728x90
데이터 전처리 조회, 찾기, 탐색, 확인, 정보]
조회 - 조건 - 컬럼 조건 조회
데이터프레임.loc[ 데이터프레임['컬럼명'] >= 30 ]
조회 - 조건 - 조건 여러 개 세팅
tip.loc[ ( tip['tip'] > 6.0) & (tip['day'] == 'Sat'), :]

조회 - 조건 - 문장에서 구분점을 기준으로 데이터를 분리하여 추출 split()
# 키워드를 추출하고 가장 많이 등장한 상위 10개를 세어줍니다.
keywords = competition_info_df['키워드'].str.split('|').explode()
keyword_counts = keywords.value_counts().head(10)
print(keyowrd_counts)
조회 - 특정 - 문자와 숫자가 함께 있을 때 숫자 부분만 조회
import pandas as pd
# 예시 데이터 생성
data = {'용량': ['100ml', '250ml', '500ml', '1L', '2.5L']}
df = pd.DataFrame(data)
# '용량' 열에서 숫자 부분만 추출
df['숫자'] = df['용량'].str.extract('(\d+\.?\d*)')
df
조회 - 특정 - 컬럼에서 원하는 부분만 슬라이싱
nation_wide['식품중량'].str[0]
조회 - 특정 - 원하는 부분만 추출, "칼럼이름".str[n:n]
import pandas as pd
df = pd.read_csv('train.csv')
df.ID.str[0:6] # 여기에서 ID는 데이터프레임의 컬럼 이름
조회 - 특정 - timedelta에서 원하는 요소만 조회
display(df_competition['진행기간'][0])
df_competition['진행기간'][0].days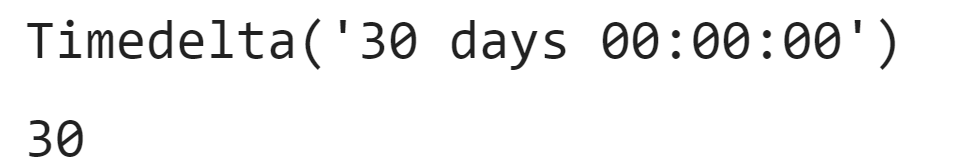
