# 코랩 사용 시 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
경로 확인
# ROOT_PATH 확인
import os
ROOT_PATH = "/content/drive/MyDrive/helmet"
if not os.path.exists(ROOT_PATH):
os.makedirs(ROOT_PATH)
TUTORIAL_PATH = "/content/drive/MyDrive/helmet/tutorial"
if not os.path.exists(TUTORIAL_PATH):
os.makedirs(TUTORIAL_PATH)
if os.path.exists("/content/drive/MyDrive/helmet") : #경로가 있는지 확인
ROOT_PATH = "/content/drive/MyDrive/helmet"
print("helmet 폴더가 잘생성되어 있습니다.")
else :
print("/content/drive/MyDrive에 'helmet' 폴더를 생성해 주세요")
# TUTORIAL 데이터 경로
if os.path.exists( ROOT_PATH + "/tutorial") : #경로가 있는지 확인
TUTORIAL_PATH = ROOT_PATH + "/tutorial"
print("helmet/tutorial 폴더가 잘생성되어 있습니다.")
else :
print("'helmet' 폴더 밑에 'tutorial'를 생성해 주세요")
# pandas, numpy, matplotlib, seaborn, os 등 필요 라이브러리 호출
# 데이터를 나누기 위한 sklearn.model_selection 모듈의 train_test_split 함수 사용
# 모델 성능 평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 사용
# XGBClassifier 알고리즘 사용을 위한 모듈 호출
# 진척도 상황을 확인하기 위한 tqdm 라이브러리 호출
# 저장한 모델 사용을 위한 joblib 라이브러리 호출
## 그외 라이브러리는 필요에 따라 호출해서 사용하세요.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import joblib
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from xgboost import XGBClassifier
(2) 모델 호출
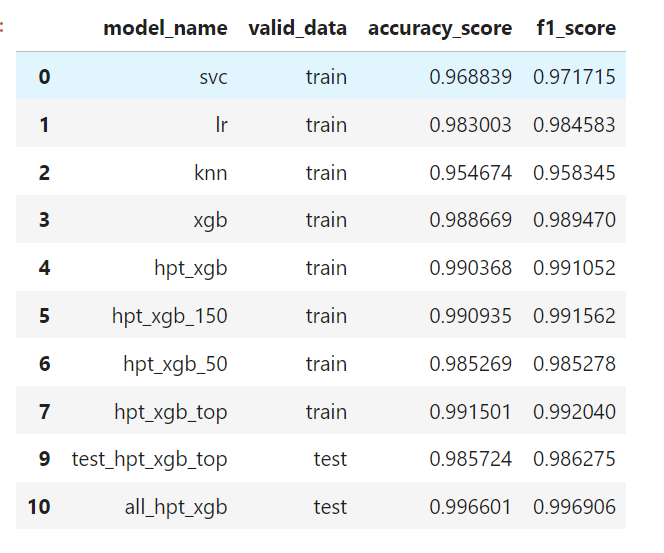
# 모델별 결과 불러오기
## 모델별 정확도를 비교 할 수 있도록 결과 저장 파일을 불러 옵니다.
## 'data' 폴더에서 /result5.csv 파일을 불러와 result 변수에 할당 합니다.
## result 변수에 할당이 잘 되었는지 확인해 주세요.
result = pd.read_csv('./data/result5.csv')
result
(3) 중요 feature 불러오기
# 중요 feature 불러오기
## 모델 정확도에 높은 영향을 미치는 feature 이름을 저장한 importance_top.pkl 파일을 불러와 importance_top에 저장 합니다.
## importance_top 변수에 할당이 잘 되었는지 확인해 주세요.
importance_top = joblib.load('importance_top.pkl')
importance_top
(4) test 데이터 불러오기
# test 데이터 불러오기
## 'data' 폴더에서 test_data.csv 파일을 불러와서 test_data 변수에 할당해 주세요.
## 잘 할당 되었는지 데이터를 확인해 주세요.
test_data = pd.read_csv('./data/test_data.csv')
test_data
(5) train 데이터 불러오기
# train 데이터 불러오기
## 'data' 폴더에서 train_data.csv 파일을 불러와서 train_data 변수에 할당해 주세요.
## 잘 할당 되었는지 데이터를 확인해 주세요.
train_data = pd.read_csv('./data/train_data.csv')
train_data
2] 데이터 합치기, 인덱스 초기화
# 데이터 합치기
## all_data 변수에 train 데이터셋과 test 데이터셋을 위/아래로 합쳐서 할당 합니다.
all_data = pd.concat([train_data, test_data])
all_data
# 데이터 인덱스 초기화
## 데이터셋을 위아래로 합치면 인덱스 중복이 발생 합니다.
## 인덱스가 중복되지 않도록 인덱스를 리셋해 주세요.
all_data.reset_index(drop=True, inplace=True)
all_data
'WALKING_UPSTAIRS' 행동분류에 영향을 미치는 중요 feature 도출
1] X, Y 데이터 나누기
# X, Y 데이터 나누기
## 모델 학습을 위해 feature(X) 데이터와 target(Y) 데이터를 나누어 주어야 합니다.
## target(Y)을 분리를 위해 all_data['Activity'] 값을 숫자로 변환 할 때 'WALKING_UPSTAIRS' 만 인식 할 수 있도록 숫자를 구성해야 합니다.
## [TIP]: {'STANDING':0, 'SITTING':0, 'LAYING':0, 'WALKING':0, 'WALKING_UPSTAIRS':1, 'WALKING_DOWNSTAIRS':0}
## 변환된 결과를 all_y_map 변수에 할당 합니다.
## all_data 데이터에서 2일차에서 선정한 중요도가 높은 feature 들만 골라 all_x 변수에 할당 합니다.
## 중요도가 높은 feature 들의 이름은 .pkl 파일에서 불러와 importance_top 변수에 저장되어 있습니다.
all_y_map = all_data['Activity'].map({'STANDING':0, 'SITTING':0, 'LAYING':0, 'WALKING':0, 'WALKING_UPSTAIRS':1, 'WALKING_DOWNSTAIRS':0})
all_x = all_data[importance_top]
2] 학습 데이터 나누기
# 학습 데이터 나누기
## 학습에 필요한 all_x 와 all_y_map 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: all_x_train, all_x_val, all_y_train, all_y_val
all_x_train, all_x_val, all_y_train, all_y_val = train_test_split(all_x,all_y_map,train_size=0.7,random_state=2023)
3] AI 모델링 및 결과 예측
# AI 모델링 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 walkingup_model 변수에 모델을 생성 및 초기화 합니다.
## 파라미터는 최종 조정 파라미터를 사용하고, random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 all_x_val 데이터의 결과를 예측하여 walkingup_pred 변수에 할당 합니다.
walkingup_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
walkingup_model.fit(all_x_train, all_y_train)
walkingup_pred = walkingup_model.predict(all_x_val)
walkingup_pred
4] 성능 평가
# walkingup_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(all_y_val,walkingup_pred))
print('\n confusion_matrix: \n',confusion_matrix(all_y_val,walkingup_pred))
print('\n classification_report: \n',classification_report(all_y_val,walkingup_pred))
5] 예측결과 저장
# walkingup_xgb_model 예측결과 저장
## result 데이터프레임 12번 인덱스에 'walkingup_xgb'(모델명), 'all'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[12] = ['walkingup_xgb', 'all', accuracy_score(all_y_val,walkingup_pred), f1_score(all_y_val,walkingup_pred, average = 'macro')]
result
모델 정확도 개선
1] 데이터프레임 생성
# feature 명 데이터 파일 생성
## up_importance_sort 데이터프레임 변수를 생성 및 초기화 합니다.
up_importance_sort = pd.DataFrame()
2] feature 명 할당
# feature 명 할당
## up_importance_sort['feature_name'] 열에 walkingup_model 학습에 사용한 all_x 데이터프레임의 모든 feature 명을 할당 합니다.
up_importance_sort['feature_name'] = all_x.columns
up_importance_sort
3] feature 중요도 할당
# feature importances 할당
## up_importance_sort['feature_importance'] 열에 walkingup_model 모델의 feature_importances 를 할당해 줍니다.
## 참고함수: feature_importances_
up_importance_sort['feature_importance'] = walkingup_model.feature_importances_
up_importance_sort
4] 중요도 순으로 인덱스 재정렬
# 중요도 순으로 인덱스 재 정렬
## up_importance_sort 데이터프레임을 up_importance_sort['feature_importance'] 순으로 내림차순 정열 합니다.
## 정렬 후 결과를 확인 합니다.
up_importance_sort.sort_values(by='feature_importance', ascending=False, inplace=True)
up_importance_sort
5] 인덱스 초기화
# 데이터 인덱스 초기화
## 인덱스가 순서대로 나열 되도록 인덱스를 리셋해 주세요.
up_importance_sort.reset_index(drop=True, inplace=True)
up_importance_sort
최적의 Feature Selection 찾기
1] 데이터프레임 생성 및 최적의 Feature Selection 찾기
# 최적의 Feature Selection 찾기
## acc 데이터 프레임을 생성 및 초기화 합니다.(컬럼 지정: columns=['accuracy_score'])
## 전체 feature는 561개에서 도출한 Top feature 개수를(예: 141개) 선별 했기에 feature를 1개 ~ Top feature 개수까지 모델링과 결과를 도출 합니다.
## for 문을 사용해 중요도 상위 feature 1개 모델링부터 Top feature 개수까지 순차적 모델링 실행 후 각 accuracy_score 결과를 acc 변수에 누적 합니다.
## [TIP] tqdm: tqdm은 반복문에서 현재 계산되고 있는 부분의 퍼센테이지를 시각적으로 나태내어 줍니다.
## [TIP] tqdm 사용 예제: for i in range(10) -> for i in tqdm(range(10)):
acc = pd.DataFrame(columns=['accuracy_score'])
for i in tqdm(range(len(up_importance_sort))):
importance_n = up_importance_sort['feature_name'][:i+1]
x_train_n = all_x_train[importance_n]
x_val_n = all_x_val[importance_n]
xgb_n_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
xgb_n_model.fit(x_train_n, all_y_train)
xgb_n_pred = xgb_n_model.predict(x_val_n)
acc.loc[i] = accuracy_score(all_y_val,xgb_n_pred)
acc
# 최고 정확도 Feature 개수 찾기
## acc 변수를 accuracy_score 기준 내림차순으로 정렬 합니다.(인덱스 재설정X)
## 인덱스 번호는 누적 학습된 feature의 개수 입니다.
## accuracy_score 값으로 내림차순 정렬 후 이 가장 첫번째 행의 인덱스 번호가 가장 정확도가 좋은 feature 개수를 뜻합니다.
acc.sort_values(by = 'accuracy_score', ascending=False, inplace=True)
acc
4] 최고 정확도 Feature 열 저장
# 최고 정확도 Feature명 저장
## acc 결과에서 확인한 가장 성능좋은 결과를 내는 feature의 개수 만큼 importance_sort['feature_name']를 슬라이싱 하여
## feature의 이름을 up_importance_top 변수에 할당 합니다.
## 정확도 최고치 인덱스 값 +1 해서 슬라이싱 하세요.
## [TIP] 슬라이싱 할때 [:1] -> feature 0번 까지 짤림, [:100] -> feature 99번 까지 짤림
up_importance_top = up_importance_sort['feature_name'][:acc.index[0]+1]
up_importance_top
5] 훈련 데이터 생성
# 훈련 데이터 생성
## all_x_train 데이터에서 위에서 up_importance_top에 할당한 feature 들의 데이터를 x_train_top 변수에 할당해 줍니다.
## all_x_val 데이터에서 위에서 up_importance_top에 할당한 feature 들의 데이터를 x_val_top 변수에 할당해 줍니다.
all_x_train_top = all_x_train[up_importance_top]
all_x_val_top = all_x_val[up_importance_top]
6] 모델 선언, 학습, 예측
# AI 모델링 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 walkingup_top_model 변수에 모델을 생성 및 초기화 합니다.
## 파라미터는 최종 조정 파라미터를 사용하고, random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train_top, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 all_x_val_top 데이터의 결과를 예측하여 walkingup_pred 변수에 할당 합니다.
