728x90


728x90
'프로젝트, 공모전 > 프로젝트_공공데이터분석' 카테고리의 다른 글
| 프로젝트_스터디] 한국수자원공사_실시간 수도정보 수질(시간) 조회 서비스(GW) (2) | 2023.11.18 |
|---|---|
| 프로젝트_스터디] 집계구별 일별소비지역별 카드소비패턴 분석 (0) | 2023.09.06 |
| 프로젝트_스터디] 한국수자원공사_실시간 수도정보 수질(시간) 조회 서비스(GW) (2) | 2023.11.18 |
|---|---|
| 프로젝트_스터디] 집계구별 일별소비지역별 카드소비패턴 분석 (0) | 2023.09.06 |
- 실시간 수질 정보 조회 및 생활 용수와 공업 용수의 상태 파악
- 민간 및 기업에 모두 유용한 데이터를 제공하는 것
한국수자원공사_실시간 수도정보 수질(시간) 조회 서비스(GW)


from datetime import datetime
from datetime import timedelta
import pandas as pd
import requests
import pprint
from os import name
import pandas as pd
import bs4

http://apis.data.go.kr/B500001/rwis/waterQuality/list
| 항목명(영문) | 항목명(국문) | 항목크기 | 항목구분 | 샘플데이터 | 항목설명 |
| stDt | 조회시작일자 | 10 | 1 | 2015-11-18 | 조회시작일자 |
| stTm | 조회시작시간 | 2 | 1 | 00 | 조회시작시간 |
| edDt | 조회종료일자 | 10 | 1 | 2015-11-18 | 조회종료일자 |
| edTm | 조회종료시간 | 2 | 1 | 24 | 조회종료시간 |
| fcltyMngNo | 시설관리번호 | 10 | 0 | 4824012333 | 시설관리번호 |
| sujCode | 사업장코드 | 3 | 0 | 333 | 사업장코드 |
| liIndDiv | 생활공업구분 | 1 | 0 | 1 | 생활:1, 공업:2 |
| numOfRows | 줄수 | 10 | 0 | 10 | 줄수 |
| pageNo | 페이지번호 | 10 | 0 | 1 | 페이지번호 |
※ 항목구분 : 필수(1), 옵션(0), 1건 이상 복수건(1..n), 0건 또는 복수건(0..n)
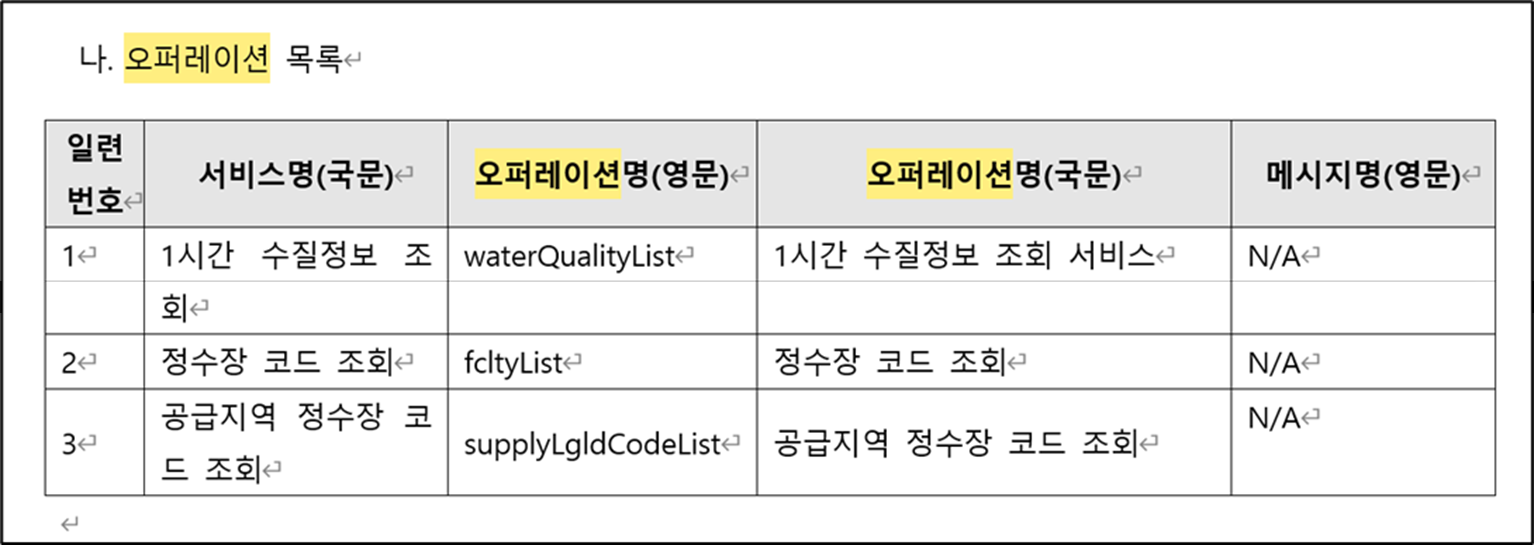
1) 1시간 수질정보 조회 waterQualityList
2) 정수장 코드 조회 fcltyList
3) 공급지역 정수장 코드 조회 supplyLgldCodeList
http://apis.data.go.kr/B500001/rwis/waterQuality/list/waterQualityList