조회 - 특정 - isin() 특정 정보 포함
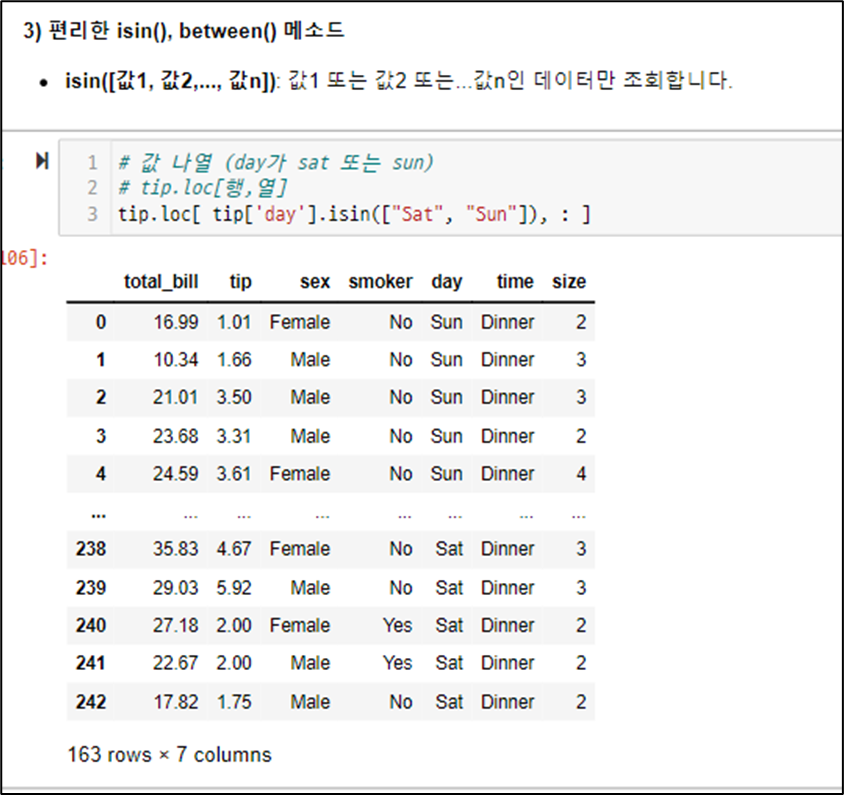
조회 - 특정 - 특정 키워드 포함 str.contains
df_competition.loc[df_competition['키워드'].str.contains("알고리즘"),:]
조회 - 특정 -특정 키워드를 제외한 데이터 탐색 ~df['컬럼명'].str.contains('글자')
seoul_monthly_2023_school = seoul_monthly_2023.loc[seoul_monthly_2023['대여소명'].str.contains('학교') &
~seoul_monthly_2023['대여소명'].str.contains('역') &
~seoul_monthly_2023['대여소명'].str.contains('정류장')]
seoul_monthly_2023_school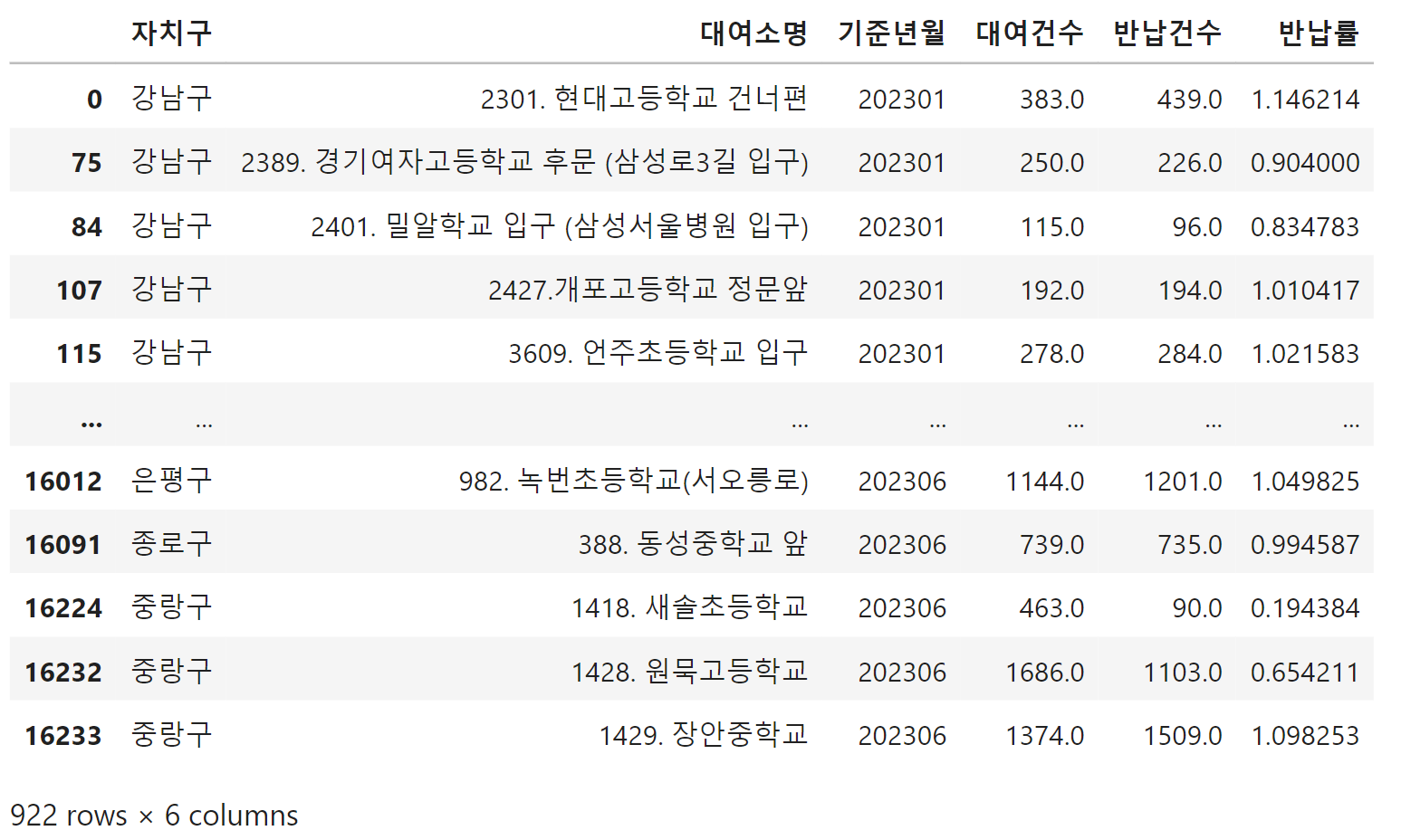
조회 - 특정 - 컬럼에서 "특정 데이터"를 포함하는 행만 출력
# 예시
# 단일 조건
df.loc[ df['cmpSclNm'] =='중소기업']
# 조건 여러 개
df.loc[ ( df['기업명'] == '(주)드림' ) & ( df['accNm'] == '영업이익' ) ]
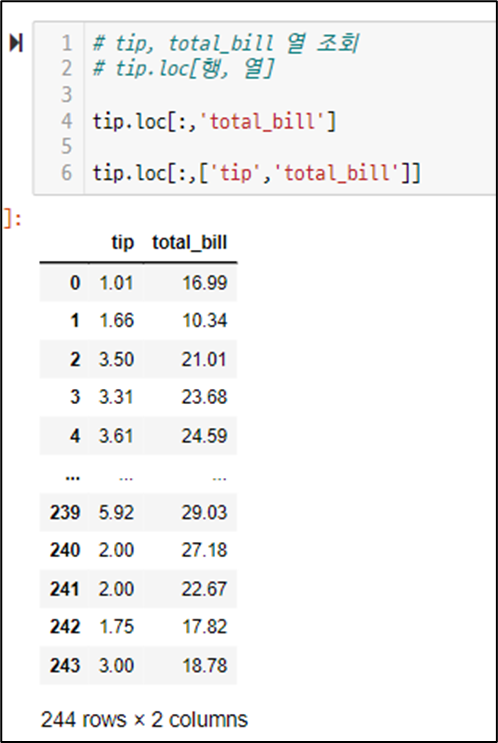
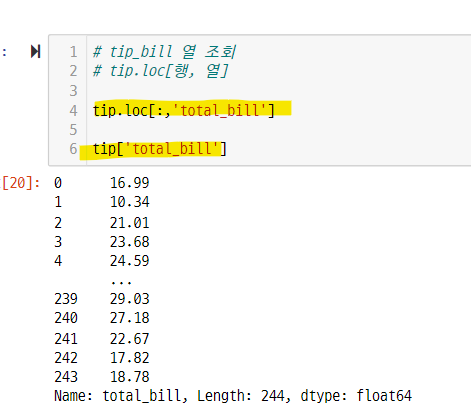
조회 - 특정 - 특정 열 조회
tip.loc[:,'total_bill']

조회 - 특정 - 여러 컬럼 선택 조회
tip.loc[:, ['tip', 'total_bill'] ]
조회 - 특정 - 특정 열 조회 loc 방식 비교
조회 - 일치 - 컬럼명 일치 여부 확인
target_01 = bicycle_20_01
target_06 = bicycle_20_06