walkingup_top_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
walkingup_top_model.fit(all_x_train_top, all_y_train)
walkingup_top_pred = walkingup_top_model.predict(all_x_val_top)
walkingup_top_pred
7] 모델 평가
# 모델 평가 출력(accuracy_score, confusion_matrix, classification_report)
print('accuracy_score: ',accuracy_score(all_y_val,walkingup_top_pred))
print('\n confusion_matrix: \n',confusion_matrix(all_y_val,walkingup_top_pred))
print('\n classification_report: \n',classification_report(all_y_val,walkingup_top_pred))
8] 예측 결과 저장
# walkingup_top_model 예측결과 저장
## result 데이터프레임 13번 인덱스에 'walkingup_top'(모델명), 'all'(검증 데이터명), accuracy_score 결과, f1_score 결과 를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[13] = ['walkingup_top', 'all', accuracy_score(all_y_val,walkingup_top_pred), f1_score(all_y_val,walkingup_top_pred, average = 'macro')]
result
'WORKING_UPSTAIRS' 분류에 영향을 미치는 'sensor' 찾기
'WORKING_UPSTAIRS' 분류에 가장 영향 많이 미치는 상위 20개의 sensor 그룹을 찾아 시각화
1] 파일 불러오기
# features.csv 파일 불러오기
## 'data'폴더에서 features.csv 파일을 읽어와 feature_group 변수에 할당 하세요.
## 변수에 할당이 잘 되었는지 확인해 주세요.
feature_group =pd.read_csv('./data/features.csv')
2] 데이터프레임 merge
# 데이터프레임 merge
## merge_df 변수를 데이터프레임 타입으로 생성 및 초기화 합니다.
## feature_group 변수와 up_importance_sort 변수를 merge 하여 merge_df 할당 합니다.
## 데이터가 잘 할당 되었나 merge_df 데이터를 확인 합니다.
merge_df = pd.DataFrame()
merge_df = pd.merge(feature_group, up_importance_sort)
merge_df
3] 데이터그룹화
# 데이터 그룹화
## merge_df 변수를 'sensor' 기준으로 그룹화 하고 'feature_importance' 열의 데이터를 같은 'sensor' 그룹끼리 더해 줍니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 계산을 동시에 수행할 수 있습니다.
## [TIP] 변수.groupby(by='그룹기준열')['연산 할 열'].연산메서드()
sensor_sum = merge_df.groupby(by='sensor')['feature_importance'].sum()
sensor_sum
4] 중요도 재정렬
# sensor 중요도 재 정렬
## sensor_sum 데이터를 내림차순으로 정렬 후 sensor_sort 변수에 할당합니다.
## sensor_sum 을 데이터프레임 으로 생성했을 경우 기준(by=)을 지정해 주어야 합니다.
sensor_sort = sensor_sum.sort_values(ascending=False)
sensor_sort
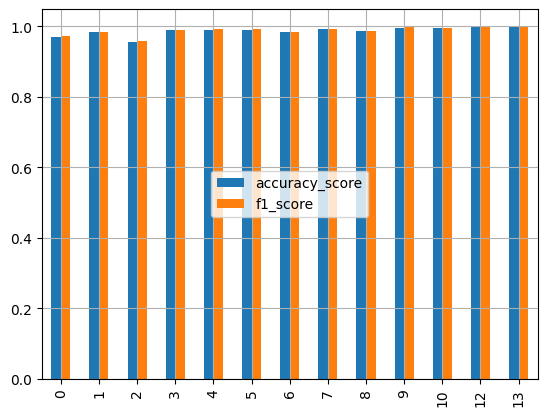
# 최종결과 결과 시각화
# 모델 별 accuracy_score, f1_score 지수를 수직 그래프로 시각화 하세요.
result.plot(kind='bar')
plt.grid()
plt.legend(loc='center')
plt.show()
(2) 저장
# 최종결과 저장
## 최종 결과(result)를 'final_result.csv' 파일로 저장해 주세요.
## 영향도가 높은 feature 들의 이름을 모아놓은 변수를 'up_importance_top.csv' 파일로 저장해 주세요.
result.to_csv("final_result.csv")
up_importance_top.to_csv("up_importance_top.csv")
'WORKING_UPSTAIRS' 분류에 영향을 미치는 상위 20 agg 찾기
1] 데이터 그룹화
# 데이터 그룹화
## merge_df 변수를 ['sensor','agg'] 기준으로 그룹화 하면서 'feature_importance' 열의 데이터를 더해 줍니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 계산을 동시에 수행할 수 있습니다.
sensor_agg_sum = merge_df.groupby(['sensor','agg'])['feature_importance'].sum()
sensor_agg_sum
2] sensor_agg 중요도별 데이터 재정렬
# sensor_agg 중요도 별 데이터 재정렬
## sensor_agg_sum 데이터를 내림차순으로 정렬 후 sensor_agg_sort 변수에 할당합니다.
sensor_agg_sort = sensor_agg_sum.sort_values(ascending=False)
sensor_agg_sort
# sensor_agg_sort 변수를 데이터프레임으로 생성시
# sensor_agg_sort = sensor_agg_sum.sort_values(by='feature_importance', ascending=False)
# sensor_agg_sort
# sensor_agg_sort 데이터 재 구조화
# sensor_agg_sort 데이터의 'agg'열의 고유값을 sensor_agg_sort 데이터의 컬럼으로 변환(재구조화) 합니다.
# 재구조화 한 데이터를 acc 변수에 할당 합니다.
# 참고함수: unstack()
acc = sensor_agg_sort.unstack()
acc
2] 재정렬
# 센서별 합계 재정렬
## acc 데이터의 각 센서의 행 기준(axis=1) 모든 값을 더해서 acc['sort'] 에 할당 합니다.
## 할당 후 acc 데이터를 acc['sort'] 열의 값 기준으로 내림차순으로 정렬 합니다.
## 정렬 후 데이터를 확인 합니다.
acc['sort'] = acc.sum(axis=1)
acc.sort_values(by = 'sort', ascending = False, inplace=True)
acc
## real_data.csv 파일을 불러와서 real_data 변수에 할당 합니다.
## 잘 할당 되었는지 데이터 확인
real_data = pd.read_csv('./data/real_data.csv')
real_data
2] 불필요 컬럼 제거
## real_data 변수(데이터셋)에서 행동분류에 불필요한 'subject'열 제거한 데이터를 real_x_val 변수에 할당 합니다.
## 나중에 예측 결과를 real_data 데이터 프레임에 병합해서 결과를 확인해야 하므로 real_data 변수에서 'subject'열 제거하지 마세요.
real_x_val = real_data.drop('subject', axis=1)
real_x_val
3] real_x_val 데이터에서 최고의 성능을 내는 학습 feature 데이터를 real_x_top 변수에 할당
## real_x_val 데이터에서 최고의 성능을 내는 학습 feature 데이터를 real_x_top 변수에 할당합니다.
## Feature Selection 된 상위 중요 feature 명 리스트는 up_importance_top 변수를 사용 합니다.
real_x_top = real_x_val[up_importance_top]
4] walkingup_top 모델로 real_x_top 데이터의 'WALKING_UPSTAIRS' 행동분류 예측해서 real_walkingup_pred 변수에 할당
## walkingup_top 모델로 real_x_top 데이터의 'WALKING_UPSTAIRS' 행동분류 예측해서 real_walkingup_pred 변수에 할당 합니다.
real_walkingup_pred = walkingup_top_model.predict(real_x_top)
real_walkingup_pred
5] real_data['WALKING_UPSTAIRS'] 열에 real_walkingup_pred 예측 결과를 할당 하고, 데이터를 확인
## real_data['WALKING_UPSTAIRS'] 열에 real_walkingup_pred 예측 결과를 할당 하고, 데이터를 확인 합니다.
real_data['WALKING_UPSTAIRS'] = real_walkingup_pred
real_data
# pandas, numpy, matplotlib, seaborn, os 등 필요 라이브러리 호출
# 데이터를 나누기 위한 sklearn.model_selection 모듈의 train_test_split 함수 사용
# 모델 성능 평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 사용
# XGBClassifier 알고리즘 사용을 위한 모듈 추가
# 저장한 모델을 불러오기 위한 joblib 라이브러리 추가
## 그외 라이브러리는 필요에 따라 호출 하세요.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import joblib
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
from xgboost import XGBClassifier
모델 데이터 불러오기
# 2일차 데이터 불러오기
## 2일차에 만들었던 최고 성능의 모델(hpt_xgb_top_model.pkl)을 불러와 hpt_xgb_top_model 변수에 할당 합니다.
## 모델 결과에 가장 영향을 많이 미친 feature의 이름이 담긴 importance_top 데이터(importance_top.pkl)를 불러와 importance_top 변수에 할당 합니다.
hpt_xgb_top_model = joblib.load('hpt_xgb_top_model.pkl')
importance_top = joblib.load('importance_top.pkl')
결과 데이터 프레임 불러오기
# 2일차 모델 결과 데이터 불러오기
## 모델별 정확도를 비교 할 수 있도록 결과 저장 파일을 불러 옵니다.
## 'data' 폴더에서 2일차에 생성한 result4.csv 파일을 불러와서 result 변수에 할당 합니다.
## result 변수에 할당이 잘 되었는지 확인해 주세요.
result = pd.read_csv('./data/result4.csv')
result
test 데이터 불러오기
# test 데이터 불러오기
## 'data' 폴더에서 test_data.csv 파일을 불러와서 test_data 변수에 할당해 주세요.
## 잘 할당 되었는지 데이터를 확인해 주세요.
test_data = pd.read_csv('./data/test_data.csv')
test_data
데이터 나누기
# test X, Y 나누기
## 모델을 검증 하기위해 test 데이터를 사용하여 test_x , test_y_map(target) 데이터를 생성 합니다.
## test_x 에는 test_data 데이터셋에서 2일차에 최고의 성능을 내는 feature 들만(importance_top) 분리하여 할당 합니다.
## test_y 에는 모델의 예측 결과와 비교할 수 있도록 test_data['Activity'] 열의 값을 숫자형으로 치환하여 할당 합니다.
## 치환 데이터: 'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5
test_x = test_data[importance_top]
test_y_map = test_data['Activity'].map({'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5})