http://apis.data.go.kr/B500001/rwis/waterQuality/list/fcltyList
http://apis.data.go.kr/B500001/rwis/waterQuality/list/supplyLgldCodeList
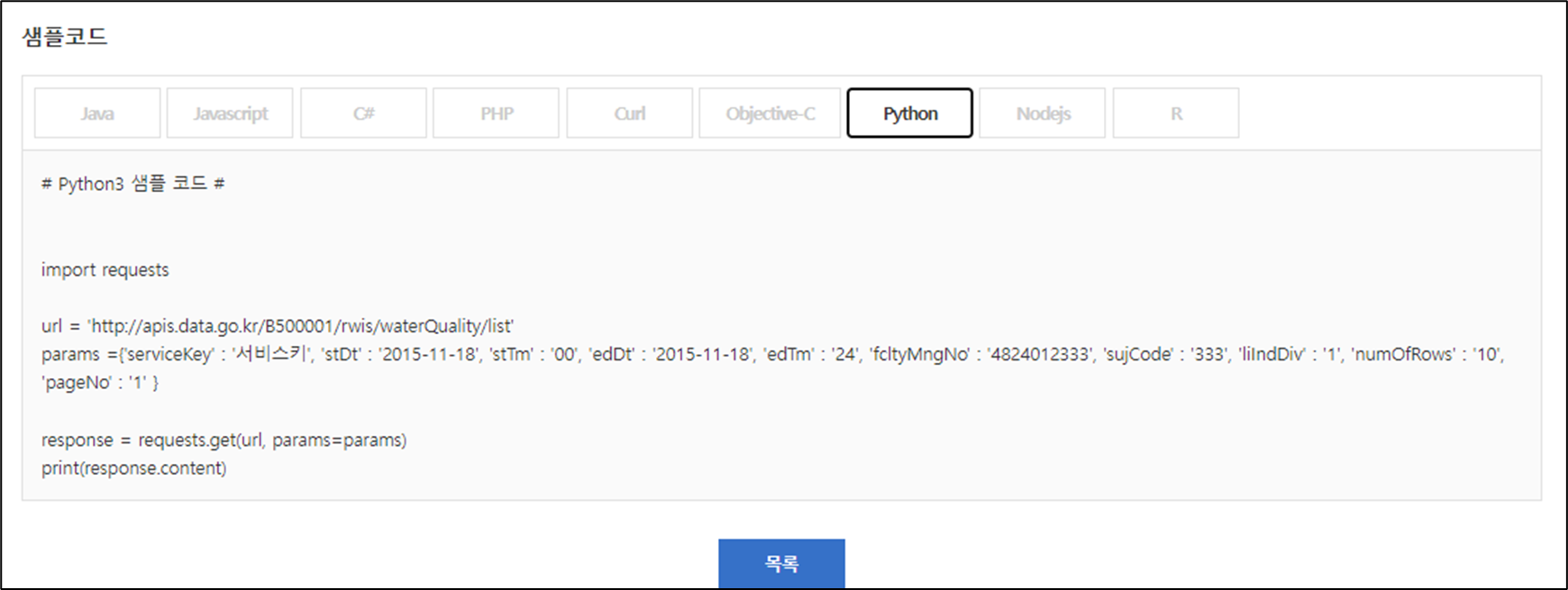
import requests
url = 'http://apis.data.go.kr/B500001/rwis/waterQuality/list'
params ={'serviceKey' : '서비스키', 'stDt' : '2015-11-18', 'stTm' : '00', 'edDt' : '2015-11-18', 'edTm' : '24', 'fcltyMngNo' : '4824012333', 'sujCode' : '333', 'liIndDiv' : '1', 'numOfRows' : '10', 'pageNo' : '1' }
response = requests.get(url, params=params)
print(response.content)
from datetime import datetime
from datetime import timedelta
print(datetime.today())
print(datetime.today().strftime("%Y-%m-%d %H:%M:%S"))
print(datetime.today().strftime("%Y-%m-%d"))
five_years_ago = datetime.today() - timedelta(days = 5*365)
five_years_ago.strftime("%Y-%m-%d")
import pandas as pd
import requests
import pprint
decoding_key = '디코딩_key'
url = 'http://apis.data.go.kr/B500001/rwis/waterQuality/list'
# params ={'serviceKey' : '서비스키',
# 'stDt' : '2015-11-18',
# 'stTm' : '00',
# 'edDt' : '2015-11-18',
# 'edTm' : '24',
# 'fcltyMngNo' : '4824012333',
# 'sujCode' : '333',
# 'liIndDiv' : '1',
# 'numOfRows' : '10',
# 'pageNo' : '1' }
params ={'serviceKey' : decoding_key,
'stDt' : five_years_ago.strftime("%Y-%m-%d"), # 조회시작일자
