별 했기에 feature를 1개 ~ Top feature 개수까지 모델링과 결과를 도출 합니다.
## for 문을 사용해 중요도 상위 feature 1개 모델링부터 Top feature 개수까지 순차적 모델링 실행 후 각 accuracy_score 결과를 acc 변수에 누적 합니다.
## [TIP] tqdm: tqdm은 반복문에서 현재 계산되고 있는 부분의 퍼센테이지를 시각적으로 나태내어 줍니다.
## [TIP] tqdm 사용 예제: for i in range(10) -> for i in tqdm(range(10)):
acc = pd.DataFrame(columns=['accuracy_score'])
for i in tqdm(range(len(up_importance_sort))):
importance_n = up_importance_sort['feature_name'][:i+1]
x_train_n = all_x_train[importance_n]
x_val_n = all_x_val[importance_n]
xgb_n_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
xgb_n_model.fit(x_train_n, all_y_train)
xgb_n_pred = xgb_n_model.predict(x_val_n)
acc.loc[i] = accuracy_score(all_y_val,xgb_n_pred)
acc
2] 누적 결과 시각화
# accuracy_score 누적 결과 시각화
## accuracy_score 누적한 acc 변수를 plot으로 시각화 합니다.
plt.figure(figsize=(20,5))
plt.plot(acc, marker='o')
plt.xlabel('train_features')
plt.ylabel('accuracy')
plt.grid()
plt.show()
3] 최고 정확도 Feature 개수 찾기
# 최고 정확도 Feature 개수 찾기
## acc 변수를 accuracy_score 기준 내림차순으로 정렬 합니다.(인덱스 재설정X)
## 인덱스 번호는 누적 학습된 feature의 개수 입니다.
## accuracy_score 값으로 내림차순 정렬 후 이 가장 첫번째 행의 인덱스 번호가 가장 정확도가 좋은 feature 개수를 뜻합니다.
acc.sort_values(by = 'accuracy_score', ascending=False, inplace=True)
acc
4] 최고 정확도 Feature 열 저장
# 최고 정확도 Feature명 저장
## acc 결과에서 확인한 가장 성능좋은 결과를 내는 feature의 개수 만큼 importance_sort['feature_name']를 슬라이싱 하여
## feature의 이름을 up_importance_top 변수에 할당 합니다.
## 정확도 최고치 인덱스 값 +1 해서 슬라이싱 하세요.
## [TIP] 슬라이싱 할때 [:1] -> feature 0번 까지 짤림, [:100] -> feature 99번 까지 짤림
up_importance_top = up_importance_sort['feature_name'][:acc.index[0]+1]
up_importance_top
5] 훈련 데이터 생성
# 훈련 데이터 생성
## all_x_train 데이터에서 위에서 up_importance_top에 할당한 feature 들의 데이터를 x_train_top 변수에 할당해 줍니다.
## all_x_val 데이터에서 위에서 up_importance_top에 할당한 feature 들의 데이터를 x_val_top 변수에 할당해 줍니다.
all_x_train_top = all_x_train[up_importance_top]
all_x_val_top = all_x_val[up_importance_top]
6] 모델 선언, 학습, 예측
# AI 모델링 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 walkingup_top_model 변수에 모델을 생성 및 초기화 합니다.
## 파라미터는 최종 조정 파라미터를 사용하고, random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train_top, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 all_x_val_top 데이터의 결과를 예측하여 walkingup_pred 변수에 할당 합니다.
walkingup_top_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
walkingup_top_model.fit(all_x_train_top, all_y_train)
walkingup_top_pred = walkingup_top_model.predict(all_x_val_top)
walkingup_top_pred
7] 모델 평가
# 모델 평가 출력(accuracy_score, confusion_matrix, classification_report)
print('accuracy_score: ',accuracy_score(all_y_val,walkingup_top_pred))
print('\n confusion_matrix: \n',confusion_matrix(all_y_val,walkingup_top_pred))
print('\n classification_report: \n',classification_report(all_y_val,walkingup_top_pred))
8] 예측 결과 저장
# walkingup_top_model 예측결과 저장
## result 데이터프레임 13번 인덱스에 'walkingup_top'(모델명), 'all'(검증 데이터명), accuracy_score 결과, f1_score 결과 를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[13] = ['walkingup_top', 'all', accuracy_score(all_y_val,walkingup_top_pred), f1_score(all_y_val,walkingup_top_pred, average = 'macro')]
