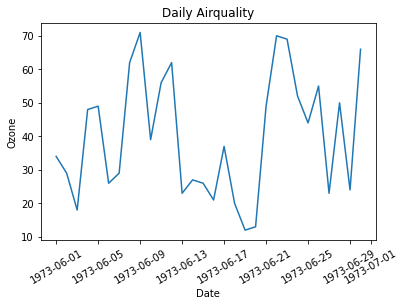
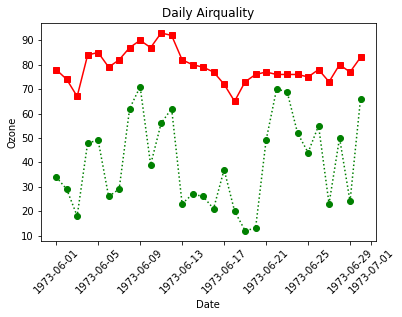
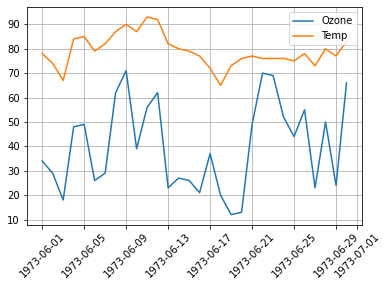
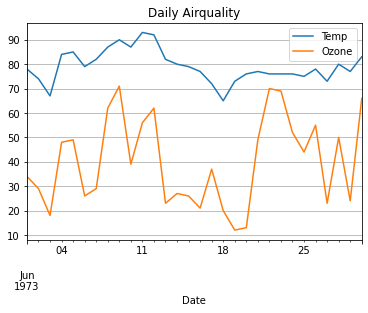
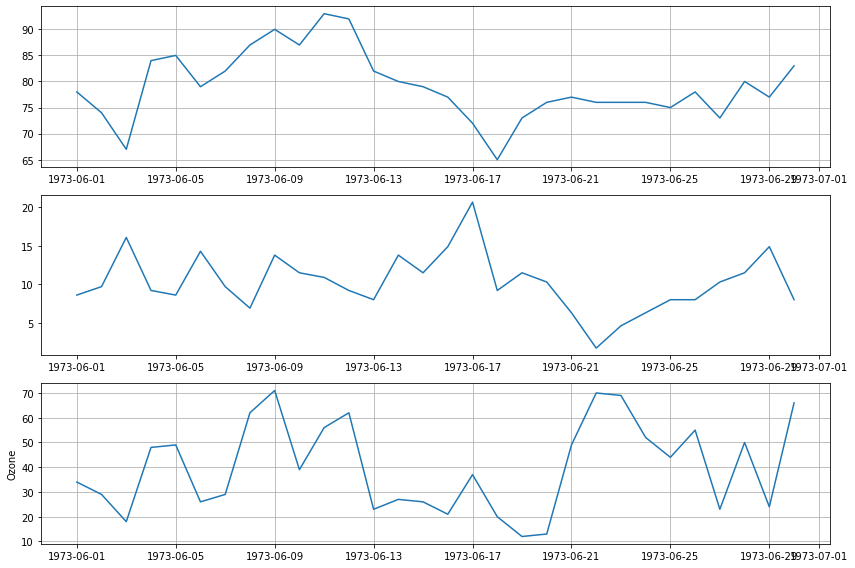
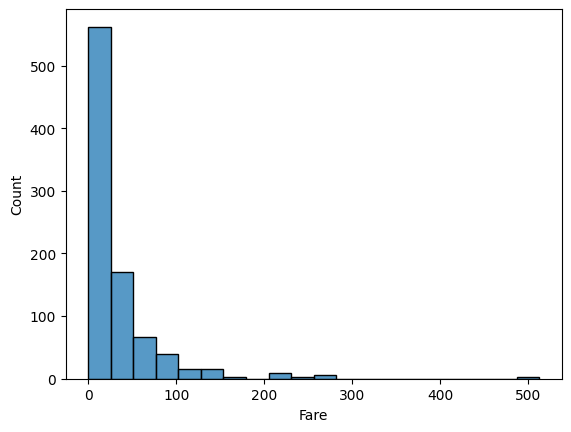
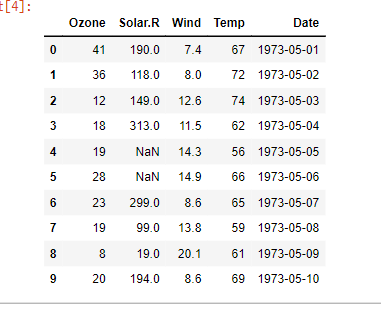
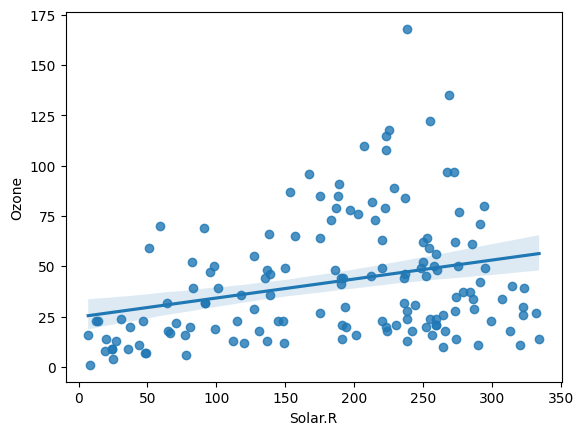
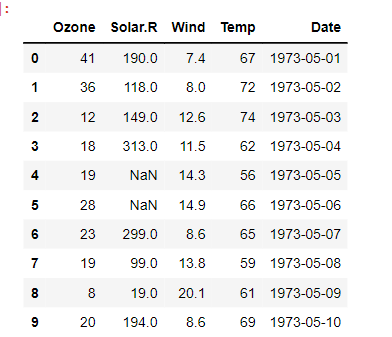
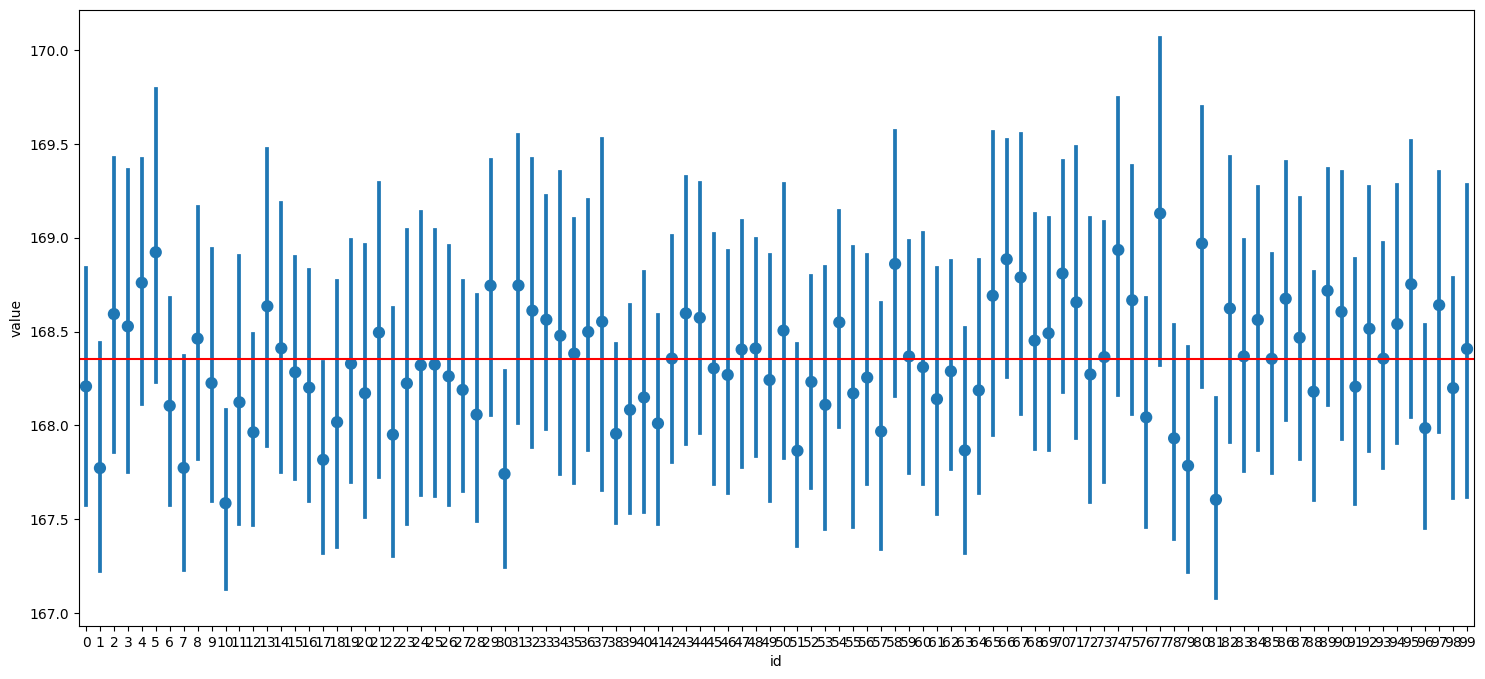