'stTm' : '00', # 조회시작시간
'edDt' : datetime.today().strftime("%Y-%m-%d"), # 조회종료일자
'edTm' : '24', # 조회종료시간
'fcltyMngNo' : '4824012333' # 시설관리번호
# 'sujCode' : '333' # 사업장코드
# 'liIndDiv' : '1' # 생활공업구분
# 'numOfRows' : '10' # 줄수
# 'pageNo' : '1' # 페이지번호
}response = requests.get(url, params=params)
# xml 내용
content = response.text
print('content',content)
# 깔끔한 출력 위한 코드
pp = pprint.PrettyPrinter(indent=4)
print('pp', pp)
### xml을 DataFrame으로 변환하기 ###
from os import name
import pandas as pd
import bs4
#bs4 사용하여 item 태그 분리
xml_obj = bs4.BeautifulSoup(content,'lxml-xml')
print('xml_obj', xml_obj)
rows = xml_obj.findAll('item')
print(rows)
# 각 행의 컬럼, 이름, 값을 가지는 리스트 만들기
row_list = [] # 행값
name_list = [] # 열이름값
value_list = [] #데이터값
# xml 안의 데이터 수집
for i in range(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집
for j in range(0,len(columns)):
if i ==0:
# 컬럼 이름 값 저장
name_list.append(columns[j].name)
# 컬럼의 각 데이터 값 저장
value_list.append(columns[j].text)
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]
#xml값 DataFrame으로 만들기
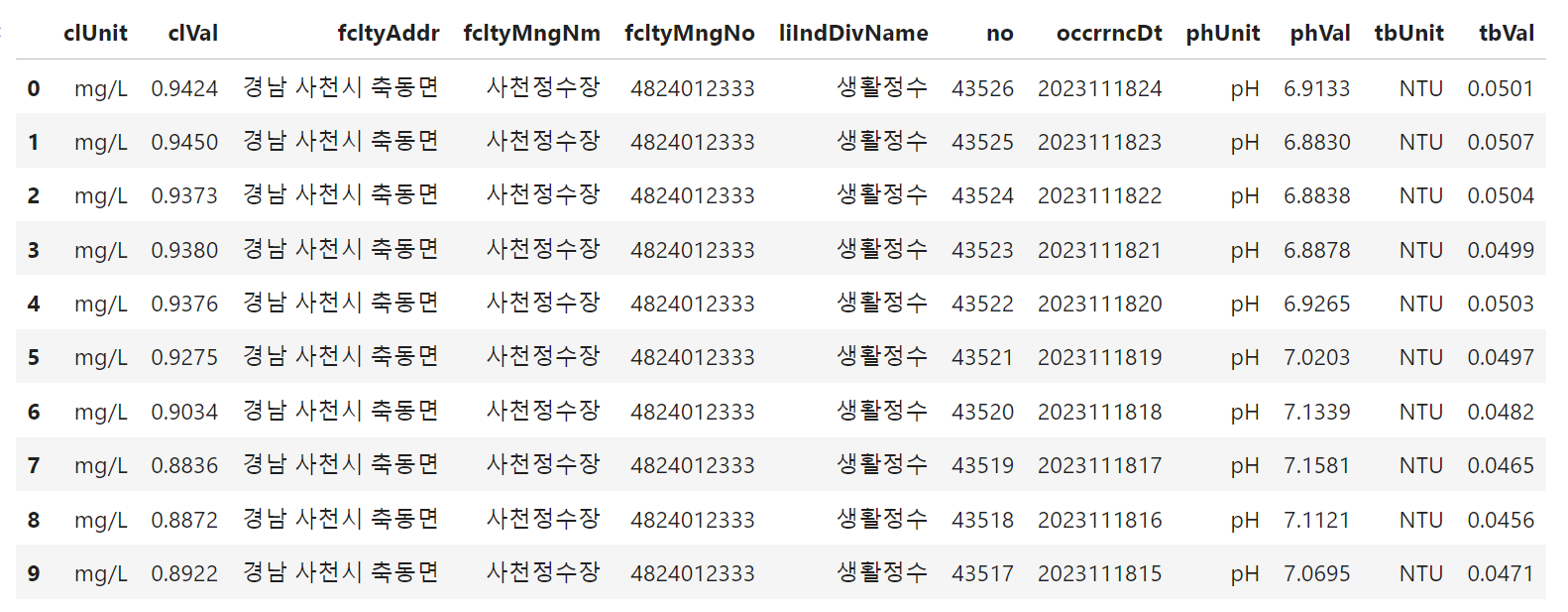
water_df = pd.DataFrame(row_list, columns=name_list)
print(water_df.head(19))
#xml값 DataFrame으로 만들기
#Assertion Error가 난 경우
water_df = pd.DataFrame(water_df)
# 이후에 컬럼을 설정해 주세요.
water_df
- 필수 parameter 정보 불일치
- 예제와 다른 경우의 데이터를 추출하기 어렵다.