feature = [ bicycle_20_01,bicycle_20_02,bicycle_20_03,bicycle_20_04,bicycle_20_05,bicycle_20_06,
bicycle_20_07,bicycle_20_08,bicycle_20_09,bicycle_20_10,bicycle_20_11,bicycle_20_12]
for i in feature:
print(target_01.columns == i.columns)

for i in feature:
print(target_06.columns == i.columns)
조회 - 컬럼의 데이터별 갯수 구하기 value_counts
df['컬럼 이름'].value_counts()
조회 - 형식 - 숫자가 아닌 행 찾기 데이터프레임
[ 데이터프레임['컬럼명'].str.isnumeric() == False ]
조회 - 형식 - 수치형인 컬럼만 추출
numeric_columns = df[ df.dtypes != 'object' ]
조회 - 형식 - 문자형인 컬럼만 추출
string_columns = df[ df.dtypes == 'object' ]조회 - 형식 - 숫자형 데이터, 문자형 데이터 구분
# 데이터 유형을 문자열과 숫자로 구분
is_string = df_competition['상금 정보'].apply(lambda x: isinstance(x, str))
is_numeric = df_competition['상금 정보'].apply(lambda x: isinstance(x, (int, float)))
display(is_string)
print()
# 문자열과 숫자 데이터의 개수 세기
num_strings = is_string.sum()
num_numerics = is_numeric.sum()
print("문자열 데이터 개수:", num_strings)
print("숫자형 데이터 개수:", num_numerics)