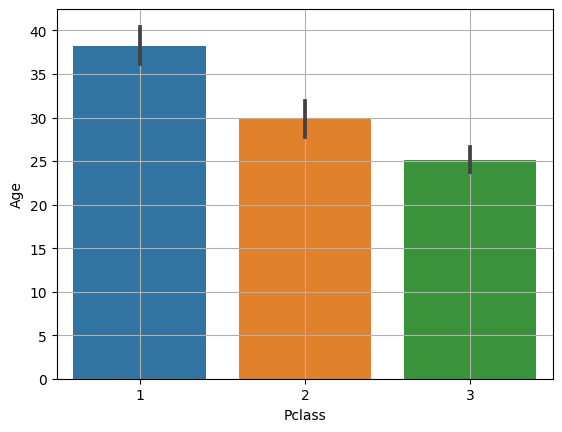
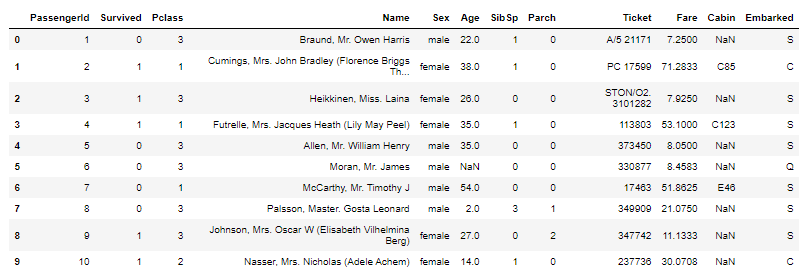
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()
# 모델별 결과 시각화# pandas의 plot 함수을 사용하여 AI모델 별 accuracy_score, f1_score 수직 그래프 시각화 합니다.# grid를 추가해 주세요.# legend를 표시하고, 위치는 center 입니다.import matplotlib.pyplot as plt
result_comp.plot(kind= 'bar')
plt.legend(loc= 'center' )
plt.grid()
plt.show()
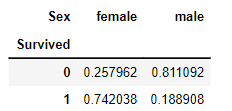
>> 두 개 이상의 범주형 변수 간에 독립성을 검정하는 데 사용한다 따라서, 검정을 통해 변수 간의 연관성을 파악하려면 원본 교차표를 사용해야 한다. Normalize하면 행과 열 합이 1이 되도록 스케일을 조정한다. 범주 간의 상대적 비율을 확인할 때는 유용하지만, 카이제곱 검정의 경우, 범주 간의 독립성을 여부를 확인하는 것이 목적이므로 스케일 조정을 하지 않는다.
카이제곱 검정
귀무가설 : 두 변수 간에 독립성이 있다. p-value가 0.05보다 클 때, 채택 대립가설 : 두 변수 간에 독립성이 없다. p-value가 0.05보다 작을 때, 채택
<주의>
ttest
귀무가설 : 두 집단 간의 평균에 유의미한 차이가 없다. p-value가 0.05보다 클 때, 채택 대립가설 : 두 집단 간의 평균에 유의미한 차이가 있다. p-value가 0.05보다 작을 때, 채택