공공데이터 포털에서는 활용 많은 순으로 데이터를 활용할 것
| 프로젝트_스터디] 주제_실시간_활용_많은_순서 (0) | 2023.11.19 |
|---|---|
| 프로젝트_스터디] 집계구별 일별소비지역별 카드소비패턴 분석 (0) | 2023.09.06 |
LinearRegression
KNeighborsRegressor
DecisionTreeRegressor
RandomForestRegressor
XGBRegressor
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# x, y 분리
# medv : 본인 소유 주택 가
target = 'medv'
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 학습용, 평가용 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=1)
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_absolute_error, r2_score
model_dt = DecisionTreeRegressor(random_state=1)
# 성능예측
cv_score = cross_val_score(model_dt, x_train, y_train, cv=5)
# 결과 확인
print(cv_score)
print(cv_score.mean())
from sklearn.tree import DecisionTree
from skelarn.model_selection import RandomizedSearchCV

# max depth : 1~50
params = {'max_depth' : range(1,50)}
model_dt = DecisionTreeRegressor(random_state)
model = RandomizeCV(nidek_dt,
param,
cv =5,
n_iter = 20,
scoring = 'r2')
# 결과 확인
** model.cv_results_['mean_test_score'] : 테스트로 얻은 성능
** model.best_parms_ : 최적의 파라미터
** model.best_score_ : 최고 성능
print(model.cv_results_['mean_test_score'])
print('최적 파라미터:', model.best_params_)
print('최고 성능:', model.best_score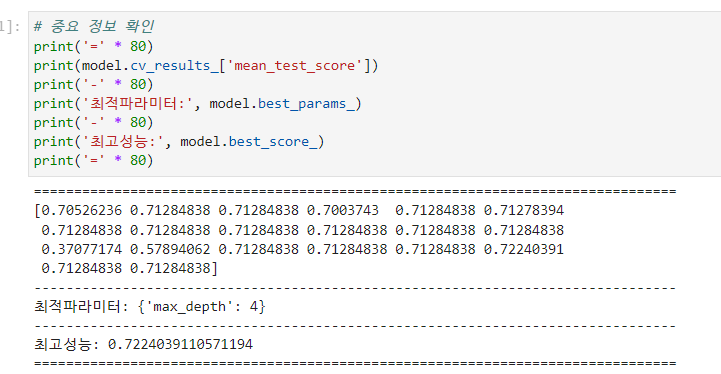
## model.best_estimator_
plt.barh( y = list(x), width = model.best_estimator_.feature_importances_) # 최선의 파라미터로 된 DecisionTree이다.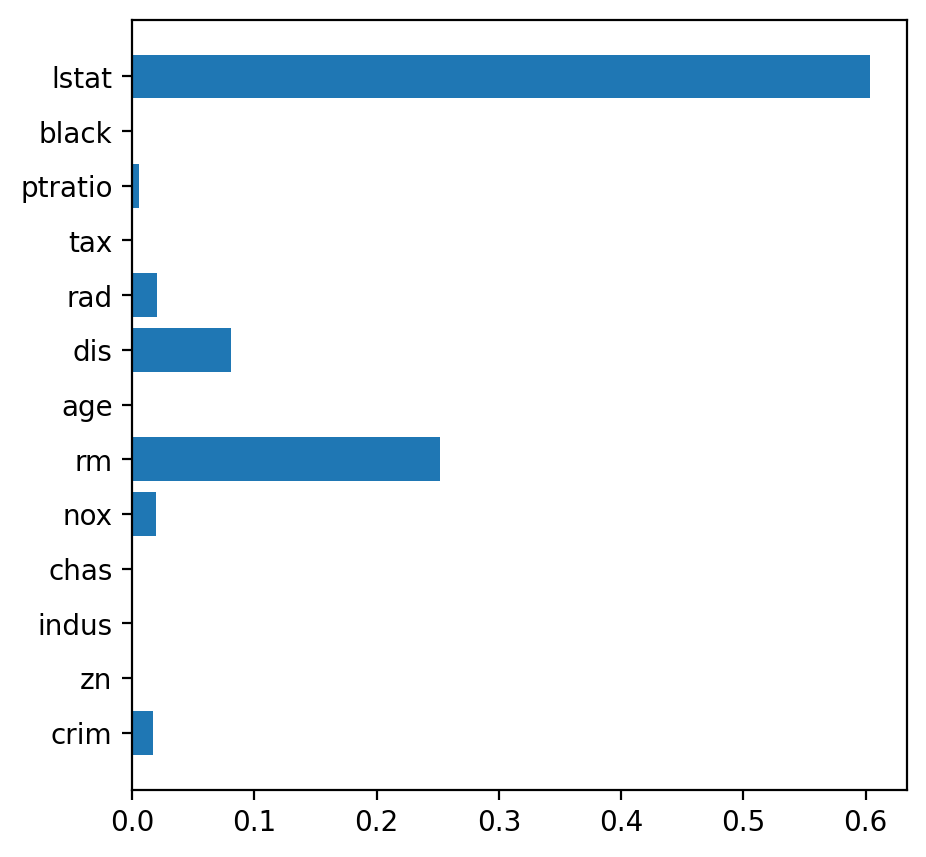
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |
| import pandas as pd import maplotlib.pyplot as plt import os os.listdir(os.getcwd()) |
|
| data1 = pd.read_csv('기업정보요약_train.csv', encoding='UTF - 8') display(data1)  |
|
| data10 = pd.read_csv('재무제표정보_train.csv',encoding = 'UTF - 8') display(data10)  |
| # 결합하고 중소기업 정보 남기 data_small = pd.merge(data1, data10, on='BusinessNum', how = 'left' ) data_small = data_small.loc[ data['cpmSclNm'] =='중소기업'] data_small = data_small[ ['BusinessNum', '기업명', 'cmpSclNm', 'accNm', 'acctAmt']] data_small |
|
 |
display(data_small['accNm'].value_counts()
| 데이터분석_공모전_DBI] 기법 정리 DecisionTreeRegressor & Random Search (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |
| 1) 라이브러리 로딩 import pandas as pd import numpy as np import matplotlib.pyplt as plt import sklearn as sns 2) 군집모델 만들기 model = KMeans(n_clusters = 2, init='auto') model.fit(x) pred = model.predict(x) pred = pd.DataFrame(pred, columns = ['predicted']) # 모델의 중심 좌표 얻기 centers = pd.DataFrame(model.cluster_centers_, columns = ['x1', 'x2']) plt.scatter(result['x1'], result['x2'], c=result['predicted'], alpha=0.5) plt.scatter(centers['x1'], centers['x2'], s=50, marker='D', c='r') |
|
 |
|
| # k means 모델을 생성하게 되면 inertia 값을 확인 가능 model.inertia_ # k를 증가시켜가면서 inertia 구하기 kvalues = range(1,10) inertias = [] for k in kvalues: model = KMeans(n_clusters=k, n_init = 'auto') model.fit(x) inertias.append(model.inertia_) plt.plot(kvalues, inertias, '-o') plt.xlabel('number of clusters, k') plt.ylabel('inertia') plt.grid() plt.show() |
