house price 예측하기
라이브러리 불러오기
import pandas as pd
데이터 읽기
df = pd.read_csv('kc_houseprice.csv')
display(df.columns)
df.head()

df.info()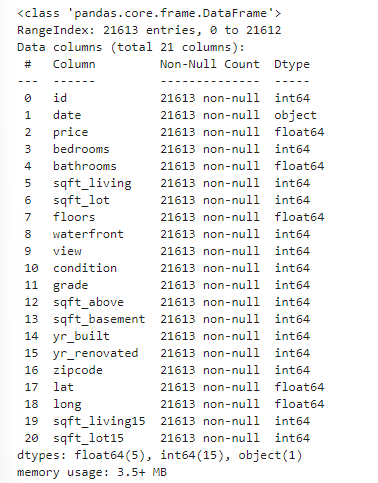
# 현재 date의 데이터만 object 타입임을 확인할 수 있다.
데이터 전처리
# 위에서 date 열을 보면 20141209T~~~~ 형식으로 되어있어서 활용하기 어렵다.
# 따라서 분석에 유효한 앞에 4글자만 가져오도록 한다.
# 이후에는 float 타입으로 변환
버릴 데이터를 찾아보자
df['date'] = df.loc[:,'date'].str[:4]
df['date'] = df.loc['date'].astype(float)
display(df.info())
display(df)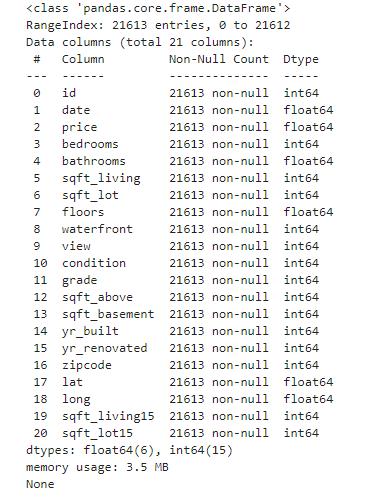

타겟 데이터 분리
target = 'price'
x = df.drop(['sqft_living15', 'sqft_lot15' ,target], axis = 1)
y = df[target]
display(x)
display(x.columns)
display(y)

훈련용 데이터 분리하기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 2023)
데이터 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
x_train = scaler.fit_transform(x_train)
x_val = scaler.transform(x_val)
모델 설계
nfeatures = x_train.shape[1]
from keras.backend import clear_session
clear_session()
from keras.layers import Dense, Dropout
from keras.models import Sequential
model_DNN = Sequential()
model_DNN.add(Dense(18, input_shape = (nfeatures, ), activation = 'relu') )
model_DNN.add(Dropout(0.3) )
model_DNN.add(Dense(4, activation = 'relu'))
model_DNN.add(Dense(1) )
model_DNN.summary()
Param #
출력 노드 * ( 입력노드 + 1 ) = Param
18 * ( 입력차원 + 1 ) = 18 * 19 = 342
4 * ( 입력차원 + 1 ) = 4 * 19 = 76
1 * ( 입력차원 + 1 ) = 1 * 5 = 5
따라서, 342 + 76 + 5 = 423
Total params : 423과 일치한다.
모델 컴파일 및 학습
from keras.optimizers import Adam
model_DNN.compile(optimizer = Adam(learning_rate = 0.01), loss = 'mse')
hist = model_DNN.fit(x_train, y_train, epochs = 50, validation_split = 0.2).history
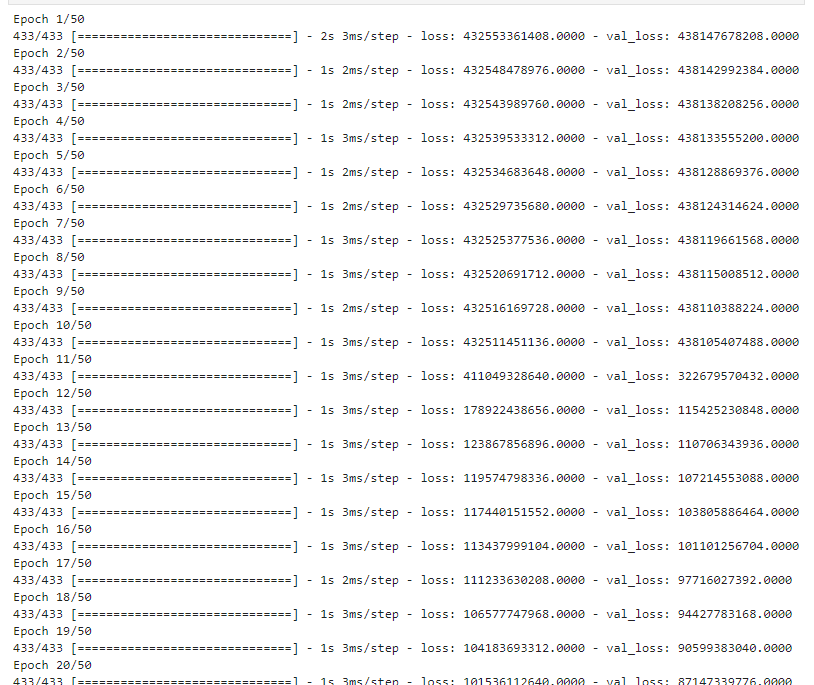
검증
from sklearn.metrics import *
pred = model_DNN.predict(x_val)
print(mean_squared_error(y_val, pred, squared = False) ) # RMSE
print(mean_absolute_error(y_val, pred)