정보 확인 - info
# 데이터 기초 정보 확인2
## data 데이터프레임의 컬럼명, 데이터 개수, 타입 정보를 보기 쉽게 출력해 주세요.
## .info 파라미터: verbose=True, null_counts=True
data.info(verbose=True, null_counts=True)
verbose=True: 이 옵션을 사용하면 데이터프레임의 모든 컬럼에 대한 상세한 정보를 출력합니다. 컬럼명, 컬럼의 데이터 타입, 비어 있지 않은 값의 개수(null이 아닌 값의 개수), 메모리 사용량 등이 포함됩니다.
verbose=False: 이 옵션을 사용하면 데이터프레임의 요약 정보만 출력됩니다. 모든 컬럼의 상세한 정보는 출력되지 않으며, 데이터프레임의 크기(행과 열의 개수)와 같은 기본 정보만 표시됩니다.
정보 확인 - 컬럼의 데이터별 갯수 구하기 value_counts
df['컬럼 이름'].value_counts()
정보 확인 - 데이터 비중 확인
data['Activity'].value_counts() / data['Activity'].value_counts().sum()
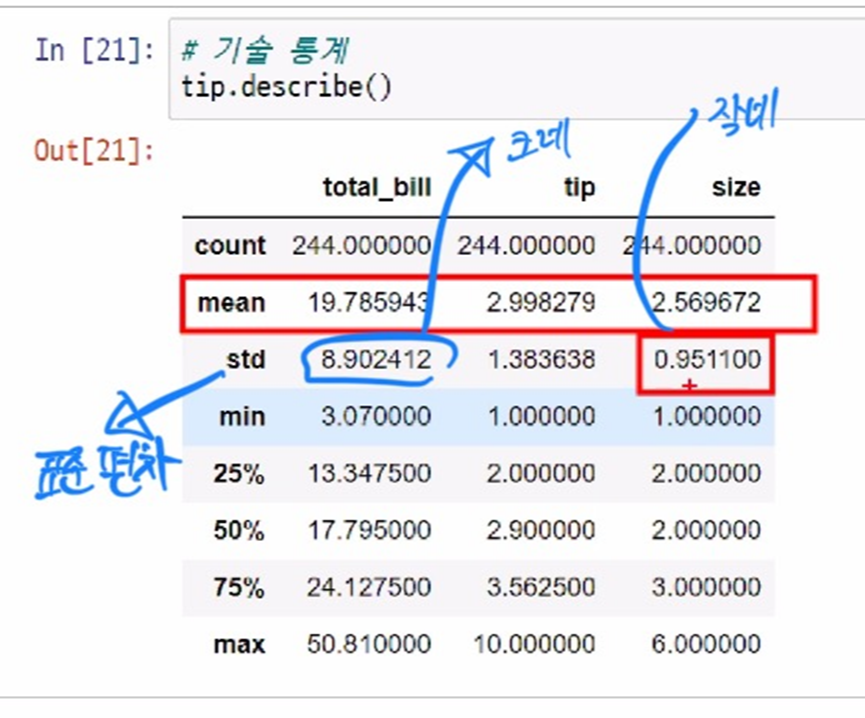
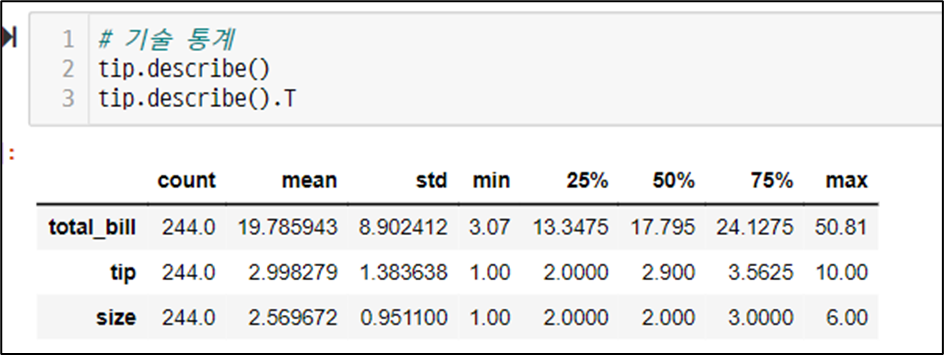
