KT Aivle School 에이블스쿨 기자단] 9.25(월) ~ 10.1(일) 미프, 딥러닝, 코딩 테스트

내용
- 미프 4일차 기억에 남는 부분 : 수치형 데이터를 만들기 위한 노가다...
- 딥러닝 1일차 종합실습_carseat
- 코딩 테스트 메일 도착
미프 4일차 기억에 남는 부분 : 수치형 데이터를 만들기 위한 반복 작업...
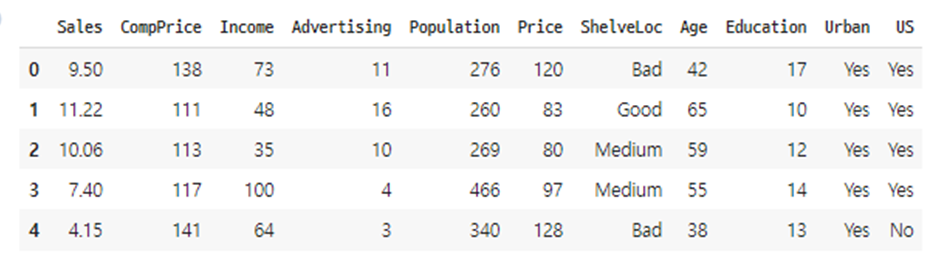
위의 데이터를 보면 수치형 데이터로 나타나지 않은 부분들이 있기 때문에 데이터 분석을 위하여 모두 수치형 데이터로 바꿀 필요가 있었고,
"범주형 데이터" ⇒ "수치형 데이터" 과정은 손가락 아픈 반복 작업이 필요했다
미프가 다 끝나고 완성한 부분을 간추려 보니, 별거 아니라고 느껴지긴 하지만
미프를 진행하는 동안에는 같은 작업을 여러 번 계속 하다보니 손가락이 아프게 느껴져 기억에 남는 부분 중 하나가 되었다.
딥러닝 1일차 종합실습_carseat
딥러닝 회귀 모델을 사용하여 carseat 종합실습을 진행하였다

* model을 생성하기 전에 필수는 아니지만 clear_session()을 하는 것이 권장된다.
코드는
from keras.backend import clear_session
clear_session()
* 모델을 생성할 때는 Sequential 모델을 사용하고, Dense 레이어를 이용
히든 레이어에는 relu를 activation으로 사용
from keras.models import Sequential
from keras.layers import Dense
model = Sequential([Dense(18 ,input_shape = (nfeatures,) , activation = 'relu' ),
Dense(4, activation='relu') ,
Dense(1) ] )
코딩 테스트 메일 도착

아직 코딩 실력이 부족하다고 느끼지만, 어차피 실전을 겪고 깨져봐야 실력이 늘거라 생각해서 시험을 신청했다