|
 |
|
| import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.cluster import KMeans from sklearn,preprocessing import MinMaxScaler |
|
| # 군집화 할 변수 선택 x = data.loc[:, ['Age', 'Income', 'Score' ] ] |
|
 |
|
| 스케일링 scaler = MinMaxScaler() x_s = scaler.fit_transform(x) # k값을 늘려가면서(1~20) 모델을 만들어, inertia 값을 저장 # 그래프를 통해 최적의 k값 결정 # 반복문으로 KMeans 모델 kvalues = range(1,21) iv = [] for k in kvalues: model = KMeans(n_clusters = k, n_init='auto') model.fit(x_s) iv.append(model.inertia_) # 그래프 그려서 적절한 k값 찾기 plt.plot(kvalues, iv, marker='.') plt.grid() |
|
 |
|
| # 적절한 k 찾으면 모델 선언 model = KMeans(n_clusters=5, n_init = 'auto', random_state=10) |
|
 |
| # 'Age', 'Income', 'Score', 'pred'만 추출 temp = result.loc[:, ['Age', 'Income', 'Score', 'pred' ]] sns.pairplot(temp, hue = 'pred') plt.show() |
|
 |
| 데이터분석_공모전_DBI] 기법 정리 DecisionTreeRegressor & Random Search (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |


import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font',family='Malgun Gothic')
plt.rcParams['font.family']
gu = pd.read_csv('집계구별 일별소비지역별 카드소비패턴.csv',encoding='CP949')
gu_seoul = gu.loc[gu['가맹점주소광역시도(SIDO)']=='서울' , ['가맹점주소시군구(SGG)','업종대분류(UPJONG_CLASS1)','카드이용건수계(USECT_CORR)','카드이용금액계(AMT_CORR)']]
# display(gu_seoul[gu_seoul['가맹점주소시군구(SGG)']=='강남구'])
gu_gangnam = gu_seoul[gu_seoul['가맹점주소시군구(SGG)']=='강남구']
gu_gangnam_use = gu_gangnam.groupby(by='업종대분류(UPJONG_CLASS1)', as_index=False)[['카드이용건수계(USECT_CORR)']].sum()
# display(gu_gangnam_use)
# display(gu_gangnam_use.info())
gu_gangnam_money = gu_gangnam.groupby(by='업종대분류(UPJONG_CLASS1)', as_index=False)[['카드이용금액계(AMT_CORR)']].sum()
# display(gu_gangnam_money)
# plt.pie(데이터프레임['컬럼명'].values, labels = 데이터프레임['컬럼명'].index(), autopct='%.2f%%')
plt.figure(figsize = (10,10))
plt.subplot(1,2,1)
plt.pie(gu_gangnam_use['카드이용건수계(USECT_CORR)'].values, labels=gu_gangnam_use['업종대분류(UPJONG_CLASS1)'] )
plt.legend(loc='upper left')
plt.title('강남에서 카드이용건수계 비율')
plt.subplot(1,2,2)
plt.pie(gu_gangnam_money['카드이용금액계(AMT_CORR)'].values, labels= gu_gangnam_money['업종대분류(UPJONG_CLASS1)'])
plt.legend(loc='upper left')
plt.title('강남에서 카드이용금액계 비율')
plt.tight_layout()

import numpy as np
import pandas as pd
pd.set_option('display.float_format', lambda x:'%.3f'%x) # 지수 표현 없애기
import matplotlib.pyplot as plt
plt.rc('font',family = 'Malgun Gothic')
plt.rcParams['font.family']
import seaborn as sns
import scipy.stats as spst
sobi = pd.read_csv( '집계구별 일별소비지역별 카드소비패턴.csv', encoding ='CP949')
sobi_year = sobi.loc[:,['기준일자(YMD)','카드이용금액계(AMT_CORR)']]
sobi_year['기준일자(YMD)'] = sobi_year['기준일자(YMD)'].astype('str')
sobi_year['기준일자(YMD)'] = sobi_year['기준일자(YMD)'].str[:4]
A= sobi_year.loc[sobi_year['기준일자(YMD)']=='2016','카드이용금액계(AMT_CORR)']
