# 1. 타이틀과 캡션 표시하기
# 타이틀 : Covid-19 감염현황
# 캡션 : Displaying geographical data on a map using Streamlit and Folium
st.title('Covid-19 감염현황')
st.caption('Displaying geographical data on a map using Streamlit and Folium')
# 2. checkbox를 이용하여 checkbox 선택여부에 따라
# write 코드를 사용하여 화면에 데이터프레임 값 나타내기
if st.checkbox('Display Data'):
st.write(map_data)
# folium.Map(): Folium에서 지도 객체를 생성
# location: 지도가 초기에 어떤 위치에서 시작할지를 정의
# map_data['lat'].mean()과 map_data['lon'].mean(): 평균 위도와 경도 위치를 지도 중심으로 설정
# zoom_start: 이 매개변수는 지도의 초기 확대 수준 (default=10, 숫자가 클수록 확대)
my_map = folium.Map( location=[map_data['lat'].mean(), map_data['lon'].mean()], zoom_start=3 )
# 지도에 원형 마커와 값 추가
for index, row in map_data.iterrows(): # 데이터프레임 한 행 씩 index, row에 담아서 처리
folium.CircleMarker( # 원 표시 선언
location=[row['lat'], row['lon']], # 원 중심- 위도, 경도
radius=row['value']/10000, # 원의 반지름 /10000
color='pink', # 원의 테두리 색상
fill=True, # 원을 채움
fill_opacity=0.8 # 원의 내부를 채울 때의 투명도
).add_to(my_map) # my_map에 원형 마커 추가
folium.Marker( # 값 표시 선언
location=[row['lat'], row['lon']], # 값 표시 위치- 위도, 경도
icon=folium.DivIcon(html=f"<div>{row['name']} {row['value']:,.0f}</div>") # row['value']:,.0f - 천 단위 구분기호 추가
).add_to(my_map) # my_map에 값 추가
# 지도 그리기
# st.components.v1.html : Streamlit 라이브러리의 components 모듈에서 html 함수 사용
# ._repr_html_() : 지도를 HTML 형식으로 표시
st.components.v1.html(my_map._repr_html_(), width=1000, height=800)
# 파일실행: File > New > Terminal(anaconda prompt) - streamlit run streamlit\7-3.folium_covid_ans.py
import streamlit as st
import folium
import pandas as pd
map_data = pd.DataFrame({
'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97],
'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5],
'name': ['Buenos Aires', 'Paris', 'Melbourne', 'St Petersburg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'],
'value': [10, 12, 40, 70, 23, 43, 100, 43]
})
# folium.Map(): Folium에서 지도 객체를 생성
# location: 지도가 초기에 어떤 위치에서 시작할지를 정의
# map_data['lat'].mean()과 map_data['lon'].mean(): 평균 위도와 경도 위치를 지도 중심으로 설정
# zoom_start: 이 매개변수는 지도의 초기 확대 수준 (default=10, 숫자가 클수록 확대)
my_map = folium.Map( location=[map_data['lat'].mean(), map_data['lon'].mean()], zoom_start=2 )
# 지도에 원형 마커와 값 추가
for index, row in map_data.iterrows(): # 데이터프레임 한 행 씩 index, row에 담아서 처리
folium.CircleMarker( # 원 표시 선언
location=[row['lat'], row['lon']], # 원 중심- 위도, 경도
radius=row['value'] / 5, # 원의 반지름
color='pink', # 원의 테두리 색상
fill=True, # 원을 채움
fill_opacity=1.0 # 원의 내부를 채울 때의 투명도
).add_to(my_map) # my_map에 원형 마커 추가
folium.Marker( # 값 표시 선언
location=[row['lat'], row['lon']], # 값 표시 위치- 위도, 경도
icon=folium.DivIcon(html=f"<div>{row['name']} {row['value']}</div>"), # row['name'], row['value'] 표시
).add_to(my_map) # my_map에 값 추가
# 타이틀과 캡션 표시하기
st.title('Map with Location Data')
st.caption("Displaying geographical data on a map using Streamlit and Folium")
# 지도 그리기
# st.components.v1.html : Streamlit 라이브러리의 components 모듈에서 html 함수 사용
# ._repr_html_() : 지도를 HTML 형식으로 표시
st.components.v1.html(my_map._repr_html_(), width=800, height=600)
# 파일실행: File > New > Terminal(anaconda prompt) - streamlit run streamlit\7-2.folium_map_ans.py
# 2. subheader 코드를 사용하여 지도 제목 'Aivle Map' 보여주기
st.subheader('Aivle Map')
# 3. checkbox를 이용하여 checkbox 선택여부에 따라
# write 코드를 사용하여 화면에 데이터프레임 값 나타내기
if st.checkbox('Display Data'):
st.write(map_data)
# 지도 그리기
st.map(map_data,
latitude='lat',
longitude='lon')
# 파일실행: File > New > Terminal(anaconda prompt) - streamlit run streamlit\7-1.st_map_ans.py
import streamlit as st
import altair as alt
import pandas as pd
import plotly.express as px
제목과 subheader를 입력하자
st.title('종합실습')
st.header('_2021 서울교통공사 지하철 월별 하차 인원_')
버튼을 통해 원본 주소를 보여준다.
