KT 에이블스쿨 5기 모집
https://aivle.kt.co.kr/home/main/indexMain
KT 에이블스쿨
KT가 직접 설계, 교육, 코칭, 채용
aivle.kt.co.kr

모집일정
지원자격
우대사항에 있는 AICE 자격증이란?
AICE 자격증은 KT 개발하고 한국 경제와 함께 주관하는 인공지능 능력시험입니다.
현재, AICE 자격증 없더라도 AIVLE School에서 교육을 받으신다면, ASSOCIATE 자격 응시 기회를 주고, 불합격 시에는 1회 재시험 기회 또한 부여하고 있습니다.
AICE
KT가 개발하여 한국경제신문과 함께 주관하는 인공지능 능력시험입니다.
aice.study
혜택
ㆍ KDT 교육비 최대 31.6만원 지급
: 결석 없이 교육에 성실히 참여하실 경우 최대 31.6만원의 지원금을 받으며 공부하실 수 있습니다.
교육비가 무료인데 추가로 지원금도 받을 수 있으니 좋은 기회라고 생각했어요.
현재까지 후기
ㆍ AIVLE School에 참여하면서 좋았던 점 중에서 하나는 스터디원들을 구하기 쉽다는 것입니다.
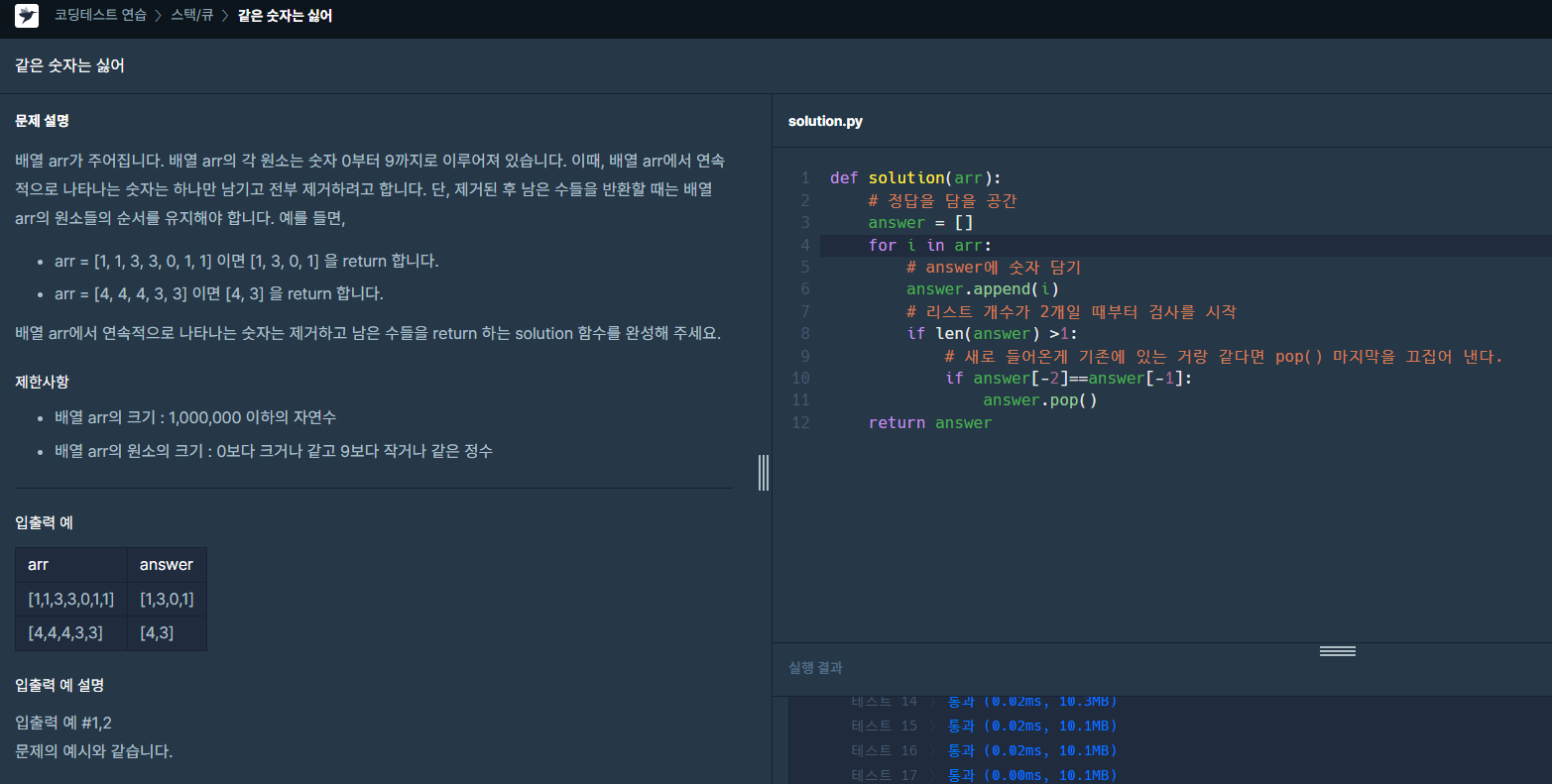
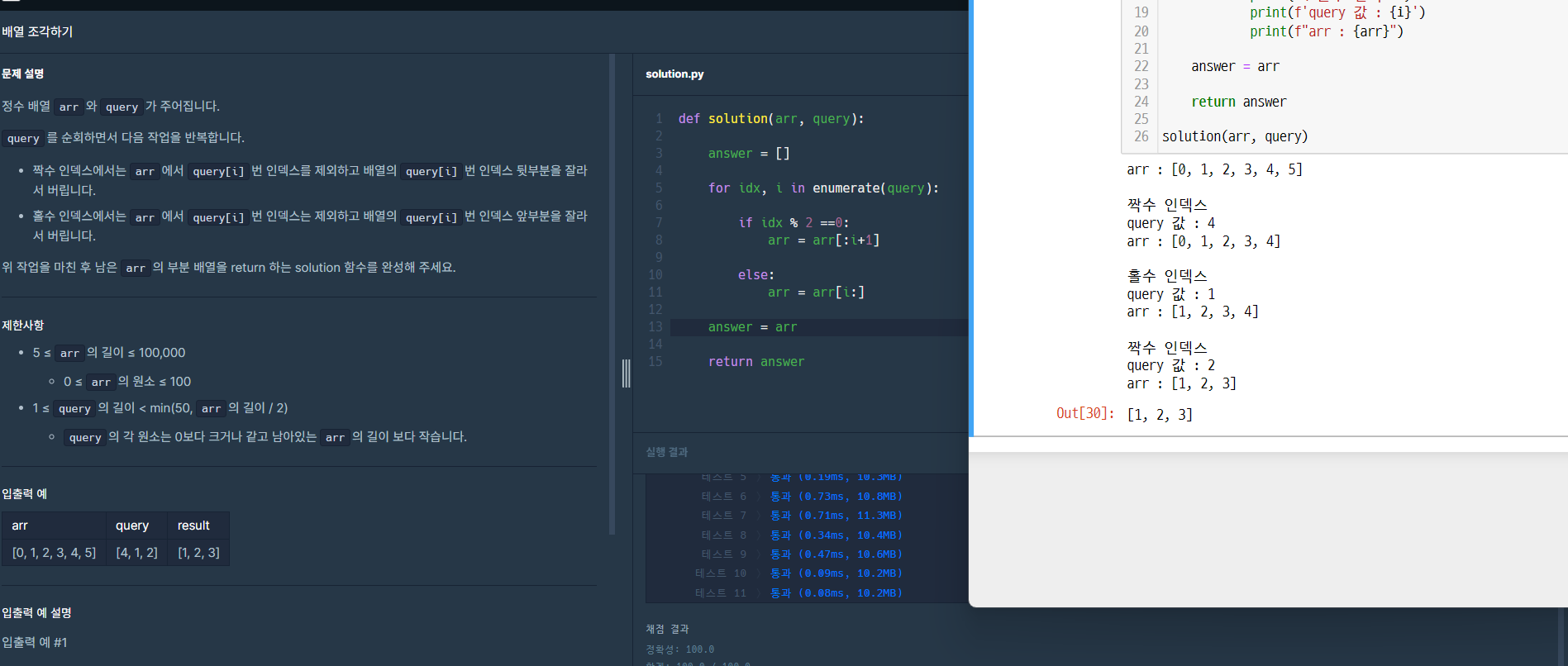
저는 개인적으로 "백준 문제풀이", "SQL 프로그래머스 문제풀이" 스터디장을 맡아서 매주 스터디를 진행하고 있습니다.