검증
# test 데이터 결과 예측
# 2일차에 생성한 hpt_xgb_top_model 에 text_x 데이터를 적용한 예측 결과를 test_hpt_xgb_top_pred 변수에 할당 합니다.
# 사용할 모델은 .pkl 파일에서 로드한 hpt_xgb_top_model 변수를 사용 합니다.
test_hpt_xgb_top_pred = hpt_xgb_top_model.predict(test_x)
test_hpt_xgb_top_pred
# test 데이터 적용 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(test_y_map,test_hpt_xgb_top_pred))
print('\n confusion_matrix: \n',confusion_matrix(test_y_map,test_hpt_xgb_top_pred))
print('\n classification_report: \n',classification_report(test_y_map,test_hpt_xgb_top_pred))
예측 결과 저장
# hpt_xgb_top_model 예측결과 저장
## result 데이터프레임 9번 인덱스에 'test_hpt_xgb_top'(모델명), 'test'(검증 데이터명), accuracy_score 결과, f1_score 결과 를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[9] = ['test_hpt_xgb_top', 'test', accuracy_score(test_y_map,test_hpt_xgb_top_pred), f1_score(test_y_map,test_hpt_xgb_top_pred, average = 'macro')]
result
과대적합 해소
1) 학습량 늘리기
(1) 불러오기
# train 데이터 불러오기
## 'data' 폴더에서 'train_data.csv' 파일을 불러와서 train_data 변수에 할당 합니다.
## 잘 불러와 졌는지 데이터를 확인 합니다.
train_data = pd.read_csv('./data/train_data.csv')
train_data
(2) 합치기
# 데이터 합치기
## train 데이터셋과 test 데이셋을 합쳐 데이터의 양을 늘려 줍니다.
## train 데이터셋과 test 데이터셋을 위/아래로 합쳐서 all_data 변수에 할당 합니다.
## 참고함수: concat
all_data = pd.concat([train_data, test_data])
all_data
(3) 인덱스 초기화
# 데이터 인덱스 초기화
## 데이터셋을 위아래로 합치면 인덱스 중복이 발생 합니다.
## 인덱스가 중복되지 않도록 인덱스를 리셋해 주세요.
all_data.reset_index(drop=True, inplace=True)
all_data
(4) X, Y데이터 나누기
# X, Y 데이터 나누기
## 모델 학습을 위해 feature(X) 데이터와 target(Y) 데이터를 나누어 주어야 합니다.
## target 데이터인 all_data['Activity'] 값을 모델이 인식할 수 있게 숫자로 변환하여 all_y_map 변수에 할당 합니다.
## all_data 데이터에서 2일차에서 선정한 중요도가 높은 feature 들만 골라 all_x 변수에 할당 합니다.
## 중요도가 높은 feature 들의 이름은 .pkl 파일에서 불러와 importance_top 변수에 저장되어 있습니다.
all_y_map = all_data['Activity'].map({'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5})
all_x = all_data[importance_top]
all_x
(5) 학습 데이터 나누기
# 학습 데이터 나누기
## 학습에 필요한 all_x 와 all_y_map 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: all_x_train, all_x_val, all_y_train, all_y_val
all_x_train, all_x_val, all_y_train, all_y_val = train_test_split(all_x,all_y_map,train_size=0.7,random_state=2023)
(6) 모델링 및 예측
# AI 모델링 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 all_hpt_xgb_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 파라미터는 튜닝에서 가장 성능이 좋았던 값으로 지정하고, random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 test_x 데이터의 결과를 예측합니다.
all_hpt_xgb_model = XGBClassifier(learning_rate=0.3, max_depth=3, random_state=2023)
all_hpt_xgb_model.fit(all_x_train, all_y_train)
all_hpt_xgb_pred = all_hpt_xgb_model.predict(test_x)
all_hpt_xgb_pred
(7) 평가
# all_hpt_xgb_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(test_y_map,all_hpt_xgb_pred))
print('\n confusion_matrix: \n',confusion_matrix(test_y_map,all_hpt_xgb_pred))
print('\n classification_report: \n',classification_report(test_y_map,all_hpt_xgb_pred))
(8) 예측 결과 저장
# all_hpt_xgb_model 예측결과 저장
## result 데이터프레임 10번 인덱스에 'all_hpt_xgb'(모델명), 'test'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[10] = ['all_hpt_xgb', 'test', accuracy_score(test_y_map,all_hpt_xgb_pred), f1_score(test_y_map,all_hpt_xgb_pred, average = 'macro')]
result
2) 모델 단순화
(1) 결과 예측
# 모델 단순화 및 결과 예측
## XGBClassifier 알고리즘을 사용하여 all_hpt_depth_xgb_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 과대적합이 일어나지 않도록 XGBClassifier의 깊이 파라미터를 조정해 모델을 단순화 하세요.
## random_state는 2023 으로 설정해 주세요.
## 모델이 생성되면 all_x_train, all_y_train 로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 test_x 데이터의 결과를 예측합니다.
all_hpt_depth_xgb_model = XGBClassifier(learning_rate=0.3, max_depth=2, random_state=2023)
all_hpt_depth_xgb_model.fit(all_x_train, all_y_train)
all_hpt_depth_xgb_pred = all_hpt_depth_xgb_model.predict(test_x)
all_hpt_depth_xgb_pred
(2) 성능 평가
# all_hpt_depth_xgb_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(test_y_map,all_hpt_depth_xgb_pred))
print('\n confusion_matrix: \n',confusion_matrix(test_y_map,all_hpt_depth_xgb_pred))
print('\n classification_report: \n',classification_report(test_y_map,all_hpt_depth_xgb_pred))
(3) 예측 결과 저장
# all_hpt_depth_xgb_model 예측결과 저장
## result 데이터프레임 11번 인덱스에 'all_hpt_depth_xgb'(모델명), 'test'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[11] = ['all_hpt_depth_xgb', 'test', accuracy_score(test_y_map,all_hpt_depth_xgb_pred), f1_score(test_y_map,all_hpt_depth_xgb_pred, average = 'macro')]
result
결과 저장
## 모델 저장하기(코드 수정하지 말고 실행해 주세요)
## 과대적합을 해결한 all_hpt_xgb_model 모델을 joblib.dump 매서드를 사용하여 all_hpt_xgb_model.pkl 파일로 저장 합니다.
joblib.dump(all_hpt_xgb_model, 'all_hpt_xgb_model.pkl')
# 결과 저장
# result 변수를 인덱스 미포함하여 'result5.csv' 파일로 저장 합니다.
# 저장경로는 현재 경로의 하위 './data' 폴더로 지정해 주세요.
result.to_csv('./data/result5.csv', index=False)
저장 여부 확인
# 저장 여부 확인
## 데이터가 파일로 잘 저장 되었는지 result5.csv 파일을 로드하여 확인 합니다.
## 로드한 데이터는 save_check 변수에 할당해 주세요.
save_check = pd.read_csv('./data/result5.csv')
save_check
Aivle 미니 프로젝트 3차_4(3)] 최고 정확도를 위한 학습 feature 개수 선별
반복문을 통한 중요도 계산, tqdm
# 반복문을 사용한 feature 개수 별 정확도 계산
## acc 데이터 프레임을 생성 및 초기화(컬럼 지정: columns=['accuracy_score'])
## for 문을 사용해 중요도 상위 feature 1개 모델링부터 상위 feature 150개를 모델에 순차적으로 학습시킨 후 각 accuracy_score 결과를 acc 변수에 누적 합니다.
## 전체 feature는 561개 이지만, feature 1개부터 150개면 까지 학습하면 충분한 결과를 얻을 수 있습니다.
## [TIP] 1번째 학습: feature 1개로 모델 학습 -> 결과 누적, 2번째 학습: feature 2개로 모델 학습 -> 결과 누적 ..... 150번째 학습: feature 150개로 모델 학습 -> 결과 누적
## [TIP] 슬라이싱 할때 [:1] -> index 0 까지 짤림, [:100] -> index 99 까지 짤림, 슬라이싱 할 인덱스 번호 +1 해서 슬라이싱 할 것
## [TIP] tqdm을 반복문에 사용하였을때 반복문의 현 실행 위치를 퍼센테이지로 나타내 줍니다.
acc = pd.DataFrame(columns=['accuracy_score'])
for i in tqdm(range(150)):
importance_n = importance_sort['feature_name'][:i+1]
x_train_n = x_train[importance_n]
x_val_n = x_val[importance_n]
xgb_n_model = XGBClassifier(params, random_state=2023)
xgb_n_model.fit(x_train_n, y_train)
xgb_n_pred = xgb_n_model.predict(x_val_n)
acc.loc[i] = accuracy_score(y_val,xgb_n_pred)
acc
누적 결과 시각화
# accuracy_score 누적 결과 시각화
## accuracy_score 누적한 acc 변수를 plt.plot 함수를 사용하여 시각화 합니다.
plt.figure(figsize=(20,5))
plt.plot(acc, marker='o')
plt.xlabel('train_features')
plt.ylabel('accuracy')
plt.grid()
plt.show()
최고 정확도 개수 찾기
# 최고 정확도 Feature 개수 찾기
## agg 변수를 accuracy_score 기준 내림차순으로 정렬 합니다.(인덱스 재설정X)
## 인덱스 번호는 누적 학습된 feature의 개수 입니다.
## accuracy_score 값으로 내림차순 정렬 후 이 가장 첫번째 인덱스 번호가 가장 정확도가 좋은 feature 개수를 뜻합니다.
acc.sort_values(by = 'accuracy_score', ascending=False, inplace=True)
acc
최고 정확도 feature열 지정
# 최고 정확도 Feature명 저장
## acc 에서 확인한 최고 결과 feature 개수 만큼 importance_sort['feature_name']를 슬라이싱 하여 importance_top 변수에 할당 합니다.
## 정확도 최고치 인덱스 값 +1 해서 슬라이싱 하세요.
## [TIP] 슬라이싱 할때 [:1] -> feature 0번 까지 짤림, [:100] -> feature 99번 까지 짤림
importance_top = importance_sort['feature_name'][:acc.index[0]+1]
importance_top
중요 feature 지정
# 중요 feature 저장
# importance_top 변수를 인덱스 미포함하여 'importance_top.csv' 파일로 저장 합니다.
# 저장경로는 현재 경로의 하위 './data' 폴더로 지정해 주세요.
importance_top.to_csv('./data/importance_top.csv', index=False)
훈련 데이터 생성
# 훈련 데이터 생성
# x_train_top 변수에 x_train을 중요 feature 만큼 슬라이싱 한 x_train[importance_top] 할당
# x_val_top 변수에 x_val을 중요 feature 만큼 슬라이싱 한 x_val[importance_top] 할당
x_train_top = x_train[importance_top]
x_val_top = x_val[importance_top]
모델링
# 베스트 feature 개수 적용 모델링
## XGBClassifier 모듈에 베스트 파라미터를 적용하여 모델을 생성 및 초기화 합니다.
## 파라미터는 params 변수에 사용된 파라미터와, random_state=2023 으로 설정해 주세요.
## 이때 생성한 모델을 hpt_xgb_top_model 변수에 할당 합니다.
## 모델이 생성되면 최적의 feature 개수만 선별한 x_train_top 데이터와 y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val_top의 결과를 예측하고 결과를 hpt_xgb_top_pred 변수에 할당 합니다.