if st.button('data copyright link'):
st.write('https://www.data.go.kr/data/15044247/fileData.do')
체크박스를 클릭하며 다양한 동작을 수행하자
# 원본 데이터 확인
if st.checkbox('원본 데이터 보기'):
subheader('1. 원본 데이터 - df')
st.dataframe(df)
# 구분 컬럼이 하차인 데이터 선택
# 먼저 구분 컬럼이 하차인 데이터를 선택한다.
df_off = df.loc[df['구분'] =='하차']
# checkbox를 선택하면 데이터프레임이 나오도록 한다.
if st.checkbox('하차 데이터 보기'):
subheader('2. 하차 데이터 - df_off')
st.write(df_off)
# 호선, 시간대별 인원수 보기
# 불필요한 컬럼을 삭제한다.
df_line = df_off.drop(['날짜','연번','역번호','역명','구분','합계'], axis=1)
if st.checkbox('호선, 시간대별 인원수 보기'):
st.subheader('3. 호선, 시간대별 인원수 - df_line')
st.write(df_line)
# Unpivot 데이터 보기
# melt 함수 사용 unpivot: identifier-'호선', unpivot column-'시간', value column-'인원수'
# 새로운 데이터프레임에 저장 & checkbox를 선택하면 데이터프레임이 나타남
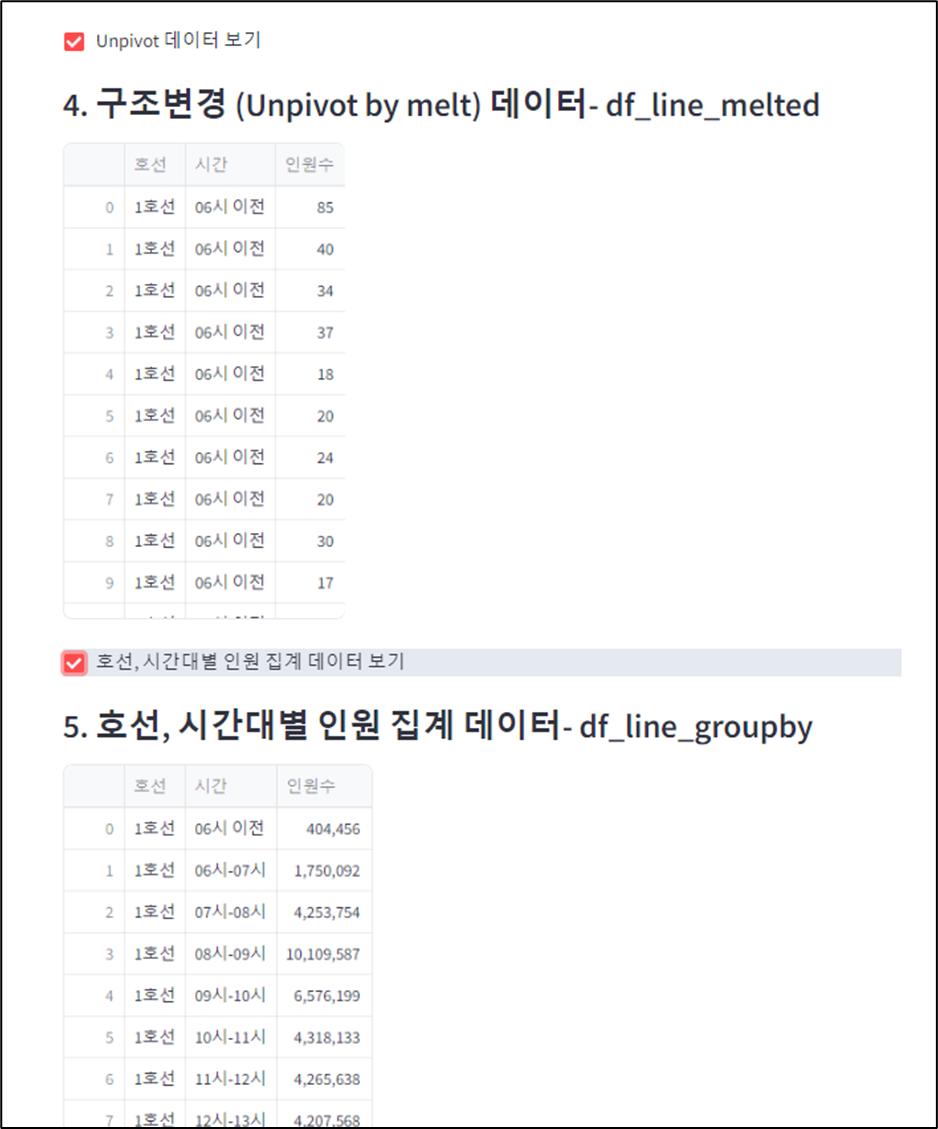
df_line_melted = pd.melt(df_line, id_vars = ['호선'], var_name = '시간', value_name = '인원수')
if checkbox('Unpivot 데이터 보기'):
st.subheader('4. 구조 변경 : (Unpivot by melt) 데이터 - df_line_melted')
st.write(df_line_melted)
호선, 시간별 인원수의 합을 확인하자
# '호선','시간' 별 '인원수' 합, as_index=False 저장 & 확인
# 새로운 데이터프레임에 저장 & checkbox를 선택하면 데이터프레임이 나타남
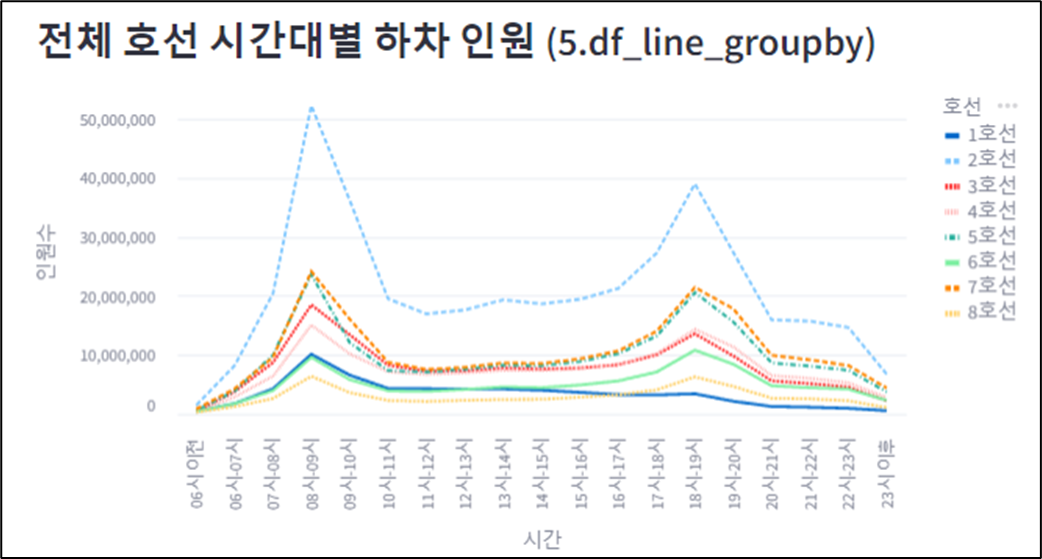
df_line_groupby = df_line_melted.groupby( [ '호선', '시간' ], as_index = False)[ '인원수' ].sum()
if st.checkbox('호선, 시간대별 인원 집계 데이터 보기'):
st.subheader(' 5. 호선, 시간대별 인원 집계 데이터 - df_line_groupby')
st.write(df_line_groupby)
