728x90
기법 정리 DecisionTreeRegressor & Random Search
회귀 문제
LinearRegression
KNeighborsRegressor
DecisionTreeRegressor
RandomForestRegressor
XGBRegressor
DecisionTree, Random Search

1) 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
2) 데이터 준비
# x, y 분리
# medv : 본인 소유 주택 가
target = 'medv'
x = data.drop(target, axis=1)
y = data.loc[:, target]
# 학습용, 평가용 데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=1)
3) DecisionTreeRegressor
from sklearn.tree import DecisionTreeRegressor
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_absolute_error, r2_score
model_dt = DecisionTreeRegressor(random_state=1)
# 성능예측
cv_score = cross_val_score(model_dt, x_train, y_train, cv=5)
# 결과 확인
print(cv_score)
print(cv_score.mean())
4) 모델 튜닝
from sklearn.tree import DecisionTree
from skelarn.model_selection import RandomizedSearchCV# max depth : 1~50
params = {'max_depth' : range(1,50)}
model_dt = DecisionTreeRegressor(random_state)
model = RandomizeCV(nidek_dt,
param,
cv =5,
n_iter = 20,
scoring = 'r2')
# 결과 확인
** model.cv_results_['mean_test_score'] : 테스트로 얻은 성능
** model.best_parms_ : 최적의 파라미터
** model.best_score_ : 최고 성능
print(model.cv_results_['mean_test_score'])
print('최적 파라미터:', model.best_params_)
print('최고 성능:', model.best_score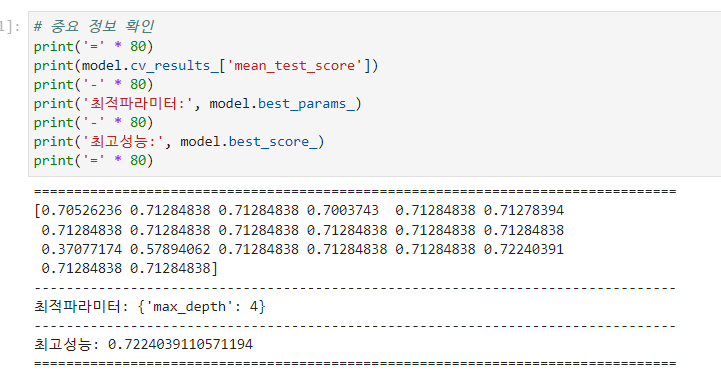
# 변수 중요도
## model.best_estimator_
plt.barh( y = list(x), width = model.best_estimator_.feature_importances_) # 최선의 파라미터로 된 DecisionTree이다.
728x90
'프로젝트, 공모전 > 프로젝트 공모전_데이터 분석' 카테고리의 다른 글
| 데이터분석_공모전_DBI] 데이터 분석 (0) | 2023.09.23 |
|---|---|
| 데이터분석_공모전_DBI] 기법 정리 K-means (0) | 2023.09.23 |
| 데이터 분석_공모전_서울교육] 교직원 1인당 학생 수 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 공공데이터 활용 (0) | 2023.08.20 |
| 데이터분석_공모전_서울교육] 서울 학교 데이터 분석 (0) | 2023.08.19 |