hpt_xgb_top_model = XGBClassifier(learning_rate=0.3, max_depth=3, random_state=2023)
hpt_xgb_top_model.fit(x_train_top, y_train)
hpt_xgb_top_pred = hpt_xgb_top_model.predict(x_val_top)
hpt_xgb_top_pred
평가
# hpt_xgb_top_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,hpt_xgb_top_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,hpt_xgb_top_pred))
print('\n classification_report: \n',classification_report(y_val,hpt_xgb_top_pred))
예측 결과 지정
# hpt_xgb_top_model 예측결과 저장
## result 데이터프레임 8번 인덱스에 'hpt_xgb_top'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[8] = ['hpt_xgb_top', 'train', accuracy_score(y_val, hpt_xgb_top_pred), f1_score(y_val, hpt_xgb_top_pred, average = 'macro')]
result
결과 저장 및 시각화
# 결과 저장
# result 변수를 인덱스 미포함하여 'result4.csv' 파일로 저장 합니다.
# 저장경로는 현재 경로의 하위 './data' 폴더로 지정해 주세요.
result.to_csv('./data/result4.csv', index=False)
# 저장 여부 확인
## 데이터가 파일로 잘 저장 되었는지 result4.csv 파일을 로드하여 확인 합니다.
## 로드한 데이터는 save_check 변수에 할당해 주세요.
save_check = pd.read_csv('./data/result4.csv')
save_check
컬럼 인덱스 변환
# 컬럼-인덱스 변환
## save_check 데이터 프레임의 ['model_name', 'valid_data'] 컬럼을 지정하여 인덱스로 설정해 줍니다.
## 변환한 값은 result_comp 변수에 할당해 주세요.
result_comp = save_check.set_index(['model_name','valid_data'])
result_comp
시각화
# 모델별 결과 시각화
# pandas의 plot 함수을 사용하여 AI모델 별 accuracy_score, f1_score 수직 그래프 시각화 합니다.
# grid를 추가해 주세요.
# legend를 표시하고, 위치는 center 입니다.
result_comp.plot(kind='bar')
plt.grid()
plt.legend(loc='center')
plt.show()
모델 저장
## 모델 저장하기
## 오늘 만들었던 최고 성능의 모델과 학습 데이터를 저장 합니다.
## 아래의 코드에서 한글로 씌여진 곳에 본인이 생성한 변수명을 기입해 주세요.
import joblib
# joblib.dump(최고의 모델, 'hpt_xgb_top_model.pkl')
# joblib.dump(중요 feature명 모음, 'importance_top.pkl')
# joblib.dump(최종 학습 X 데이터, 'x_train_top.pkl')
# joblib.dump(최종 학습 Y 데이터, 'y_train.pkl')
# 작성 예시
joblib.dump(hpt_xgb_top_model, 'hpt_xgb_top_model.pkl')
joblib.dump(importance_top, 'importance_top.pkl')
joblib.dump(x_train_top, 'x_train_top.pkl')
joblib.dump(y_train, 'y_train.pkl')
# feature(feature) 중요도 할당
## hpt_xgb_model 모델의 feature_importances 를 importance_sort['feature_importance'] 열에 할당 합니다.
## 모델 feature_importances 확인하는 방법은 .feature_importances_ 함수를 사용합니다.
importance_sort['feature_importance'] = hpt_xgb_model.feature_importances_
importance_sort
중요도 순으로 인덱스 재정렬, 인덱스 리셋
# 중요도 순으로 인덱스 재 정렬
## importance_sort 데이터프레임을 importance_sort['feature_importance'] 순으로 내림차순 정열 합니다.
## 정렬 후 결과를 확인 합니다.
## 데이터의 순서가 위에 있을 수록 중요도 순위가 높은 feature 입니다.
importance_sort.sort_values(by='feature_importance', ascending=False, inplace=True)
importance_sort
# 인덱스 리셋
## importance_sort['feature_importance'] 내림차순 때문에 엉킨 데이터프레임의 인덱스를 리셋 합니다.
## 인덱스 리셋 후 결과를 확인 합니다.
## 중요도 순위가 높은 feature 일수록 인덱스 번호가 낮게 부여 됩니다.
importance_sort.reset_index(drop=True, inplace=True)
importance_sort
중요 150개 재선정
# 중요 feature 150 개 선정
## 중요도로 정렬된 importance_sort['feature_importance']의 상위 150 순위의 feature_name 을 importance_150 변수에 할당 합니다.
## 인덱스 번호가 낮을 수록 중요도 순위가 높은 feature 입니다.
importance_150 = importance_sort['feature_name'][:150]
importance_150
훈련 데이터 생성
# importance_150 훈련 데이터 생성
# x_train 에서 importance_150 순위에 해당하는 feature 만 찾아 x_train_150 변수에 할당 합니다.
# x_val 에서 importance_150 순위에 해당하는 feature 만 찾아 x_val_150 변수에 할당 합니다.
# 상위 150 순위의 feature 인덱싱은 importance_150 사용 합니다.
x_train_150 = x_train[importance_150]
x_val_150 = x_val[importance_150]
AI 모델링 학습, 선언, 예측
# AI 모델링
## XGBClassifier 함수를 사용하여 hpt_xgb_150_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 파라미터는 params 변수와 random_state=2023 으로 설정해 주세요.
## 모델이 생성되면 x_train_150, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val_150의 결과를 예측하고 출력 합니다.
hpt_xgb_150_model = XGBClassifier(params, random_state=2023)
hpt_xgb_150_model.fit(x_train_150, y_train)
hpt_xgb_150_pred = hpt_xgb_150_model.predict(x_val_150)
hpt_xgb_150_pred
평가
# hpt_xgb_150_model 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,hpt_xgb_150_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,hpt_xgb_150_pred))
print('\n classification_report: \n',classification_report(y_val,hpt_xgb_150_pred))
예측 결과 저장
# hpt_xgb_150 예측결과 저장
## result 데이터프레임 6번 인덱스에 'hpt_xgb_150'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[6] = ['hpt_xgb_150', 'train', accuracy_score(y_val, hpt_xgb_150_pred), f1_score(y_val, hpt_xgb_150_pred, average = 'macro')]
result
중요 feature 50개 선정
# 중요 feature 50개 선정
## 중요도로 정렬된 importance_sort['feature_importance']의 상위 50 순위의 feature_name 을 importance_50 변수에 할당 합니다.
## 인덱스 번호가 낮을 수록 중요도 순위가 높은 feature 입니다.
importance_50 = importance_sort['feature_name'][:50]
importance_50
모델링 선언, 훈련, 예측
# importance_50 적용 모델링
## XGBClassifier 모듈에 베스트 파라미터를 적용하여 모델을 생성 및 초기화 합니다.
## 파라미터는 params 변수에 사용된 파라미터와, random_state=2023 으로 설정해 주세요.
## 이때 생성한 모델을 hpt_xgb_50_model 변수에 할당 합니다.
## 모델이 생성되면 x_train_50, y_train으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val_50 의 결과를 예측하고 결과를 hpt_xgb_50_pred 변수에 할당 합니다.
hpt_xgb_50_model = XGBClassifier(learning_rate=0.3, max_depth=3, random_state=2023)
hpt_xgb_50_model.fit(x_train_50, y_train)
hpt_xgb_50_pred = hpt_xgb_50_model.predict(x_val_50)
hpt_xgb_50_pred
평가
# hpt_xgb_50_model 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,hpt_xgb_50_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,hpt_xgb_50_pred))
print('\n classification_report: \n',classification_report(y_val,hpt_xgb_50_pred))
예측 결과 저장
# hpt_xgb_50 모델 예측결과 저장
## result 데이터프레임 7번 인덱스에 'hpt_xgb_50'(모델명), 'train' (검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[7] = ['hpt_xgb_50', 'train', accuracy_score(y_val, hpt_xgb_50_pred), f1_score(y_val, hpt_xgb_50_pred, average = 'macro')]
result
# pandas, numpy, matplotlib, seaborn, os 등 필요 라이브러리 호출
## 데이터를 나누기 위한 sklearn.model_selection 모듈의 train_test_split 함수 사용
## 모델 성능 평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 사용
## 추가로 필요한 라이브러리는 설치/호출 하세요
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
tqdm
# 진행상황을 확인 하기 위한 라이브러리
from tqdm import tqdm
데이터 불러오기, 전처리
# 데이터셋 파일 불러오기
## data 변수에 train_data.csv 파일을 불러와서 할당해 주세요.
## train_data.csv 파일은 현재위치의 하위 data 폴더안에 있습니다.
## 변수에 할당이 잘 되었는지 확인해 주세요.
data = pd.read_csv('./data/train_data.csv')
data.head()
# 불필요한 열 제거
## 'subject'열 은 데이터를 수집한 사람을 구별하기 위한 데이터 입니다.
## 'subject'열을 data 데이터프레임 변수 에서 제거해 주세요.
## 'subject'열이 잘 제거 되었는지 확인해 주세요.
data.drop('subject', axis=1, inplace=True)
data
학습 결과 데이터 불러오기
# 데이터셋 파일 불러오기
## result3.csv 파일을 불러와서 result 변수에 할당해 주세요.
## result3.csv 파일은 현재위치의 하위 data 폴더안에 있습니다.
## 변수에 할당이 잘 되었는지 확인해 주세요.
result = pd.read_csv('./data/result3.csv')
result
Hyperparameter Tuning
라이브러리 불러오기
# XGBClassifier 알고리즘 사용을 위한 모듈 추가
# GridSearchCV 을 사용하기 위한 모듈 추가(scikit-learn 라이브러리에 포함)
from xgboost import XGBClassifier
from sklearn.model_selection import GridSearchCV
데이터 전처리
# X, Y 데이터 나누기
## y 변수에 target으로 사용할 data['Activity']을 할당해 주세요.
## data 에서 data['Activity'] 열을 뺀 나머지 x 변수에 할당해 주세요.
y = data['Activity']
x = data.drop('Activity', axis=1)
# target 값 변경
## XGBoost 는 문자형 데이터로 학습할 수 없습니다.
## target 데이터인 y 변수를 숫자형 형태로 치환하여 각각 y_map 변수에 할당해 주세요.
## 데이터 치환 함수: map
# 치환 데이터: 'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5
y_map = y.map({'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5})
y_map
# 학습 데이터 나누기
## 학습에 필요한 x 와 y_map 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: x_train, x_val, y_train, y_val
x_train, x_val, y_train, y_val = train_test_split(x,y_map,train_size=0.7,random_state=2023)
하이퍼 파라미터 찾기
# 하이퍼 파라미터 찾기
## 파라미터 그리드를 생성할 initial_params 변수를 생성 후 파라미터의 범위를 할당 합니다.
## initial_params 파라미터 범위: {'learning_rate': [0.1, 0.2, 0.3], 'max_depth': [2,3,4]}
## XGBClassifier 모듈을 초기화(random_state=2023) 해서 xgb_model 변수에 할당 합니다.
## GridSearchCV 에 아래의 파라미터를 적용한 뒤 모델을 학습합니다.
## GridSearchCV 파라미터: estimator=xgb_model, param_grid=initial_params, cv=3, verbose=2
## GridSearchCV가 적용된 모델을 hpt_xgb_model 변수에 할당 합니다.
## GridSearchCV가 적용된 모델의 예측결과를 hpt_xgb_pred 변수에 할당 합니다.
## 그리드 서칭은 실습 노트북 기준 약 20분이 소요 됩니다.(실행해 놓고 티 타임)
initial_params = {'learning_rate': [0.1, 0.2, 0.3], 'max_depth': [2,3,4]}
xgb_model = XGBClassifier(random_state=2023)
hpt_xgb_model = GridSearchCV(estimator=xgb_model, param_grid=initial_params, cv=3, verbose=2)
hpt_xgb_model.fit(x_train, y_train)
hpt_xgb_pred = hpt_xgb_model.predict(x_val)
ㆍ GridSearchCV를 사용하면 지정한 파라미터 그리드에서 최적의 파라미터 조합을 찾아내고, 해당 조합으로 모델을 학습시킵니다.