에이블스쿨이라는 기회가 없었다면, 이렇게 좋은 스터디원들을 만나기 힘들었을 거라고 생각하고 있어요.
ㆍ 또한, 공모전에 나가고 싶을 때도 사람들을 모집하기 쉽다는 점 또한 있습니다.
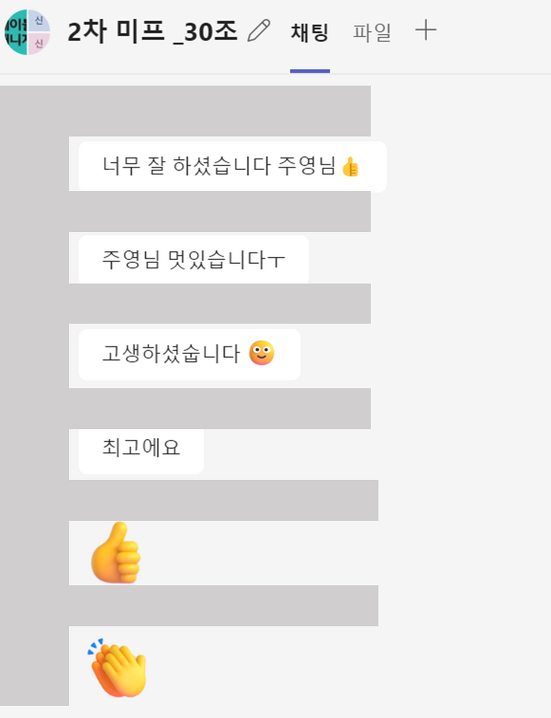
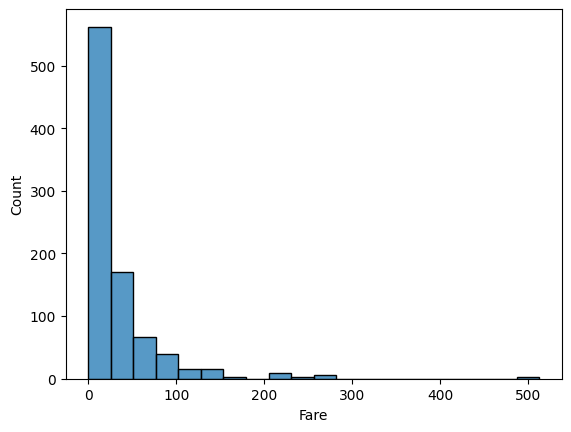
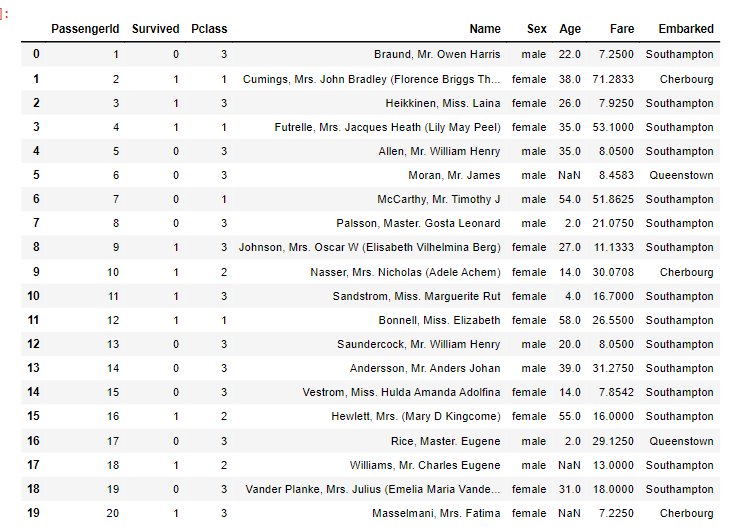