# Unpivot과 호선','시간' 별 '인원수' 합을 수행하면 아래와 같다.
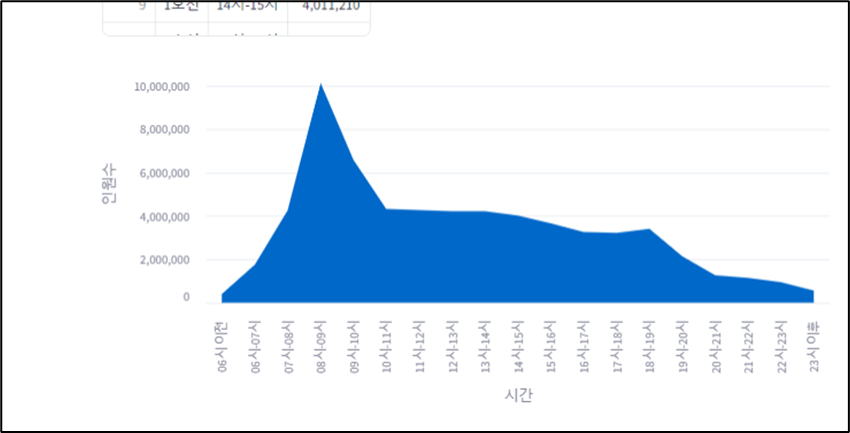
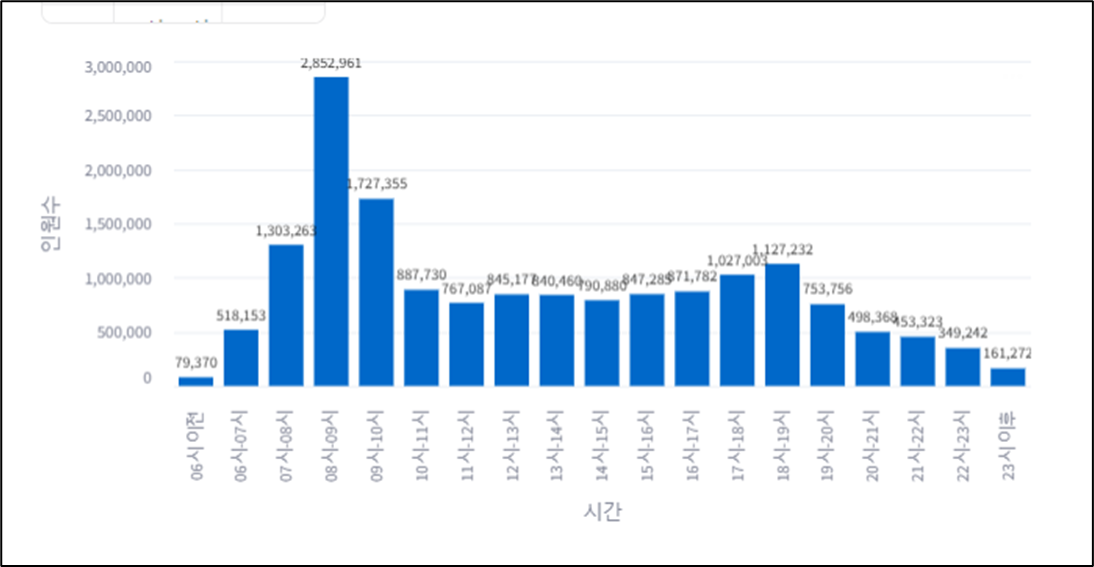
st.subheader('선택한 호선의 시간대별 하차 인원')
# 데이터프레임- df_line_groupby ('호선', '시간대별' 인원 집계 )
# ['호선'] 컬럼에 대해 .unique() 매소드를 사용하여
# selectbox에 호선이 각각 하나만 나타나게 함
option = st.selectbox('호선 선택 (5.df_line_groupby)', df_line_groupby['호선'].unique())
# .loc 함수를 사용하여 선택한 호선 데이터 선별하고
# 새로운 데이터 프레임-에 저장 & 확인
df_selected_line = df_line_groupby.loc[df_line_groupby['호선'] ==option]
st.write(option, ' 데이터 (df_selected_line)', df_selected_line)
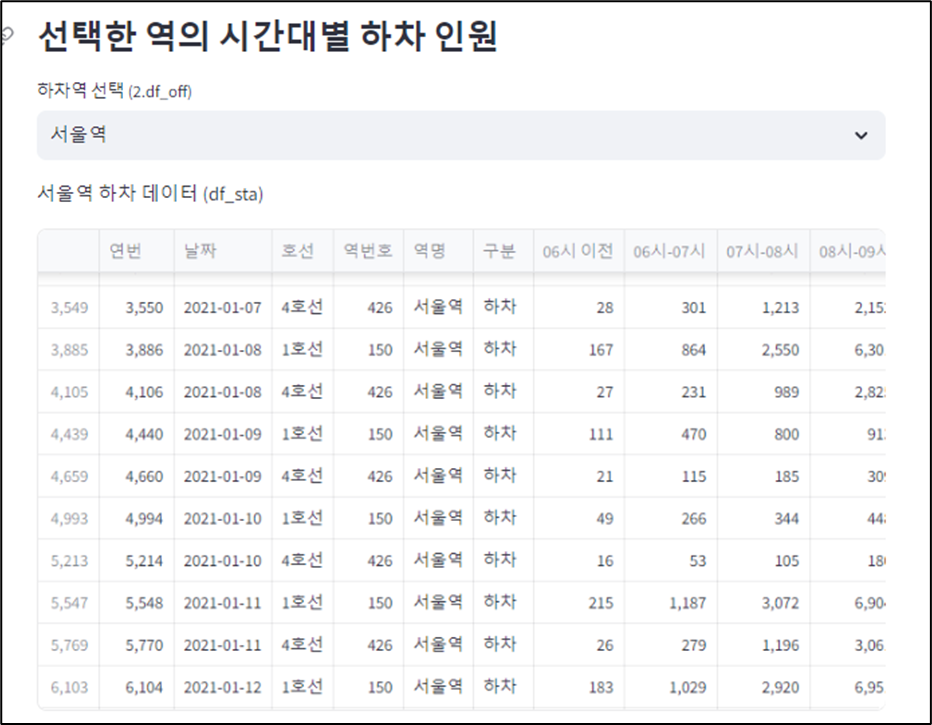
st.subheader('선택한 역의 시간대별 하차 인원')
# selectbox를 사용하여 '하차역' 선택
# ['역명'] 컬럼에 대해 .unique() 매소드를 사용하여
# selectbox에 역명이 각각 하나만 나타나게 함
option = st.selectbox('하차역 선택 (2.df_off)', df_off['역명'].unique())