ㆍ hpt_xgb_model.fit(x_train, y_train)을 실행한 후에는 hpt_xgb_model 객체가 최적의 파라미터로 학습된 XGBClassifier 모델을 포함
그리드 서치를 통한 모델 정확도 출력
# 그리드 서치를 적용한 모델 정확도 출력
## 그리드 서치에서 학습한 모델의 accuracy_score를 출력 합니다.
print('accuracy_score: ', accuracy_score(y_val,hpt_xgb_pred))
최적 파라미터 확인
# 최적 파라미터 확인
## GridSearchCV 실핼 후 최적의 성능 모델링에 사용된 베스트 파라미터를 params 변수에 할당 합니다.
## 베스트 파라미터 확인 매서드: .best_params_
params = hpt_xgb_model.best_params_
params
모델 선언, 학습, 예측
# 베스트 파라미터 적용 모델링
## XGBClassifier 모듈에 베스트 파라미터를 적용하여 모델을 생성 및 초기화 합니다.
## 파라미터는 params 변수에 사용된 파라미터와, random_state=2023 으로 설정해 주세요.
## 이때 생성한 모델을 hpt_xgb_model 변수에 할당 합니다.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 결과를 hpt_xgb_pred 변수에 할당 합니다.
hpt_xgb_model = XGBClassifier(params, random_state=2023)
hpt_xgb_model.fit(x_train, y_train)
hpt_xgb_pred = hpt_xgb_model.predict(x_val)
hpt_xgb_pred
평가
# hpt_xgb_model 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,hpt_xgb_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,hpt_xgb_pred))
print('\n classification_report: \n',classification_report(y_val,hpt_xgb_pred))
예측 결과
# 하이퍼 파라미터 튜닝 XGB 예측결과 저장
## result 데이터프레임 5번 인덱스에 'hpt_xgb'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[5] = ['hpt_xgb', 'train', accuracy_score(y_val, hpt_xgb_pred), f1_score(y_val, hpt_xgb_pred, average = 'macro')]
result
Aivle 미니 프로젝트 3차_3] SVM, KNN, Logistic Regression, GBM, XGB
데이터 불러오기, 전처리
# pandas, numpy, matplotlib, seaborn, os 등 필요 라이브러리 호출
# 데이터를 나누기 위한 sklearn.model_selection 모듈의 train_test_split 함수 사용
# 모델 성능 평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 사용
## 추가로 필요한 라이브러리는 설치/호출 하세요
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
# 데이터셋 파일 불러오기
## data 변수에 train_data.csv 파일을 불러와서 할당해 주세요.
## train_data.csv 파일은 현재위치의 하위 data 폴더안에 있습니다.
## 변수에 할당이 잘 되었는지 확인해 주세요.
data = pd.read_csv('./data/train_data.csv')
data
# 불필요한 열 제거
## 'subject'열 은 데이터를 수집한 사람을 구별하기 위한 데이터 입니다.
## 'subject'열을 data 데이터프레임 변수 에서 제거해 주세요.
## 'subject'열이 잘 제거 되었는지 확인해 주세요.
data.drop('subject', axis=1, inplace=True)
data
# 모델 결과 저장 데이터 프레임 생성
## result 데이터프레임 생성 및 아래와 같은 컬럼을 생성해 주세요.
## result 컬럼명: 'model_name', 'valid_data', 'accuracy_score', 'f1_score'
result = pd.DataFrame(columns=['model_name', 'valid_data', 'accuracy_score', 'f1_score'])
result
다양한 모델링
SVM
데이터 불러오기
# SVM 라이브러리 설치(scikit-learn에 포함)
#!pip install scikit-learn
# SVM(Support Vector Machine) 알고리즘 모듈 호출
## 분류 모델 생성을 위해 sklearn.svm(Support Vector Machine) 라이브러리의 SVC 알고리즘 호출 합니다.
from sklearn.svm import SVC
데이터 전처리
# 데이터 나누기
## y 변수에 target으로 사용할 data['Activity']을 할당해 주세요.
## data 에서 data['Activity'] 열을 뺀 나머지 x 변수에 할당해 주세요.
## 학습에 필요한 x 와 y 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: x_train, x_val, y_train, y_val
y = data['Activity']
x = data.drop('Activity', axis=1)
x_train, x_val, y_train, y_val = train_test_split(x,y,train_size=0.7,random_state=2023)
모델링 선언, 학습, 예측
# AI 모델링
## SVC 알고리즘 사용하여 svc_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 출력 합니다.
svc_model = SVC(random_state=2023)
svc_model.fit(x_train, y_train)
svc_pred = svc_model.predict(x_val)
svc_pred
평가
# SVC 모델 성능 평가 하기(accuracy_score, confusion_matrix, classification_report)
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,svc_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,svc_pred))
print('\n classification_report: \n',classification_report(y_val,svc_pred))
SVM 예측 결과 저장
# SVC 예측결과 저장
## result 데이터프레임 0번 인덱스의 각 열에 SVC 예측결과인 'svc'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## 데이터프레임의 특정 행(인덱스)에 데이터를 삽입 하려면 .loc[인덱스] 매서드를 사용합니다.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[0] = ['svc', 'train', accuracy_score(y_val,svc_pred), f1_score(y_val,svc_pred,average='macro')]
result
Logistic Regression 모델링
라이브러리 호출
# LogisticRegression 라이브러리 설치(scikit-learn에 포함)
#!pip install scikit-learn
# LogisticRegression 알고리즘 모듈 호출
## 분류 모델 생성을 위해 sklearn.linear_model 라이브러리의 LogisticRegression 알고리즘 호출 합니다.
from sklearn.linear_model import LogisticRegression
모델링 선언,학습 예측
# AI 모델링
## LogisticRegression 사용하여 lr_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 출력 합니다.
lr_model = LogisticRegression(random_state=2023)
lr_model.fit(x_train, y_train)
lr_pred = lr_model.predict(x_val)
lr_pred
평가
# LogisticRegression 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,lr_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,lr_pred))
print('\n classification_report: \n',classification_report(y_val,lr_pred))
예측 결과 저장
# LogisticRegression 예측결과 저장
## result 데이터프레임 1번 인덱스의 각 열에 LogisticRegression 예측결과인 'lr'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## 데이터프레임의 특정 행(인덱스)에 데이터를 삽입 하려면 .loc[인덱스] 매서드를 사용합니다.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[1] = ['lr', 'train', accuracy_score(y_val,lr_pred), f1_score(y_val,lr_pred,average='macro')]
result
KNN
라이브러리 불러오기
# NeighborsClassifier 라이브러리 설치(scikit-learn에 포함)
#!pip install scikit-learn
# AI 모델링 필요 모듈 추가
# NeighborsClassifier 알고리즘 사용을 위해 라이브러리를 호출 합니다.
from sklearn.neighbors import KNeighborsClassifier
선언, 학습, 예측
# AI 모델링
## KNeighborsClassifier 함수를 사용하여 knn_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 n_neighbors=3 으로 설정해 주세요.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 출력 합니다.
## knn 모델 초기화,학습,예측(파라미터: n_neighbors=3, random_state=2023)
## AI모델 변수명: knn_model , 예측결과 변수명: knn_pred
## predict 과정에서 아래의 에러가 날 경우 예측 데이터를 np.array 데이터 형식으로 바꾸어서 진행 보세요.
## 에러 메세지: 'Flags' object has no attribute 'c_contiguous'
## 해결 방법: predict(x_val) -> predict(np.array(x_val))
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_train, y_train)
knn_pred = knn_model.predict(np.array(x_val))
knn_pred
성능평가
# KNN 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,knn_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,knn_pred))
print('\n classification_report: \n',classification_report(y_val,knn_pred))
예측 결과 저장
# KNeighborsClassifier 예측결과 저장
## result 데이터프레임 2번 인덱스의 각 열에 KNeighborsClassifier 예측결과인 'knn'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## 데이터프레임의 특정 행(인덱스)에 데이터를 삽입 하려면 .loc[인덱스] 매서드를 사용합니다.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[2] = ['knn', 'train', accuracy_score(y_val,knn_pred), f1_score(y_val,knn_pred,average='macro')]
result
GBM
불러오기
# GBM 라이브러리 설치(scikit-learn에 포함)
#!pip install scikit-learn
# GradientBoostingClassifier 알고리즘 사용을 위한 모듈 추가
from sklearn.ensemble import GradientBoostingClassifier
선언, 학습, 예측
# AI 모델링
## GradientBoostingClassifier 함수를 사용하여 gbc_model 변수에 모델을 생성 및 초기화 합니다.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 출력 합니다.
## GradientBoosting 모델 학습은 실습 노트북 기준 약 20분정도 소요 됩니다.(돌려 놓고 티타임~)
gbc_model = GradientBoostingClassifier(random_state=2023)
gbc_model.fit(x_train, y_train)
gbc_pred = gbc_model.predict(x_val)
gbc_pred
평가
# GBM(GBC) 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,gbc_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,gbc_pred))
print('\n classification_report: \n',classification_report(y_val,gbc_pred))
XGB
불러오기
# XGBClassifier 사용을 위한 xgboost 라이브러리 설치
#!pip install xgboost
# XGBClassifier 알고리즘 사용을 위한 모듈 추가
from xgboost import XGBClassifier
전처리
# target 값 변경
## XGBoost 는 문자형 데이터로 학습할 수 없습니다.
## target 데이터인 y_trian과 y_val 변수를 숫자형 형태로 치환하여 각각 y_train_map, y_val_map 변수에 할당해 주세요.
## 데이터 치환 함수: map
## 치환 데이터: 'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5
y_train_map = y_train.map({'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5})
y_val_map = y_val.map({'STANDING':0, 'SITTING':1, 'LAYING':2, 'WALKING':3, 'WALKING_UPSTAIRS':4, 'WALKING_DOWNSTAIRS':5}
선언, 학습, 예측
# AI 모델링
## XGBClassifier 함수를 사용하여 xgb_model 변수에 모델을 생성 및 초기화 합니다.
## 모델의 파라미터는 learning_rate=0.2, max_depth=2, random_state=2023 으로 설정해 주세요.
## 모델이 생성되면 x_train, y_train 으로 모델을 학습시켜 줍니다.
## 모델 학습이 완료되면 x_val의 결과를 예측하고 출력 합니다.
xgb_model = XGBClassifier(learning_rate=0.2, max_depth=2, random_state=2023)
xgb_model.fit(x_train, y_train_map)
xgb_pred = xgb_model.predict(x_val)
xgb_pred
평가
# 모델 평가 출력(accuracy_score, confusion_matrix, classification_report)
print('accuracy_score: ',accuracy_score(y_val_map,xgb_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val_map,xgb_pred))
print('\n classification_report: \n',classification_report(y_val_map,xgb_pred))
결과 저장
# XGBClassifier 예측결과 저장
## result 데이터프레임 4번 인덱스에 모델 'xgb'(모델명), 'train'(검증 데이터명), accuracy_score 결과, f1_score 결과를 할당해 주세요.
## 데이터프레임의 특정 행(인덱스)에 데이터를 삽입 하려면 .loc[인덱스] 매서드를 사용합니다.
## f1_score의 평균은 'macro' 파라미터를 사용 합니다.
## 예측 결과가 잘 할당 되었는지 확인해 주세요.
result.loc[4] = ['xgb', 'train', accuracy_score(y_val_map,xgb_pred), f1_score(y_val_map,xgb_pred,average='macro')]
result
결과 저장 및 시각화
저장 및 저장 여부 확인
# 결과 저장
# result 변수를 인덱스 미포함하여 'result3.csv' 파일로 저장 합니다.
# 저장경로는 현재 경로의 하위 './data' 폴더로 지정해 주세요.
result.to_csv('./data/result3.csv', index=False)