B= sobi_year.loc[sobi_year['기준일자(YMD)']=='2017','카드이용금액계(AMT_CORR)']
C= sobi_year.loc[sobi_year['기준일자(YMD)']=='2018','카드이용금액계(AMT_CORR)']
D= sobi_year.loc[sobi_year['기준일자(YMD)']=='2019','카드이용금액계(AMT_CORR)']
E= sobi_year.loc[sobi_year['기준일자(YMD)']=='2020','카드이용금액계(AMT_CORR)']
display(spst.ttest_ind(D,E))
# print('\n','='*100,'\n21년도의 마지막 값은 7월에서 끝나므로 21년도는 뺀다',sep='')
# < 특정 행 삭제 >
sobi_year.drop( sobi_year[ sobi_year['기준일자(YMD)'].str.contains('2021')].index, inplace = True )
feature = '기준일자(YMD)'
target = '카드이용금액계(AMT_CORR)'
# sns.barplot(x='컬럼명', y='컬럼명', data=데이터프레임)
sobi_year[feature] = sobi_year[feature].astype('int')
sns.barplot(x=feature, y= target, data=sobi_year )

import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font',family='Malgun Gothic')
plt.rcParams['font.family']
import scipy.stats as spst
import seaborn as sns
spend = pd.read_csv('집계구별 일별소비지역별 카드소비패턴.csv', encoding = 'CP949')
spend_area = spend.loc[:,['가맹점주소광역시도(SIDO)','카드이용금액계(AMT_CORR)']]
print('\n','='*100,'\n큰 단위로 나누기',sep='')
spend_area['가맹점주소광역시도(SIDO)'] = spend_area['가맹점주소광역시도(SIDO)'].replace({
'서울':'수도권',
'경기':'수도권',
'인천':'수도권',
'대전':'충청도',
'충남':'충청도',
'충북':'충청도',
'세종':'충청도',
'광주':'전라도',
'전남':'전라도',
'전북':'전라도',
'부산':'경상도',
'경북':'경상도',
'경남':'경상도',
'대구':'경상도'
})
feature = '가맹점주소광역시도(SIDO)'
target = '카드이용금액계(AMT_CORR)'
plt.title('도별와 카드이용금액의 관계 < 범주 & 숫자 >')
sns.barplot(x=feature, y=target, data=spend_area)| 프로젝트_스터디] 주제_실시간_활용_많은_순서 (0) | 2023.11.19 |
|---|---|
| 프로젝트_스터디] 한국수자원공사_실시간 수도정보 수질(시간) 조회 서비스(GW) (2) | 2023.11.18 |
https://data.seoul.go.kr/dataList/543/S/2/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr


import numpy as np
import pandas as pd
import csv
import matplotlib.pyplot as plt
data = pd.read_csv('./csv/교원+1인당+학생수(구별)_20230820151017.csv', index_col=0)
data_re = data.rename(columns=data.iloc[0])
data_re = data_re.drop(data.index[0])
data_re
print(data_re)
school_sort = list(set(list(data_re.index)))
print("\n\n학교 종류")
print(school_sort)
blank = []
for i in school_sort:
a = data_re[data_re.index.str.contains(i)]
gyo = pd.DataFrame(a.loc[:,'교원1인당학생수'])
gyo_nu = pd.to_numeric(gyo['교원1인당학생수'])
gyo_nu_mean = gyo_nu.mean()
blank.append(gyo_nu_mean)
print('\n\n')
print(blank)
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
plt.bar(school_sort, blank)
plt.show()
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |
| 데이터분석_공모전_서울교육] 인구 구조 시각화_행정안전부 인구 데이터 (0) | 2023.08.19 |
서울교육 데이터 활용 아이디어 공모전
home keyboard_arrow_right 공고안내 description 공고안내 서울특별시교육청에서는 서울교육 데이터 활용 아이디어 발굴을 통해 공공데이터 활용을 촉진하고, 시민 누구나 교육정책에 참여하는 기회 제
www.senbigdata.com

공공데이터 사이트
공공데이터포털 데이터셋
서울열린데이터광장
나이스교육정보개방
https://open.neis.go.kr/portal/mainPage.do
나이스 교육정보 개방 포털
OPEN API 활용신청 제공되는 데이터를 활용하기 위해 인증키를 발급 받으세요. 교육정보개방 소개 <!-- 2017.10.25 kty 정부3.0제거 교육부 정부 3.0 - 교육정보 개방 포털은 어떤 시스템인지 알아보세요.
