728x90
분류 - LogisticRegression
1. 라이브러리 불러오기
import pandas as
impot numpy as np
import maplotlib.pyplot as plt
import seaborn as sns
2. 데이터 불러오기
data = pd.read_csv('데이터.csv')
3. 학습용 평가용 데이터
from sklearn.model_selectoin import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state=2023)
4. 모델링
# 1단계 : 불러오기
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confision_matrix, classification_report
# 2단계: 선언하기
model = LogisticRegression()
# 3단계 : 학습하기
model.fit(x_train, y_train)

# 4단계 : 예측하기
y_pred = model.predict(x_test)
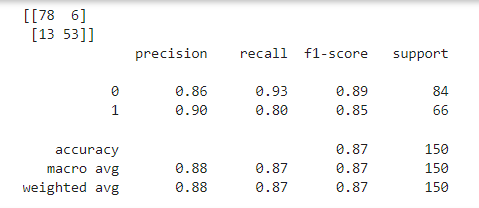
# 5단계 평가하기
print(confusion_maxtrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
필기
필기 2
728x90
'데이터 - 머신러닝 지도 학습' 카테고리의 다른 글
| 지도 학습] 회귀 KNeighborsRegression (0) | 2023.09.23 |
|---|---|
| 지도 학습] XGBClassifier (0) | 2023.09.21 |
| 지도 학습] 모델 저장 (0) | 2023.09.21 |
| 지도 학습] 분류 - RandomForestClassifier 랜덤 포레스트 (0) | 2023.09.20 |
| 지도 학습] 분류 - 결정트리 DecisionTreeClassifier (0) | 2023.09.20 |