# 저장 여부 확인
## 데이터가 파일로 잘 저장 되었는지 result3.csv 파일을 로드하여 확인 합니다.
## 로드한 데이터는 save_check 변수에 할당해 주세요.
save_check = pd.read_csv('./data/result3.csv')
save_check
컬럼 인덱스 변환
# 컬럼-인덱스 변환
## save_check 데이터 프레임의 ['model_name', 'valid_data'] 컬럼을 지정하여 인덱스로 설정해 줍니다.
## 변환한 값은 result_comp 변수에 할당해 주세요.
## 참고함수: set_index
result_comp = save_check.set_index(['model_name','valid_data'])
result_comp
시각화
# 모델별 결과 시각화
# pandas의 plot 함수을 사용하여 AI모델 별 accuracy_score, f1_score 수직 그래프 시각화 합니다.
# grid를 추가해 주세요.
# legend를 표시하고, 위치는 center 입니다.
result_comp.plot(kind='bar')
plt.grid()
plt.legend(loc='center')
plt.show()
# features.csv 파일 불러오기
## 'data'폴더에서 features.csv 파일을 읽어와 feature_group 변수에 할당 하세요.
## 변수에 할당이 잘 되었는지 확인해 주세요.
feature_group =pd.read_csv('./data/features.csv')
display(feature_group)
# importance_sort 데이터 프레임 확인
# importance_sort 데이터프레임 사용전 데이터를 다시한번 확인 합니다.
importance_sort
데이터 merge
# 데이터프레임 merge
## merge_df 변수를 데이터프레임 타입으로 생성 및 초기화 합니다.
## feature_group 변수와 importance_sort 변수를 merge 하여 merge_df 변수에 할당 합니다
## 데이터가 잘 할당 되었나 merge_df 데이터를 확인 합니다.
merge_df = pd.DataFrame()
merge_df = pd.merge(feature_group, importance_sort)
merge_df
그룹화
# 데이터 그룹화
## merge_df 변수를 'sensor' 기준으로 그룹화 하고,
## 'feature_importance' 열의 데이터를 같은 'sensor' 그룹끼리 더해 줍니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 덧셈을 동시에 수행할 수 있습니다.'
## 그룹화 및 덧셈을 수행한 결과를 sensor_sum 변수에 할당해 주세요.
## [TIP] 변수.groupby(by='그룹기준열')['연산 할 열'].연산메서드()
sensor_sum = merge_df.groupby(by='sensor')['feature_importance'].sum()
sensor_sum
# sensor 중요도 재정렬
## sensor_sum 데이터를 내림차순으로 정렬 후 sensor_sort 변수에 할당합니다.
## sensor_sum 변수를 데이터프레임으로 생성했을 경우 기준(by=)을 지정해 주어야 합니다.
sensor_sort = sensor_sum.sort_values(ascending=False)
sensor_sort
센서별 중요도 시각화
# 센서별 중요도 시각화
# sensor 별 중요도를 수평막대 그래프로 시각화 합니다.
# matploltlib를 사용하여 sensor 별 중요도를 수평막대 그래프로 시각화 합니다.
# sensor_sort가 시리즈 타입 일시
plt.barh(y=sensor_sort.index, width=sensor_sort)
plt.xticks(rotation = 90)
plt.grid()
plt.show()
# sensor_sort가 데이터프레임 타입 일시
# plt.barh(data = sensor_sort, y=sensor_sort.index, width='feature_importance')
# plt.xticks(rotation = 90)
# plt.grid()
# plt.show()
# seaborn 라이브러리 사용 sensor 별 중요도 시각화
## seaborn 라이브러리를 사용하여 sensor 별 중요도를 시각화 해보세요.
sns.barplot(x=sensor_sort, y=sensor_sort.index, orient='h')
plt.xticks(rotation = 90)
plt.grid()
plt.show()
# sensor_sort가 데이터프레임 시
# sns.barplot(x=sensor_sort['feature_importance'], y=sensor_sort.index, orient='h')
# plt.xticks(rotation = 90, )
# plt.grid()
# plt.show()
sensor_agg 별 상위 20 중요도 시각화
# 데이터 그룹화
## merge_df 변수를 ['sensor','agg'] 기준으로 그룹화 하고 'feature_importance' 열의 데이터를 같은 그룹끼리 더해 sensor_agg_sum 변수에 할당 합니다.
## groupby 함수는 데이터프레임을 그룹으로 묶으면서 필요한 계산을 동시에 수행할 수 있습니다.
sensor_agg_sum = merge_df.groupby(['sensor','agg'])['feature_importance'].sum()
sensor_agg_sum
# Top20 센서 중요도 시각화
## 중요도가 높은 센서 20개의 중요도를 수평 막대그래프로 시각화 합니다.
## [HINT] Pandas의 plot 함수를 사용
sensor_agg_sort[:20].plot(kind='barh')
plt.grid()
plt.show()
sensor 별 agg 중요도 누적 그래프 시각화
데이터 재구조화
# sensor_agg_sort 데이터 재 구조화
# sensor_agg_sort 데이터셋의 'agg'열의 고유값들을 sensor_agg_sort 데이터셋의 컬럼으로 변환(재구조화) 합니다.
# 재구조화 한 데이터를 acc 변수에 할당 합니다.
# 참고함수: unstack()
acc = sensor_agg_sort.unstack()
acc
센서별 합계 재정렬
# 센서별 합계 재정렬
## acc 데이터의 각 센서의 행 방향으로(axis=1) 모든 값을 더해서 acc['sort'] 에 할당 합니다.
## 할당 후 acc 데이터를 acc['sort'] 열의 값 기준으로 내림차순으로 정렬 합니다.
## 정렬 후 데이터를 확인 합니다.
acc['sort'] = acc.sum(axis=1)
acc.sort_values(by = 'sort', ascending = False, inplace=True)
acc
# pandas, numpy, matplotlib.pyplot, seaborn, os 등 필요 라이브러리 호출
## 추가로 필요한 라이브러리는 설치/호출 하세요.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
데이터 전처리
# 데이터셋 파일 불러오기
## data 변수에 train_data.csv 파일을 불러와서 할당해 주세요.
## train_data.csv 파일은 현재위치의 하위 data 폴더안에 있습니다.
## 변수에 할당이 잘 되었는지 확인해 주세요.
data = pd.read_csv('./data/train_data.csv')
data
# 불필요한 열 제거
## 'subject'열 은 데이터를 수집한 사람을 구별하기 위한 데이터 입니다.
## 'subject'열을 data 데이터프레임 변수 에서 제거해 주세요.
## 'subject'열이 잘 제거 되었는지 확인해 주세요.
data.drop('subject', axis=1, inplace=True)
data
# RandomForestClassifier 알고리즘 불러오기
## AI 모델링을 위해 sklearn.ensemble 라이브러리의 RandomForestClassifier 알고리즘 호출 합니다.
## 데이터를 나누기 위해 sklearn.model_selection 모듈의 train_test_split 함수를 호출 합니다.
## 모델 성능평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 호출 합니다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
# X, Y 데이터 나누기
## y 변수에 target으로 사용할 data['Activity']을 할당해 주세요.
## data 에서 data['Activity'] 열을 뺀 나머지 x 변수에 할당해 주세요.
y = data['Activity']
x = data.drop('Activity', axis=1)
# 학습 데이터 나누기
## 학습에 필요한 x 와 y 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: x_train, x_val, y_train, y_val
x_train, x_val, y_train, y_val = train_test_split(x,y,train_size=0.7,random_state=2023)
선언, 학습, 예측
# AI 모델링
# 모델 선언, 학습, 예측
## rf_model 변수에 RandomForestClassifier 함수를 사용하여 모델을 호출 및 초기화 합니다.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 생성한 rf_model 모델 변수에 x_train, y_train 데이터를 대입하여 모델을 학습시킵니다.
## 학습이 완료된 모델에 x_val 데이터를 대입하여 예측결과를 도출하고 rf_pred 변수에 할당 합니다.
rf_model = RandomForestClassifier(random_state=2023)
rf_model.fit(x_train, y_train)
rf_pred = rf_model.predict(x_val)
rf_pred
평가
# 모델 성능 평가 하기
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,rf_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,rf_pred))
print('\n classification_report: \n',classification_report(y_val,rf_pred))
변수별 중요도 추출
중요도 데이터프레임
# 중요도 데이터프레임 변수 생성
## importance_sort 변수를 판다스 데이터프레임 타입으로 생성 및 초기화 합니다.
importance_sort = pd.DataFrame()
# feature명 할당
## importance_sort['feature_name'] 열에 모델링에서 사용한 x 데이터셋의 feature명을 할당 합니다.
importance_sort['feature_name'] = x.columns
# feature 중요도 할당
# 모델링에서 사용한 모델의 feature_importances 를 importance_sort['feature_importance'] 열에 할당 합니다.
# 모델 feature_importances 확인하는 방법은 .feature_importances_ 매서드를 사용합니다.
# ex: 모델명.feature_importances_
importance_sort['feature_importance'] = rf_model.feature_importances_
# 데이터 프레임 확인
# importance_sort 데이터프레임에 데이터가 제대로 할당 되었는지 확인 합니다.
importance_sort
중요도 순으로 재정렬
# 중요도 순으로 인덱스 재정렬
## importance_sort 데이터프레임을 importance_sort['feature_importance'] 순으로 내림차순 정열 합니다.
## 정렬 후 결과를 확인 합니다.
## 참고함수: sort_values
## 참고 파라미터: by='feature_importance', ascending=False, inplace=True
importance_sort.sort_values(by='feature_importance', ascending=False, inplace= True)
importance_sort
인덱스 리셋
# 인덱스 리셋
## importance_sort['feature_importance'] 내림차순 때문에 엉킨 데이터프레임의 인덱스를 리셋 합니다.
## 인덱스 리셋 후 결과를 확인 합니다.
## 참고함수: reset_index (위에서 부터 0 -> 아래로 갈수록 +1)
## 참고 파라미터: inplace=True, drop=True
importance_sort.reset_index(inplace=True, drop=True)
importance_sort
feature 별 중요도 시각화
# feature별 중요도 시각화
## sns.barplot을 사용하여 feature(feature) 별 중요도를 시각화 합니다.
## 그래프 사이즈: (10,100)
## 파라미터: data = importance_sort, x='feature_importance', y='feature_name'
## x축 label을 'feature_importance' 으로, y축 label 을 'feature_name' 으로 설정해 주세요.
plt.figure(figsize=(10,100))
sns.barplot(data = importance_sort, x='feature_importance', y='feature_name')
plt.xlabel('feature_importance')
plt.ylabel('feature_name')
plt.show()
영향도 상위/하위 중요 feature 데이터 분석
상위 5개 중요 feature 확인
# 중요도 상위 5개 중요 feature 확인
## head 함수를 사용하여 중요도 상위 top 5 feature의 feature_name 과 feature_importance 확인하세요.
## 행동 분류에 영향을 미치는 feature의 중요도는 importance_sort 변수를 참고 하세요.
importance_sort.head()
상위 5개 feature 시각화(boxplot 그래프)