result
'WORKING_UPSTAIRS' 분류에 영향을 미치는 'sensor' 찾기
'WORKING_UPSTAIRS' 분류에 가장 영향 많이 미치는 상위 20개의 sensor 그룹을 찾아 시각화
1] 파일 불러오기
# features.csv 파일 불러오기
## 'data'폴더에서 features.csv 파일을 읽어와 feature_group 변수에 할당 하세요.
## 변수에 할당이 잘 되었는지 확인해 주세요.
feature_group =pd.read_csv('./data/features.csv')
2] 데이터프레임 merge
# 데이터프레임 merge
## merge_df 변수를 데이터프레임 타입으로 생성 및 초기화 합니다.
## feature_group 변수와 up_importance_sort 변수를 merge 하여 merge_df 할당 합니다.
## 데이터가 잘 할당 되었나 merge_df 데이터를 확인 합니다.
merge_df = pd.DataFrame()
merge_df = pd.merge(feature_group, up_importance_sort)
merge_df
3] 데이터그룹화
# 데이터 그룹화
## merge_df 변수를 'sensor' 기준으로 그룹화 하고 'feature_importance' 열의 데이터를 같은 'sensor' 그룹끼리 더해 줍니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 계산을 동시에 수행할 수 있습니다.
## [TIP] 변수.groupby(by='그룹기준열')['연산 할 열'].연산메서드()
sensor_sum = merge_df.groupby(by='sensor')['feature_importance'].sum()
sensor_sum
4] 중요도 재정렬
# sensor 중요도 재 정렬
## sensor_sum 데이터를 내림차순으로 정렬 후 sensor_sort 변수에 할당합니다.
## sensor_sum 을 데이터프레임 으로 생성했을 경우 기준(by=)을 지정해 주어야 합니다.
sensor_sort = sensor_sum.sort_values(ascending=False)
sensor_sort
5] 중요도 시각화
# 센서별 중요도 시각화
# sensor 별 중요도를 수평막대 그래프로 시각화 합니다.
plt.barh(y=sensor_sort.index, width=sensor_sort)
plt.xticks(rotation = 90)
plt.grid()
plt.show()
# sensor_sort가 데이터프레임 시
# plt.barh(data = sensor_sort, y=sensor_sort.index, width='feature_importance')
# plt.xticks(rotation = 90)
# plt.grid()
# plt.show()
최종결과 저장
모델 별 accuracy_score, f1_score 지수를 수직 그래프로 시각화
(1) 시각화
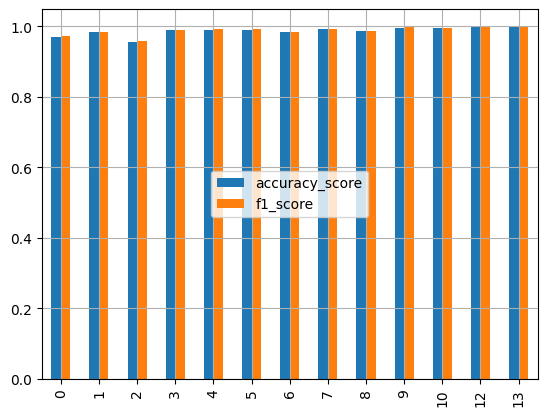
# 최종결과 결과 시각화
# 모델 별 accuracy_score, f1_score 지수를 수직 그래프로 시각화 하세요.
result.plot(kind='bar')
plt.grid()
plt.legend(loc='center')
plt.show()
(2) 저장
# 최종결과 저장
## 최종 결과(result)를 'final_result.csv' 파일로 저장해 주세요.
## 영향도가 높은 feature 들의 이름을 모아놓은 변수를 'up_importance_top.csv' 파일로 저장해 주세요.
result.to_csv("final_result.csv")
up_importance_top.to_csv("up_importance_top.csv")'WORKING_UPSTAIRS' 분류에 영향을 미치는 상위 20 agg 찾기
1] 데이터 그룹화
# 데이터 그룹화
## merge_df 변수를 ['sensor','agg'] 기준으로 그룹화 하면서 'feature_importance' 열의 데이터를 더해 줍니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 계산을 동시에 수행할 수 있습니다.
