728x90
내용
- 먼저 필요 라이브러리들을 불러오자
- 디렉토리에 학습할 파일이 잘 위치하고 있는지 확인하자
- 데이터를 필요한 형태로 가공하자
- 데이터의 정보를 파악하자
- 타겟 데이터에 대해 파악하자
- 데이터를 시각화하여 분석하자
- Random Forest 알고리즘을 사용하여 모델링을 실시하자
- 먼저, 데이터를 학습용과 평가용으로 나누자
- 모델을 선언, 학습, 예측을 수행하자
- 성능을 평가하자
먼저 필요 라이브러리들을 불러오자
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestClassifier # Random Forest 불러오기
from skelarn.model_selection import train_test_split # 데이터를 나누기 위해 불러온다
from sklearn.metrics import * # 모델 성능 평가를 위해 불러온다.
디렉토리에 학습할 파일이 잘 위치하고 있는지 확인하자
import os
os.getcwd() # 현재 디렉토리 위치 확인
os.listdir() # 현재 디렉토리의 폴더와 파일 출력
os.listdir('./data') # 특정 폴더 열어보기
데이터를 읽고, 필요한 형태로 가공하자
data = pd.read_csv('./data/train_data.csv') # data 변수에 train_data.csv 파일을 불러와서 할당한다.
data.drop('subject', axis =1, inplace = True ) # 불필요한 열을 제거하자
데이터의 정보를 파악하자
data.shape() # data 데이터프레임의 행, 열 개수
data.head(5) # 상위 5개 행을 확인
data.tail(3) # 하위 3개 행을 확인
data.columns # 데이터프레임의 컬럼명 확인
data.info() # 데이터프레임의 기초 정보(컬럼명, 데이터 개수, 데이터 타입) 확인
data.info(verbose = True, null_couns = True)
# verbose = True로 하면 모든 열에 대한 정보를 출력, null_counts = True를 하면 각 열에서 null 값의 수를 출력
data.describe() # 데이터프레임의 수치형 데이터 기초통계 정보 확인
타겟 데이터에 대해 파악하자
data['Activity].values # 고유값(범주) 확인
data['Activity].value_counts() # 고유값 별 개수 확인
data['Activity'].value_counts() / data['Activity'].value_counts().sum() # 고유값 비율 = 개별 범주의 수 / 전체 범주의 수
sns.countplot( data=data, x = 'Activity') # seaborn의 countplot을 통해 타겟 데이터를 시각화하여 분석하자
plt.xticks(rotation=90)
plt.grid()
plt.show()
먼저, 데이터를 학습용과 평가용으로 나누자
y = data['Activity']
x = data.drop('Activity', axis = 1) # target으로 사용할 Activity 컬럼을 제거하자
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = 0.3, random_state = 2023)
모델을 선언, 학습, 예측을 수행하자
rf_model = RandomForestClassifier(random_state=2023) # 모델을 선언한다.
rf_model.fit(x_train, y_train) # 모델을 학습한다.
rf_pred = rf_model.predict(x_val) # 예측을 수행한다.
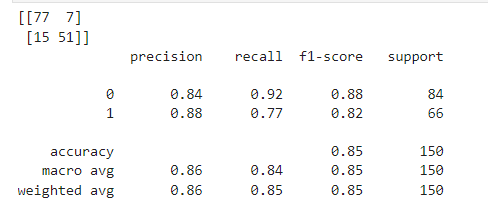
성능을 평가하자
print('accuracy_score', accuracy_score(y_val, rf_pred))
print('\nconfusion_matrix: \n', confusion_matrix(y_val, rf_pred))
print('\nclassification_report: \n', classification_report(y_val, rf_pred))728x90
'Aivle School 4기 > Aivle School 중간점검' 카테고리의 다른 글
| KT Aivle School 에이블스쿨 중간점검] 딥러닝_DNN (0) | 2023.10.31 |
|---|---|
| KT Aivle School 에이블스쿨 중간점검] 데이터전처리, 불필요한 부분 제거, 결측치 대체, 중앙값, 최빈값 (0) | 2023.10.30 |