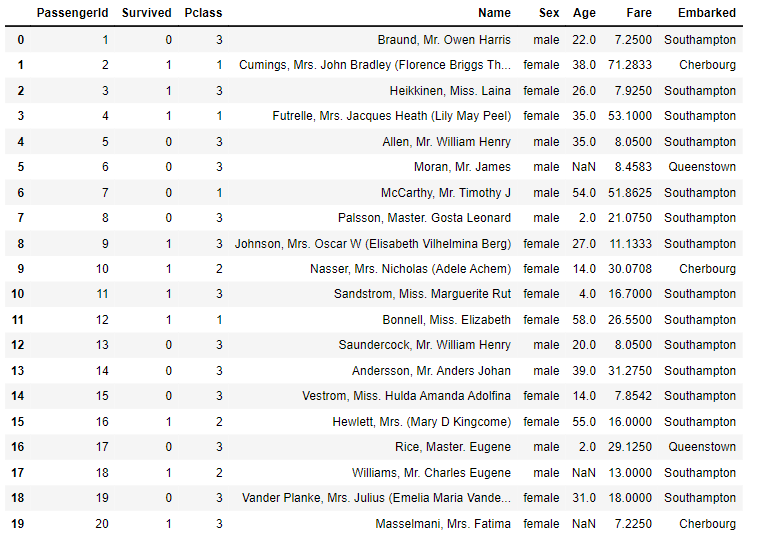
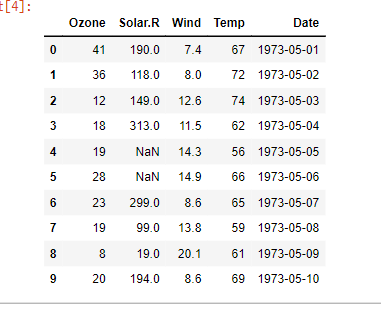
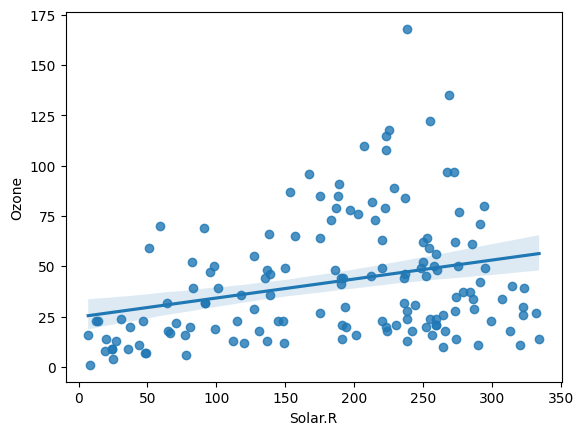
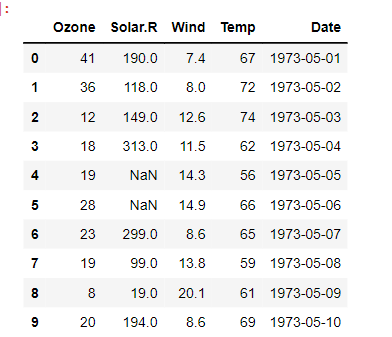
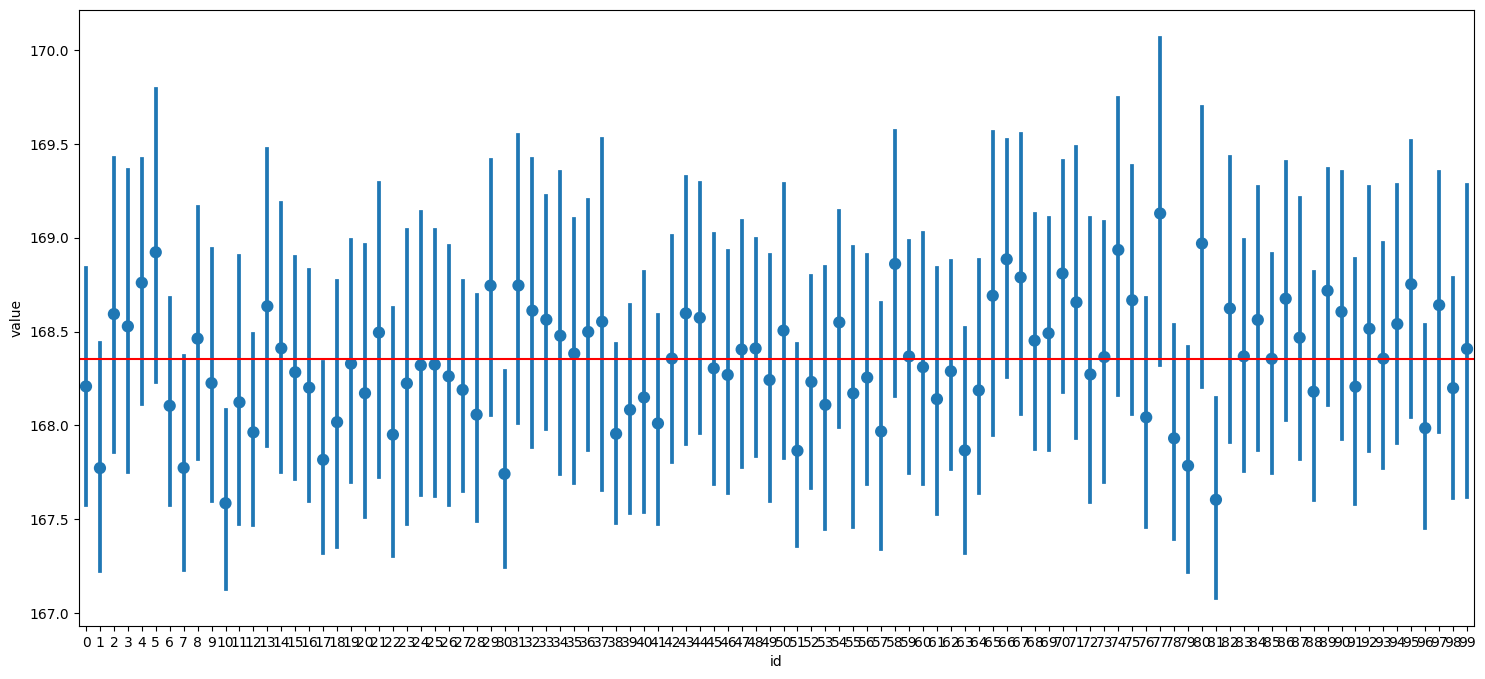