# .loc 함수를 사용하여 선택한 역의 데이터를 선별하고
# 새로운 데이터 프레임에 저장
df_sta = df_off.loc[df_off['역명'] == option]
st.write(option, '하차 데이터 (df_sta)', df_sta)
# 불필요한 컬럼 '연번','호선','역번호','역명','구분','합계' 제외하고 기존 데이터 프레임에 저장
# 참고) df_sta = df_sta[df_sta.columns.difference(['연번', '호선', '역번호', '역명','구분','합계'])]
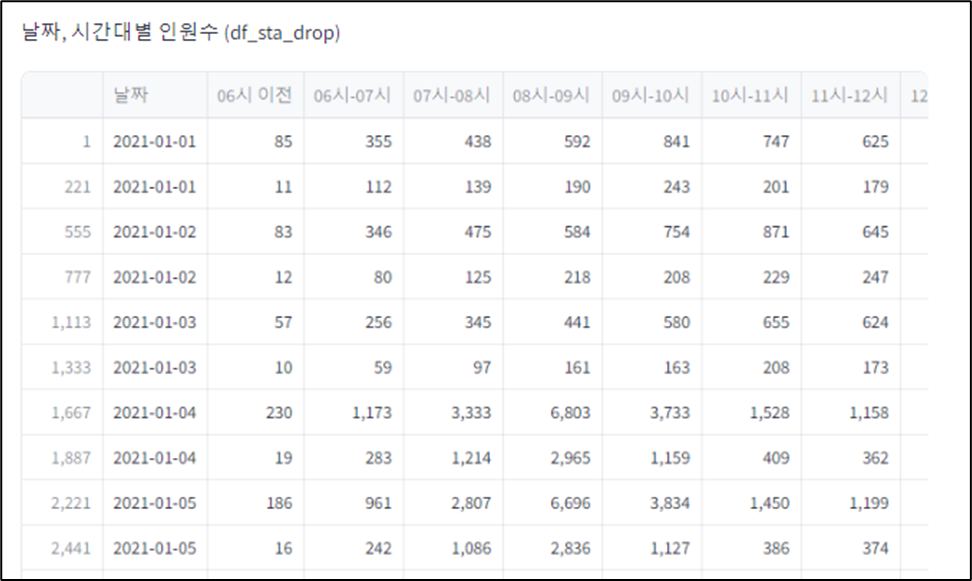
df_sta_drop = df_sta.drop(['연번', '호선', '역번호', '역명','구분','합계'], axis=1)
st.write('날짜, 시간대별 인원수 (df_sta_drop)', df_sta_drop)
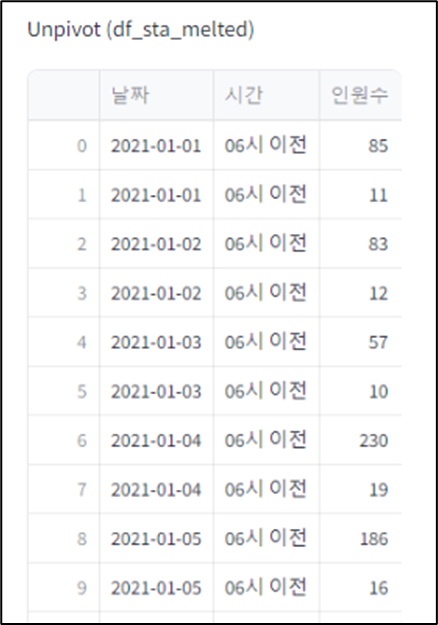
# melt 함수 사용 unpivot: identifier-'날짜', unpivot column-'시간', value column-'인원수'
# 새로운 데이터 프레임-에 저장 & 확인
df_sta_melted = pd.melt(df_sta_drop, id_vars=['날짜'], var_name='시간', value_name='인원수')