정보 확인 - describe 함수
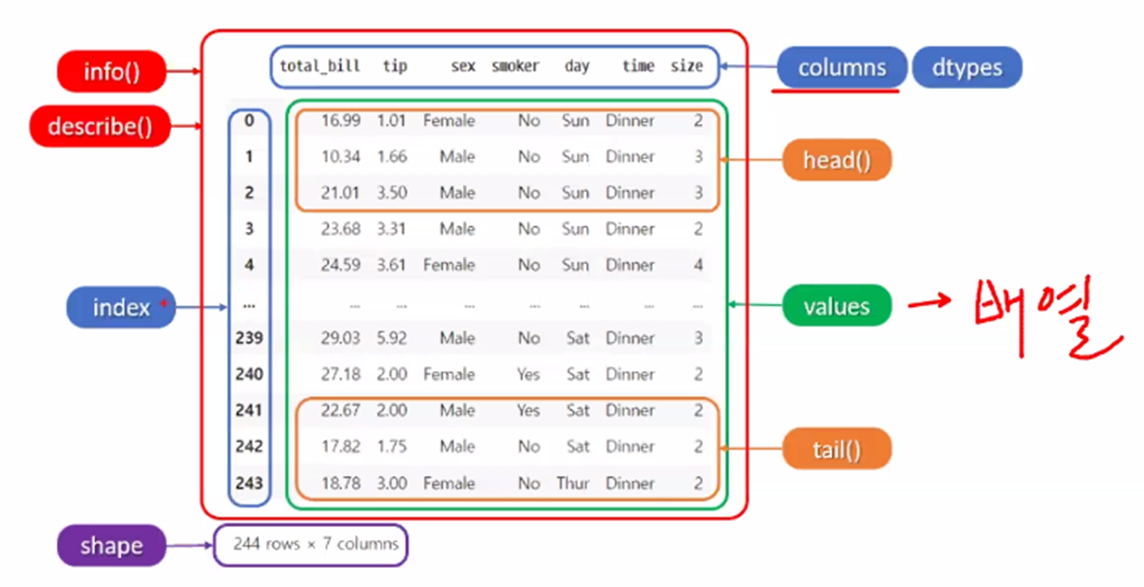
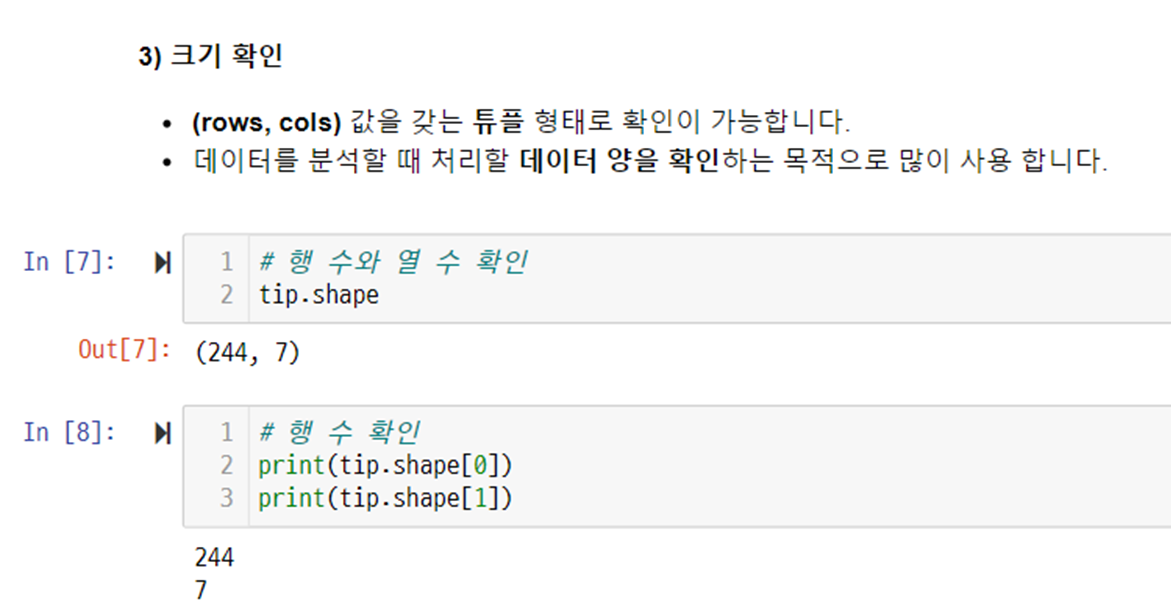
정보 확인 - shape
# 데이터 읽어오기
import pandas as pd
import csv
path = 'https://raw.githubusercontent.com/Jangrae/csv/master/tips.csv'
tip = pd.read_csv(path)
# 확인
tip
# total_bill 열 조회
tip.shape
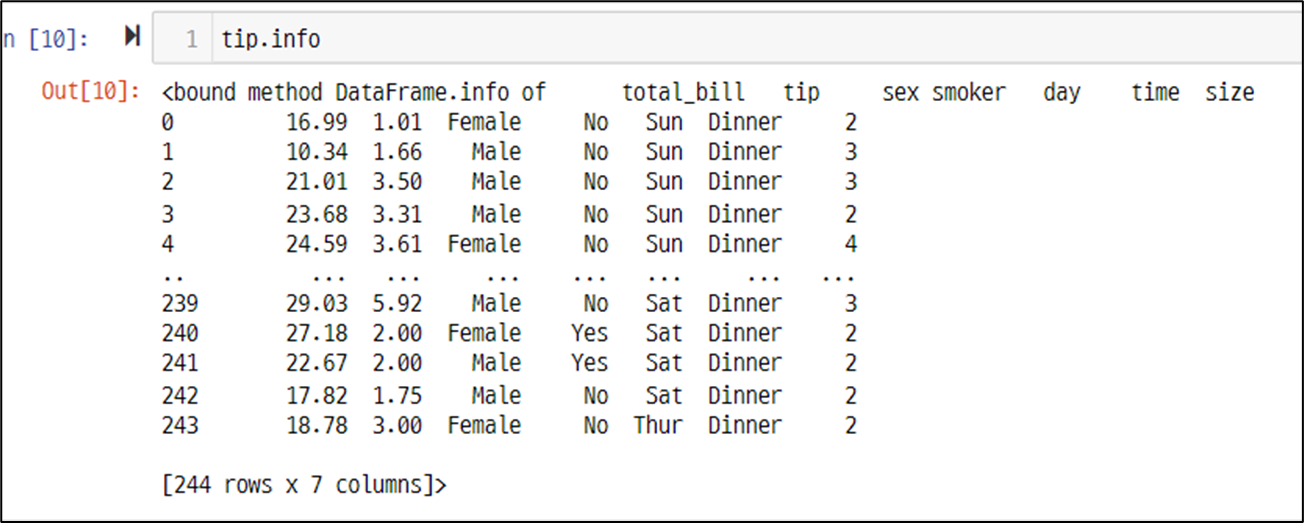