sensor_agg_sum = merge_df.groupby(['sensor','agg'])['feature_importance'].sum()
sensor_agg_sum
2] sensor_agg 중요도별 데이터 재정렬
# sensor_agg 중요도 별 데이터 재정렬
## sensor_agg_sum 데이터를 내림차순으로 정렬 후 sensor_agg_sort 변수에 할당합니다.
sensor_agg_sort = sensor_agg_sum.sort_values(ascending=False)
sensor_agg_sort
# sensor_agg_sort 변수를 데이터프레임으로 생성시
# sensor_agg_sort = sensor_agg_sum.sort_values(by='feature_importance', ascending=False)
# sensor_agg_sort
3] 중요도 Top20 acc 시각화
# 중요도 Top20 acc 시각화
## 중요도가 높은 센서 20개의 중요도를 수평 막대그래프로 시각화 합니다.
sensor_agg_sort[:20].plot(kind='barh')
plt.grid()
plt.show()
'sensor'를 구성하고있는 'agg' 시각화
1] 데이터 재구조화
# sensor_agg_sort 데이터 재 구조화
# sensor_agg_sort 데이터의 'agg'열의 고유값을 sensor_agg_sort 데이터의 컬럼으로 변환(재구조화) 합니다.
# 재구조화 한 데이터를 acc 변수에 할당 합니다.
# 참고함수: unstack()
acc = sensor_agg_sort.unstack()
acc
2] 재정렬
# 센서별 합계 재정렬
## acc 데이터의 각 센서의 행 기준(axis=1) 모든 값을 더해서 acc['sort'] 에 할당 합니다.
## 할당 후 acc 데이터를 acc['sort'] 열의 값 기준으로 내림차순으로 정렬 합니다.
## 정렬 후 데이터를 확인 합니다.
acc['sort'] = acc.sum(axis=1)
acc.sort_values(by = 'sort', ascending = False, inplace=True)
acc
3] 정렬 기준열 제거
# 정렬 기준열 제거
# 센서별 정렬을 완료 했으므로 acc 변수에서 acc['sort']열을 삭제 합니다.
acc.drop('sort', axis=1, inplace=True)
acc
4] 누적 막대 그래프 시각화
# 누적 막대 그래프 시각화
# acc 변수를 sensor 별 수평 그래프로 시각화 합니다.
acc.plot(kind='barh', stacked=True, figsize=(20,15))
plt.grid()
plt.show()

Activity 예측
1] real_data 뱐수에 할당
## real_data.csv 파일을 불러와서 real_data 변수에 할당 합니다.
## 잘 할당 되었는지 데이터 확인
real_data = pd.read_csv('./data/real_data.csv')
real_data
2] 불필요 컬럼 제거
## real_data 변수(데이터셋)에서 행동분류에 불필요한 'subject'열 제거한 데이터를 real_x_val 변수에 할당 합니다.
## 나중에 예측 결과를 real_data 데이터 프레임에 병합해서 결과를 확인해야 하므로 real_data 변수에서 'subject'열 제거하지 마세요.
real_x_val = real_data.drop('subject', axis=1)
real_x_val
3] real_x_val 데이터에서 최고의 성능을 내는 학습 feature 데이터를 real_x_top 변수에 할당
## real_x_val 데이터에서 최고의 성능을 내는 학습 feature 데이터를 real_x_top 변수에 할당합니다.
## Feature Selection 된 상위 중요 feature 명 리스트는 up_importance_top 변수를 사용 합니다.
real_x_top = real_x_val[up_importance_top]
4] walkingup_top 모델로 real_x_top 데이터의 'WALKING_UPSTAIRS' 행동분류 예측해서 real_walkingup_pred 변수에 할당
## walkingup_top 모델로 real_x_top 데이터의 'WALKING_UPSTAIRS' 행동분류 예측해서 real_walkingup_pred 변수에 할당 합니다.
real_walkingup_pred = walkingup_top_model.predict(real_x_top)
real_walkingup_pred
5] real_data['WALKING_UPSTAIRS'] 열에 real_walkingup_pred 예측 결과를 할당 하고, 데이터를 확인
## real_data['WALKING_UPSTAIRS'] 열에 real_walkingup_pred 예측 결과를 할당 하고, 데이터를 확인 합니다.
real_data['WALKING_UPSTAIRS'] = real_walkingup_pred
real_data
6] 인덱스 미포함 real_data 변수를 real_result.csv 파일로 저장
# 인덱스 미포함 real_data 변수를 real_result.csv 파일로 저장 합니다.
real_data.to_csv('real_result.csv', index=False)
7] 저장 되었는지 확인
# 잘 저장 되었는지 확인 합니다.
pd.read_csv('real_result.csv')