st.write('Unpivot (df_sta_melted)', df_sta_melted)
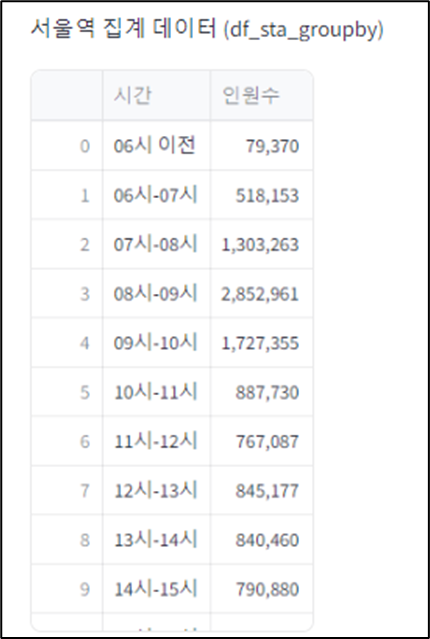
# '시간' 별 '인원수' 집계 , as_index=False
# 새로운 데이터 프레임-에 저장 & 확인
df_sta_groupby = df_sta_melted(['시간'], as_index = False)['인원수'].sum()
st.write(option, ' 집계 데이터 (dfa_sta_groupb)', df_sta_groupby)
altair mark_bar chart + text 그리기 mark_bar()
# 데이터프레임- df_sta_groupby, x-'시간', y-'인원수'
chart = alt.Chart(df_sta_groupby).mark_bar().encode(
x = '시간', y = '인원수').properties(width = 650, height = 350)
text = alt.Chart(df_sta_groupby).mark_text(dx = 0, dy = -10, color = 'black').encode(
x = '시간', y = '인원수', text = alt.Text('인원수:Q', format = ',.0f') )
# format=',.0f' : 천 단위 구분기호+소수점 이하 0
st.altair_chart(chart+text, use_container_width = True)