open.neis.go.kr
교육통계서비스
유치원알리미
https://e-childschoolinfo.moe.go.kr/
유치원 알리미
유아 · 교직원 현황, 유치원 회계 현황, 환경위생 및 안전관리 사항 등 유치원의 주요 정보
e-childschoolinfo.moe.go.kr
학교알리미
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |
| 데이터분석_공모전_서울교육] 인구 구조 시각화_행정안전부 인구 데이터 (0) | 2023.08.19 |
import numpy as np
import pandas as pd
import os
print(os.getcwd())
print(os.listdir(os.getcwd()))
print(os.listdir('./csv'))

csv 파일들은 편의를 위해 csv 폴더에 따로 모아두기
https://www.data.go.kr/index.do
https://www.data.go.kr/data/15080794/fileData.do


import csv
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
for row in data:
print(row)
import csv
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
for row in data:
a=0
print(f"* 첫째 행 구성요소 : {row}")
print(f"* 행 길이 : {len(row)}")
for i in row:
print(f"{a}번째 값 : {i}")
a+=1
break
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
cp949 : 한글 표현하기 위함
index_col = 0 : 불필요한 인덱스 제거 역할
index_col = 0 입력

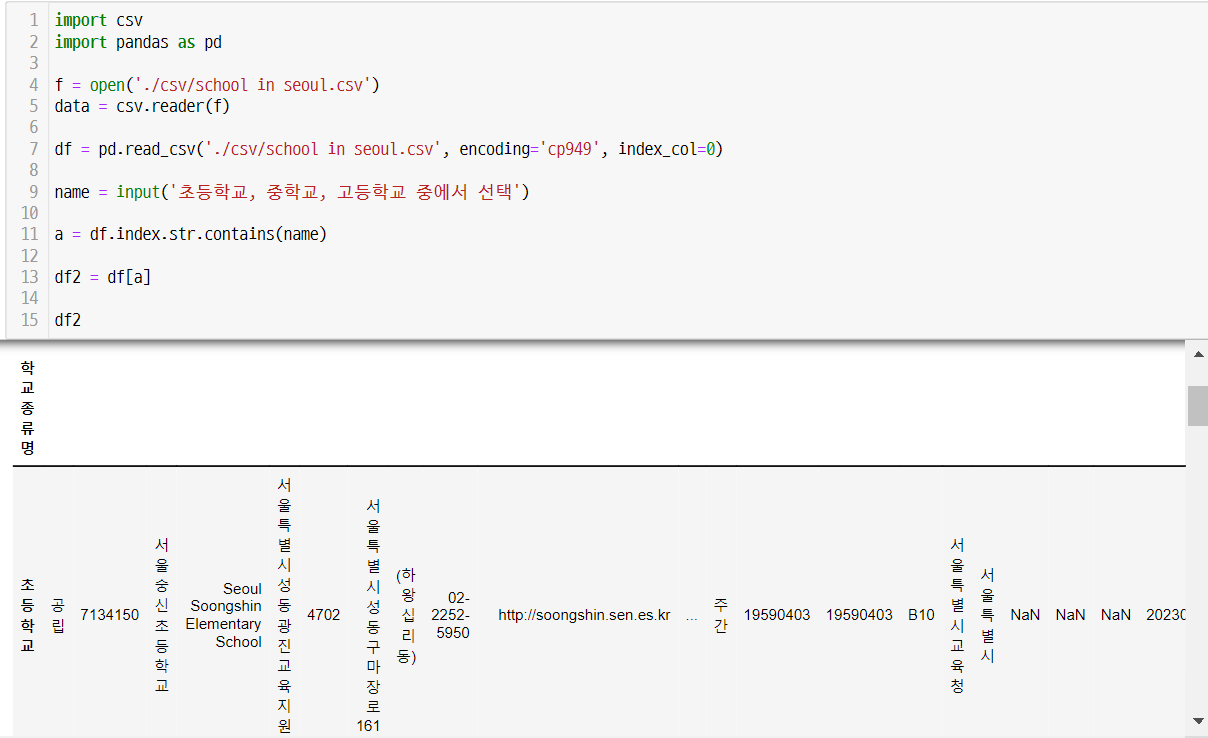
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
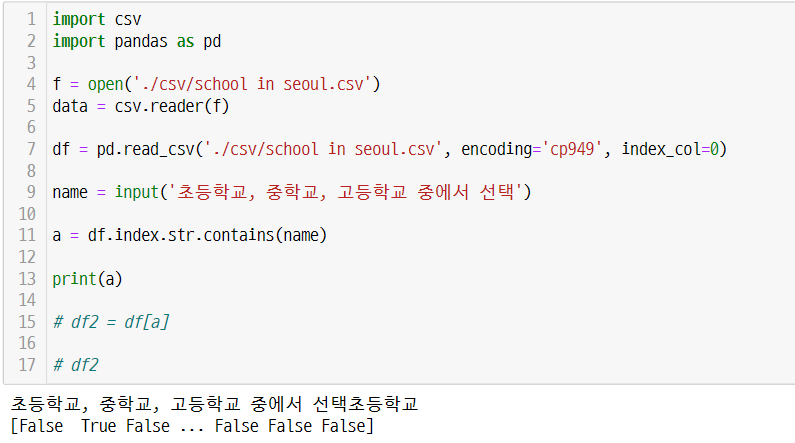
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
name = input('초등학교, 중학교, 고등학교 중에서 선택')
a = df.index.str.contains(name)
df2 = df[a]
df2
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df_cho = df[df.index.str.contains("초등학교")]
df_jung = df[df.index.str.contains("중학교")]
df_go = df[df.index.str.contains("고등학교")]
print(f"전체 학교 수 : {df.shape[0]}")
print(f"초등학교 수 : {df_cho.shape[0]}")
print(f"중학교 수 : {df_jung.shape[0]}")
print(f"고등학교 수 : {df_go.shape[0]}")
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df