상위 1위 feature에 대한 시각화
# 상위 1위 feature_name에 대한 BoxPlot 그래프 그리기
## f_name 변수를 생성하여 상위 1위 feature의 컬럼명을 할당해 줍니다.
## sns.boxplot를 사용하여 data 데이터 프레임의 데이터 분포를 시각화 합니다.
## 파라미터: x=f_name, y='Activity', data=data
f_name = 'tGravityAcc-min()-X'
sns.boxplot(x=f_name, y='Activity', data=data)
plt.show()
상위 2위 feature에 대한 시각화
# 상위 2위 feature_name에 대한 BoxPlot 그래프 그리기
## f_name 변수를 생성하여 상위 2위 feature의 컬럼명을 할당해 줍니다.
## sns.boxplot를 사용하여 data 데이터 프레임의 데이터 분포를 시각화 합니다.
## 파라미터: x=f_name, y='Activity', data=data
f_name = 'tGravityAcc-max()-X'
sns.boxplot(x=f_name, y='Activity', data=data)
plt.show()
하위 3개 feature 시각화(boxplot 그래프)
# 중요도 하위 3개 중요 feature 확인
## tail 함수를 사용하여 중요도 하위 3개의 feature의 feature_name 과 feature_importance 확인하세요.
## 행동 분류에 영향을 미치는 feature의 중요도는 importance_sort 변수를 참고 하세요.
importance_sort.tail(3)
하위 1위
# 하위 1위 feature_name에 대한 BoxPlot 그래프 그리기
## f_name 변수를 생성하여 하위 1위 feature의 컬럼명을 할당해 줍니다.
## sns.boxplot를 사용하여 data 데이터 프레임의 데이터 분포를 시각화 합니다.
## 파라미터: x=f_name, y='Activity', data=data
f_name = importance_sort['feature_name'].iloc[-1]
sns.boxplot(x=f_name, y='Activity', data=data)
plt.show()
하위 2위
# 하위 2위 feature_name에 대한 BoxPlot 그래프 그리기
## f_name 변수를 생성하여 하위 2위 feature의 컬럼명을 할당해 줍니다.
## sns.boxplot를 사용하여 data 데이터 프레임의 데이터 분포를 시각화 합니다.
## 파라미터: x=f_name, y='Activity', data=data
f_name = importance_sort['feature_name'].iloc[-2]
sns.boxplot(x=f_name, y='Activity', data=data)
plt.show()
하위 3개 시각화 한 번에 하기
# 하위 3개의 BoxPlot 그래프 시각화
## for 문을 이용하여 하위 3개의 feature에 대한 BoxPlot 차트들을 한 번에 시각화 합니다.
## 그래프의 위치는 하위1(상), 하위2(중), 하위3(하) 순서로 표시 합니다.
for i in range(-1,-4,-1):
f_name = importance_sort['feature_name'].iloc[i]
sns.boxplot(x=f_name, y='Activity', data=data)
plt.show()
# RandomForestClassifier 알고리즘 불러오기
## AI 모델링을 위해 sklearn.ensemble 라이브러리의 RandomForestClassifier 알고리즘 호출 합니다.
## 데이터를 나누기 위해 sklearn.model_selection 모듈의 train_test_split 함수를 호출 합니다.
## 모델 성능평가 출력을 위해 sklearn.metrics 모듈의 모든 클래스 호출 합니다.
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import *
데이터 처리
# 모델 학습을 위한 X, Y 데이터 나누기
## y 변수에 target으로 사용할 data['Activity']을 할당해 주세요.
## data 에서 data['Activity'] 열을 뺀 나머지 x 변수에 할당해 주세요.
y = data['Activity']
x = data.drop('Activity', axis=1)
# 데이터 나누기
## 학습에 필요한 x 와 y 데이터를 학습 7 : 검증 3 비율로 나누어 주세요.
## 이때 random_state 는 2023 으로 설정해 주세요.
## 데이터를 할당받을 변수명: x_train, x_val, y_train, y_val
x_train, x_val, y_train, y_val = train_test_split(x,y,train_size=0.7, random_state=2023)
모델 선언, 학습, 예측
# 모델 선언하기
## rf_model 변수에 RandomForestClassifier 함수를 사용하여 모델을 호출 및 초기화 합니다.
## 이때 random_state 는 2023 으로 설정해 주세요.
rf_model = RandomForestClassifier(random_state=2023)
# 모델 학습하기
## 생성한 rf_model 모델 변수에 x_train, y_train 데이터를 대입하여 모델을 학습시킵니다.
rf_model.fit(x_train, y_train)
# 모델 예측하기
## 학습이 완료된 모델에 x_val 데이터를 대입하여 예측결과를 도출하고 rf_pred 변수에 할당 합니다.
rf_pred = rf_model.predict(x_val)
rf_pred
모델 성능 평가
# 모델 성능 평가
## 모델이 결과를 잘 예측하였는지 3가지 성능지표로 결과를 평가 합니다.
## 3가지 성능지표: accuracy_score, confusion_matrix, classification_report
print('accuracy_score: ',accuracy_score(y_val,rf_pred))
print('\n confusion_matrix: \n',confusion_matrix(y_val,rf_pred))
print('\n classification_report: \n',classification_report(y_val,rf_pred))
- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
ㆍ 카이제곱 검정
- 귀무가설 : 두 집단의 빈도 분포가 독립적이다.
- p-value < 0.05 : 귀무 가설 기각, 두 집단의 빈도 분포가 독립적이지 않을 것이다.
ㆍ ANOVA
- 귀무가설 : 집단(세 개 이상)의 평균 간에 차이가 없을 것이다.
- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
(1) Gender
plt.figure(figsize = (15,8))
sns.barplot(x='Gender', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['Gender'].value_counts()
## 평균 분석 : ttest_ind
t_male = base_data.loc[base_data['Gender']=='M', 'Score_diff_total']
t_female = base_data.loc[base_data['Gender']=='F', 'Score_diff_total']
spst.ttest_ind(t_male, t_female)
3-2-2) 학습목표
# 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습목표', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습목표'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['학습목표']=='승진', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습목표']=='자기계발', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습목표']=='취업', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
3-2-3) 학습방법
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습방법', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습방법'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['학습방법']=='온라인강의', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습방법']=='오프라인강의', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습방법']=='참고서', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
3-2-4) 강의 학습 교재 유형
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='강의 학습 교재 유형', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['강의 학습 교재 유형'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['강의 학습 교재 유형']=='일반적인 영어 텍스트 기반 교재', 'Score_diff_total']
anova_2 = base_data.loc[base_data['강의 학습 교재 유형']=='영상 교재', 'Score_diff_total']
anova_3 = base_data.loc[base_data['강의 학습 교재 유형']=='뉴스/이슈 기반 교재', 'Score_diff_total']
anova_4 = base_data.loc[base_data['강의 학습 교재 유형']=='비즈니스 시뮬레이션(Role Play)', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3, anova_4)
3-2-6) 취약분야 인지 여부
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='취약분야 인지 여부', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['취약분야 인지 여부'].value_counts()
## 평균 분석 : ttest_ind
t_yes = base_data.loc[base_data['취약분야 인지 여부']=='알고 있음', 'Score_diff_total']
t_no = base_data.loc[base_data['취약분야 인지 여부']=='알고 있지 않음', 'Score_diff_total']
spst.ttest_ind(t_yes, t_no)
대상 변수 : 'Birth_Year', '기출문제 공부 횟수','토익 모의테스트 횟수', '1st_Total_Score', '2st_Total_Score'
2-3-1) Bitrh_Year
## 수치형 변수의 기초 통계량 확인 : describe
display(base_data[['Birth_Year']].describe().T)
## 그래프 분석 : histplot, boxplot
plt.figure(figsize = (12,8))
plt.subplot(2,1,1)
## 히스토그램을 이용한 데이터 분포 확인
sns.histplot(x = 'Birth_Year', data = base_data, kde = True, bins = 35)
plt.grid()
plt.subplot(2,1,2)
## boxplot 이용한 데이터 분포 확인
sns.boxplot(x = 'Birth_Year', data = base_data)
plt.grid()
plt.show()
2-3-2) 기출문제 공부 횟수
## 수치형 변수의 기초 통계량 확인 : describe
display(base_data[['기출문제 공부 횟수']].describe().T)
## 그래프 분석 : histplot, boxplot
plt.figure(figsize = (12,8))
plt.subplot(2,1,1)
## 히스토그램을 이용한 데이터 분포 확인
sns.histplot(x = '기출문제 공부 횟수', data = base_data, kde = True)
plt.grid()
plt.subplot(2,1,2)
## boxplot 이용한 데이터 분포 확인
sns.boxplot(x = '기출문제 공부 횟수', data = base_data)
plt.grid()
plt.show()
2-3-3) 토익 모의테스트 횟수
## 수치형 변수의 기초 통계량 확인 : describe
display(base_data[['토익 모의테스트 횟수']].describe().T)
## 그래프 분석 : histplot, boxplot
plt.figure(figsize = (12,8))
plt.subplot(2,1,1)
## 히스토그램을 이용한 데이터 분포 확인
sns.histplot(x = '토익 모의테스트 횟수', data = base_data, kde = True)
plt.grid()
plt.subplot(2,1,2)
## boxplot 이용한 데이터 분포 확인
sns.boxplot(x = '토익 모의테스트 횟수', data = base_data)
plt.grid()
plt.show()
2-3-4) 1st_Total_Score
## 수치형 변수의 기초 통계량 확인 : describe
display(base_data[['1st_Total_Score']].describe().T)
## 그래프 분석 : histplot, boxplot
plt.figure(figsize = (12,8))
plt.subplot(2,1,1)
## 히스토그램을 이용한 데이터 분포 확인
sns.histplot(x = '1st_Total_Score', data = base_data, kde = True)
plt.grid()
plt.subplot(2,1,2)
## boxplot 이용한 데이터 분포 확인
sns.boxplot(x = '1st_Total_Score', data = base_data)
plt.grid()
plt.show()
2-3-5) 2nd_Total_Score
## 수치형 변수의 기초 통계량 확인 : describe
display(base_data[['2nd_Total_Score']].describe().T)
## 그래프 분석 : histplot, boxplot
plt.figure(figsize = (12,8))
plt.subplot(2,1,1)
## 히스토그램을 이용한 데이터 분포 확인
sns.histplot(x = '2nd_Total_Score', data = base_data, kde = True)
plt.grid()
plt.subplot(2,1,2)
## boxplot 이용한 데이터 분포 확인
sns.boxplot(x = '2nd_Total_Score', data = base_data)
plt.grid()
plt.show()
## tabulate library가 없는 경우 설치 필요
## pandas.to_markdown() 시 tabulate library가 필요함
!pip install tabulate
import pandas as pd
from urllib.parse import quote
from haversine import haversine
import ssl
from urllib.request import urlopen
import numpy as np
context=ssl.create_default_context()
context.set_ciphers("DEFAULT")
#########################################
# 1) 함수 선언하기 #
#########################################
# 함수명 : find_hospital
# 매개변수 : special_m (중증질환명), lati, long (환자 위치)
def find_hospital(special_m, lati, long ):
# [국립중앙의료원 - 전국응급의료기관 조회 서비스] 활용을 위한 개인 일반 인증키(Encoding) 저장
key = "키값"
# city = 대구광역시, 인코딩 필요
city = quote("대구광역시")
############################################################