정보 확인 - info 함수
정보 확인 - index
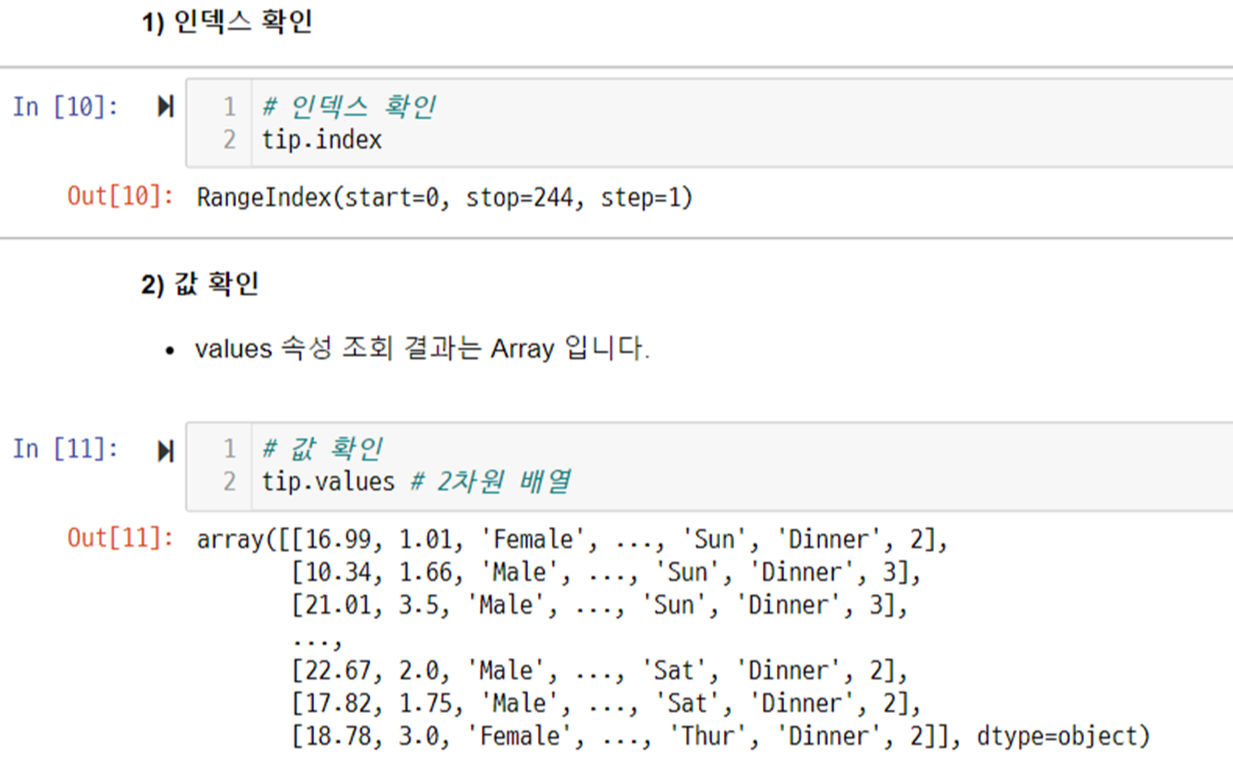
정보 확인 - sort_values()


728x90
'데이터 - 전처리' 카테고리의 다른 글
| 데이터 전처리 구간, 범위] (0) | 2024.01.06 |
|---|---|
| 데이터 전처리 정렬] (0) | 2024.01.06 |
| 데이터 전처리 정보, 형태, 형식, 이름, 변경, 변형] (0) | 2024.01.06 |
| 데이터 전처리 삭제, 제거] (0) | 2024.01.06 |
| 데이터 전처리 결측치] (0) | 2024.01.06 |