print(f"행 개수 : {df.shape[0]} 열 개수 : {df.shape[1]}")
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
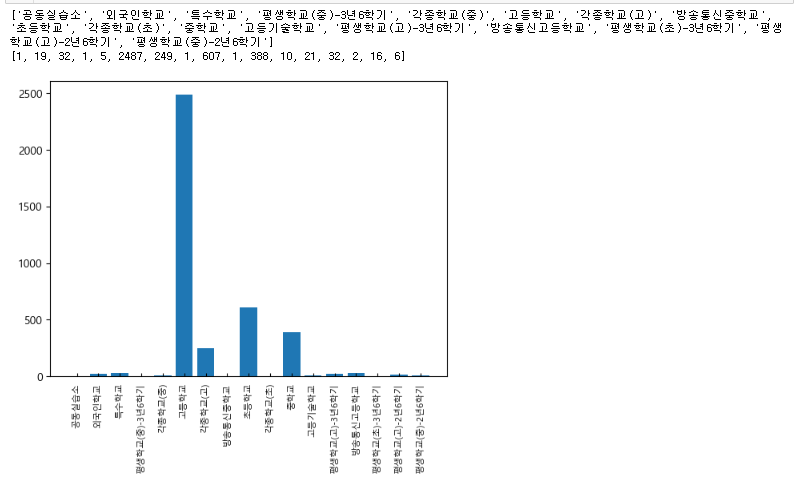
index_info = list(set(df.index.to_list()))
print(index_info)
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
index_info = list(set(df.index.to_list()))
print(f" index_info {index_info}\n\n")
a=[]
for i in index_info:
# 정확한 일치 개수를 세는 방식으로 변경
count = (df.index==i).sum()
print(f"{i}: {count}")
a.append(count)
print('\n\n',a,'\n\n')
print(sum(a),'\n\n')


import matplotlib.pyplot as plt
print(index_info)
print(a)
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
plt.bar(index_info,a)
plt.xticks(rotation=90)
plt.tick_params(axis='x', direction='in', length=3, pad=6, labelsize=8, labelcolor='black')
plt.show()
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
import numpy as np
import pandas as pd
import os
import csv
import matplotlib.pyplot as plt
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
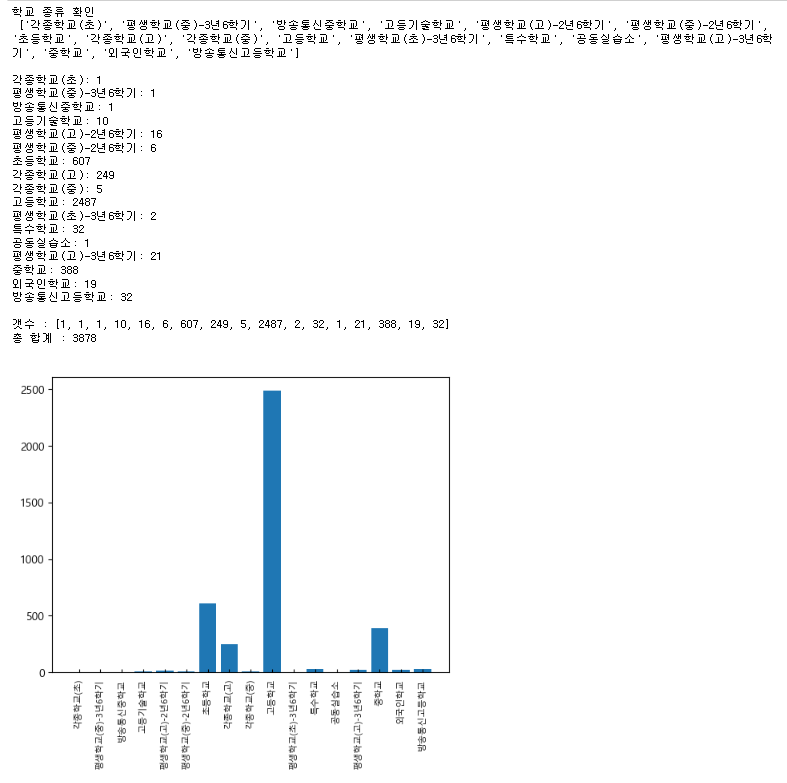
kind = list(set(df.index.to_list()))
print(f"학교 종류 확인\n {kind}\n")
numbers =[]
for i in kind:
count = (df.index==i).sum()
print(f"{i}: {count}")
numbers.append(count)
# print(df)
print(f"\n갯수 : {numbers}")
print("총 합계 :",sum(numbers),"\n")
plt.rcParams['font.family'] ='Malgun Gothic'
plt.rcParams['axes.unicode_minus'] =False
plt.bar(kind,numbers)
plt.xticks(rotation=90)
plt.tick_params(axis='x', direction='in', length=3, pad=6, labelsize=8, labelcolor='black')
plt.show()
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 인구 구조 시각화_행정안전부 인구 데이터 (0) | 2023.08.19 |