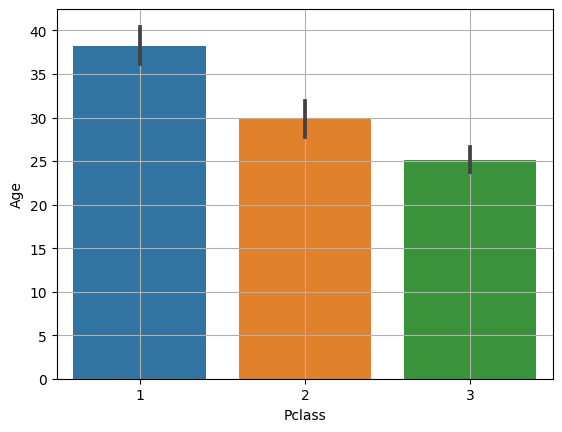
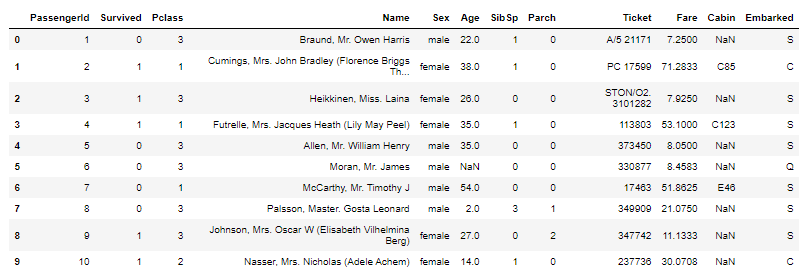
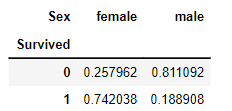
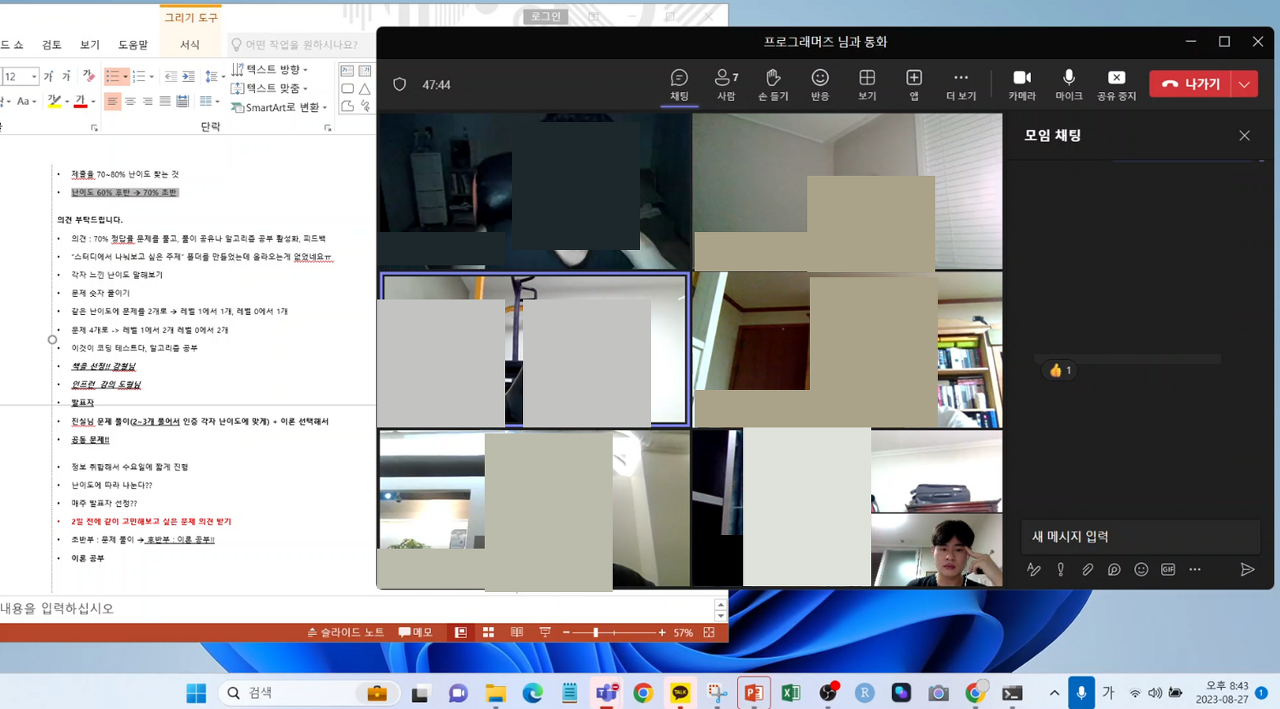
위 사진은 공모전 회의를 할 때 모습입니다. Teams를 통해 자료들을 간편하게 주고 받으니 공모전을 원활하게 할 수 있었어요. 에이블스쿨에서 처음으로 진행했던 공모전이라 기억에 많이 남네요. 이때, 에이블스쿨 수업 중 "데이터 다루기", "데이터 다듬기"에서 배운 내용을 많이 활용하였고 실력을 키울 수 있는 좋은 기회였습니다.
친구 추천 이벤트


지금 Aivle School 5기 친구 추천 이벤트에 참여하시면 커피 쿠폰도 나눠드리고 있으니 참고해주세요!!