# 2) 병원 리스트 csv 파일 불러오기 (daegu_hospital_list.csv) #
############################################################
solution_df = pd.read_csv('./daegu_hospital_list.csv')
############################################################
# 3) 병원 실시간 정보 가져오기 #
############################################################
# 응급실 실시간 가용병상
url_realtime = "https://apis.data.go.kr/B552657/ErmctInfoInqireService/getEmrrmRltmUsefulSckbdInfoInqire?serviceKey=" + key + "&STAGE1=" + city + "&numOfRows=100&pageNo=1"
result = urlopen(url_realtime, context=context)
emrRealtime_big = pd.read_xml(result, xpath='//item')
## 응급실 실시간 가용병상 정보에서 기관코드(hpid), 응급실 병상수('hvec'), 수술실 수('hvoc') 정보만 추출하여 emRealtime_small 변수에 저장
## emrRealtime_big 중 [hpid, hvec, hvoc] 컬럼 활용
emrRealtime_small = emrRealtime_big[['hpid', 'hvec', 'hvoc']] ## emrRealtime_big 중 [hpid, hvec, hvoc] 컬럼 활용
# solution_df와 emrRealtime_small 데이터프레임을 결합하여 solution_df에 저장
solution_df = pd.merge(solution_df, emrRealtime_small, on = 'hpid',how='inner')
# 실시간 중증질환자 수용 가능 병원 조회
url_acpt = 'https://apis.data.go.kr/B552657/ErmctInfoInqireService/getSrsillDissAceptncPosblInfoInqire?serviceKey=' + key + "&STAGE1=" +city + "&numOfRows=100&pageNo=1"
result = urlopen(url_acpt, context=context)
emrAcpt_big = pd.read_xml(result, xpath='.//item')
## 다른 API함수와 다르게 기관코드 컬럼명이 다름 (hpid --> dutyName)
## 기관코드 컬렴명을 'hpid'로 일치화시키기 위해, 컬럼명을 변경함
emrAcpt_big.rename(columns = {'dutyName' : 'hpid'}, inplace = True)
## 실시간 중증질환자 수용 가능 병원정보에서 필요한 정보만 추출하여 emrAcpt_small 변수에 저장
## emrAcpt 중 [hpid, MKioskTy1, MKioskTy2, MKioskTy3, MKioskTy4, MKioskTy5, MKioskTy7,MKioskTy8, MKioskTy10, MKioskTy11] 컬럼 확인
emrAcpt_small = emrAcpt_big[['hpid', 'MKioskTy1', 'MKioskTy2', 'MKioskTy3', 'MKioskTy4', 'MKioskTy5', 'MKioskTy7','MKioskTy8', 'MKioskTy10', 'MKioskTy11']]
# solution_df와 emrAcpt_small 데이터프레임을 결합하여 solution_df에 저장
solution_df = pd.merge(solution_df, emrAcpt_small, on = 'hpid',how = 'inner')
############################################################
# 4) 자료 정비하기 #
############################################################
# solution_df의 컬럼명 변경하기
column_change = { 'hpid' : '병원코드',
'dutyName' : '병원명',
'dutyAddr' : '주소',
'dutyTel3' : '응급연락처',
'wgs84Lat' : '위도',
'wgs84Lon' : '경도',
'hperyn' : '응급실수',
'hpopyn' : '수술실수',
'hvec' : '가용응급실수',
'hvoc' : '가용수술실수',
'MKioskTy1' : '뇌출혈',
'MKioskTy2' : '뇌경색',
'MKioskTy3' : '심근경색',
'MKioskTy4' : '복부손상',
'MKioskTy5' : '사지접합',
'MKioskTy7' : '응급투석',
'MKioskTy8' : '조산산모',
'MKioskTy10' : '신생아',
'MKioskTy11' : '중증화상',
}
solution_df = solution_df.rename(columns = column_change)
# 중증질환 수용 가능 여부 데이터 중 정보 미제공, 불가능은 N로 변경 : replace
solution_df = solution_df.replace("정보미제공","N")
solution_df = solution_df.replace("불가능","N")
## 응급실수/가용응급실수, 수술실수/가용수술실 수가 0보다 작은 경우는 비정상 데이터로 추정
## 0보다 작은 수는 0으로 변경
solution_df.loc[solution_df['응급실수']<0, '응급실수'] = 0
solution_df.loc[solution_df['수술실수']<0, '수술실수'] = 0
solution_df.loc[solution_df['가용응급실수']<0, '가용응급실수'] = 0
solution_df.loc[solution_df['가용수술실수']<0, '가용수술실수'] = 0
# 응급실 가용율을 구하여 새로운 컬럼으로 추가하기
# 컬렴명 : '응급실가용율'
# 산식 : 가용 응급실수 / 응급실 수
# 소수 둘째 자리까지 구하기 round() 활용
solution_df['응급실가용율'] = round(solution_df['가용응급실수'] / solution_df['응급실수'], 2)
# 응급실 가용율이 1이 넘는 경우는 1로 대체
solution_df.loc[solution_df['응급실가용율'] > 1, '응급실가용율'] = 1
# 응급실 가용율에 따라 포화도 분류
# 응급실 가용율 구분 단계 : ~0.1, 0.1 ~ 0.3, 0.3 ~ 0.6, 0.6 ~
# 포화도 명칭 : ['불가', '혼잡', '보통', '원활']
# pd.cut() 활용
bins = [-np.inf, 0.1, 0.3, 0.6, np.inf]
labels = ['불가', '혼잡', '보통', '원활']
solution_df['응급실포화도'] = pd.cut(solution_df['응급실가용율'], bins=bins, labels=labels)
############################################################
# 5) 환자 수용 가능한 병원 구하기 #
############################################################
# 매개변수 special_m로 받은 중증질환이 중증질환 리스트에 포함될 경우
# 중증질환 리스트 : ['뇌출혈', '뇌경색', '심근경색', '복부손상', '사지접합', '응급투석', '조산산모', '신생아','중증화상' ]
severe_diseases = ['뇌출혈', '뇌경색', '심근경색', '복부손상', '사지접합', '응급투석', '조산산모', '신생아','중증화상']
if special_m in severe_diseases:
# 조건1 : special_m 중증질환자 수용이 가능하고
# 조건2 : 응급실 포화도가 불가가 아닌 병원
condition1 = (solution_df[special_m] == 'Y') & (solution_df['가용수술실수']>=1)
condition2 = (solution_df['응급실포화도'] != '불가')
# 조건1, 2에 해당되는 응급의료기관 정보를 distance_df에 저장하기
distance_df = solution_df[condition1 & condition2].copy()
# 매개변수 special_m 값이 중증질환 리스트에 포함이 안되는 경우
else:
# 조건1 : 응급실 포화도가 불가가 아닌 병원
condition1 = solution_df['응급실포화도'] != '불가'
# 조건1에 해당되는 응급의료기관 정보를 distance_df에 저장하기
distance_df = solution_df[condition1].copy()
############################################################
# 6) 환자와 병원간 거리 구하기 #
############################################################
distance = []
patient = (lati, long)
for idx, row in distance_df.iterrows():
distance.append(round( haversine(patient,(row['위도'], row['경도']), unit='km') , 2))
distance_df.loc[:,'거리'] = distance.copy()
############################################################
# 7) 거리 구간 구하기 #
############################################################
bins = [-np.inf, 2, 5, 10, np.inf]
labels = ['2km이내', '5km이내', '10km이내', '10km이상']
distance_df.loc[:, '거리구분'] = pd.cut(distance_df['거리'], bins=bins, labels=labels)
############################################################
# 8) 결과값 반환하기 #
############################################################
return distance_df
# 중증환자 수용 가능한, 가까운 병원 조회 #1
# 환자 정보
# - 중증 질환 : 응급투석
# - 환자 위치 : 대구역 근처 (35.8765167, 128.5972922))
# 거리순, 응급실 포화도 순으로 결과 출력하기 (pandas의 sort_values(), to_markdown() 활용)
print(find_hospital('응급투석', 35.8765167, 128.5972922).sort_values(['거리구분', '응급실포화도','거리'], ascending=[True, False, True]).to_markdown())
네이버 지도 API 사용을 위한 헤더 정보
import requests
from urllib.parse import quote
# 네이버 지도 API 사용을 위한 헤더 정보
headers = {
'X-NCP-APIGW-API-KEY-ID': '키',
'X-NCP-APIGW-API-KEY': '키'
}
# 특정 위치 검색 (예: 서문시장)
def get_lat_lng(location):
url = f"https://naveropenapi.apigw.ntruss.com/map-geocode/v2/geocode?query={quote(location)}"
response = requests.get(url, headers=headers)
print(response.text)
if response.status_code == 200:
data = response.json()
if 'addresses' in data and len(data['addresses']) > 0:
lat = data['addresses'][0]['y']
lng = data['addresses'][0]['x']
return (float(lat), float(lng))
return None
# 예제
location_name = "서울특별시 중구 명동길"
patient = get_lat_lng(location_name)
print(patient)
# solution_df와 emrAcpt_small 데이터프레임을 결합하여 solution_df에 저장
# 결합 : merge 함수 활용
solution_df = pd.merge(solution_df, emrAcpt_small, on = 'hpid',how = 'inner')
solution_df.head()
# 대구광역시내이 응급의료기관 목록정보 조회하기
# url : https://apis.data.go.kr/B552657/ErmctInfoInqireService/getEgytBassInfoInqire
# 인증키 지정 : serviceKey = key
# 응급의료기관 지정 : HPID = hpid
# 응급의료기관 하나씩 조회해야 함
# 응급의료기관에 대한 hpid값을 list로 추출
hpidList = list(solution_df['hpid'])
# 각 응급의료기관의 응급실 병상수(hperyn), 수술실 수(hpopyn) 를 저장하기 위한 빈 리스트 생성
hperynList = []
hpopynList = []
# 대구광역시의 응급의료기관을 hpid 기준으로 하나씩 조회하여, 응급실 병상수/수술실 수를 확인
# for문을 이용하여 hpid 하나씩 조회하고, hperyn, hpopyn 정보를 각 hperynList, hpopynList 리스트에 저장
for hpid in hpidList: #
url_basic = f'https://apis.data.go.kr/B552657/ErmctInfoInqireService/getEgytBassInfoInqire?serviceKey={key}&HPID={hpid}'
result = urlopen(url_basic, context=context)
df_temp = pd.read_xml(result, xpath='.//item')
# print(df_temp[['hperyn', 'hpopyn']])
if 'hperyn' in list(df_temp.columns) :
hperynList.append(df_temp['hperyn'][0])
else:
hperynList.append(0)
if 'hpopyn' in list(df_temp.columns) :
hpopynList.append(df_temp['hpopyn'][0])
else:
hpopynList.append(0)
hperynList
# 기존 solution_df에 응급실 숫자, 수술실 숫자 정보 추가하기
solution_df['hperyn'] = hperynList
solution_df['hpopyn'] = hpopynList
hperyn, hpopyn 값이 0 이하인 병원 삭제
# hperyn, hpopyn 값이 0 이하인 병원을 삭제하자
solution_df = solution_df[solution_df['hpopyn']>0]
solution_df = solution_df[solution_df['hperyn']>0]
solution_df.to_csv(''daegu_hospital_list.csv', index = False) # 파일 저장
solution_df = pd.read_csv('./daegu_hospital_list.csv')
solution_df.head() # 정상적으로 저장되었는지 확인한다.
## solution_df 를 파일로 저장
solution_df.to_csv('daegu_hospital_list.csv', index = False) ## 파일명 : daegu_hospital_list.csv, index = False
solution_df = pd.read_csv('./daegu_hospital_list.csv') ## 정상적으로 저장되었는지 확인
solution_df.head()
key = "일반 인증키(Encoding)"
# [국립중앙의료원 - 전국응급의료기관 조회 서비스] 활용을 위한 개인 일반 인증키(Encoding) 값 저장
city = quote("대구광역시") # city = 대구광역시, 인코딩 필요
# 인증키 지정 : serviceKey = key
# 출력 행수 : numOfRows = 100
# page 번호 : pageNo = 1
# 도시 지정 : Q0 = city