import csv
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
for row in data:
print(row)
카테고리 확인
import csv
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
for row in data:
a=0
print(f"* 첫째 행 구성요소 : {row}")
print(f"* 행 길이 : {len(row)}")
for i in row:
print(f"{a}번째 값 : {i}")
a+=1
break
Pandas를 활용하여 간단하게
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
cp949 : 한글 표현하기 위함
index_col = 0 : 불필요한 인덱스 제거 역할
index_col = 0 입력
index_col 생략
원하는 정보(초, 중, 고 중에서 선택)만 골라서 출력
df.index.str.contains() 함수를 통해 데이터 프레임의 인덱스 문자열에 원하는 문자열이 포함된 행을 찾기
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
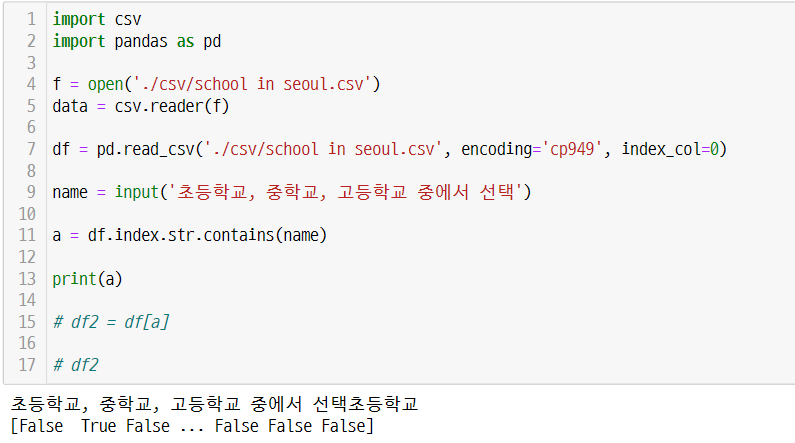
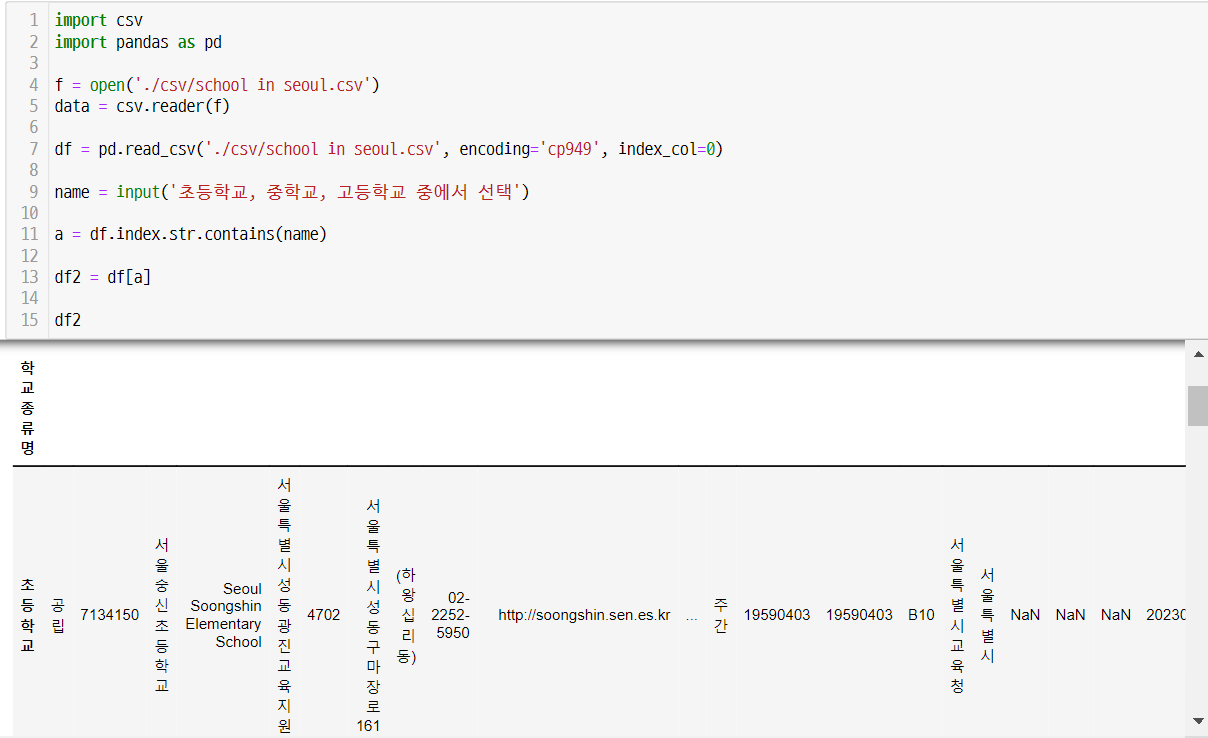
name = input('초등학교, 중학교, 고등학교 중에서 선택')
a = df.index.str.contains(name)
df2 = df[a]
df2
df.index.str.contains(name)에는 True, False 값이 배열 형태로 저장
"초등학교" 입력 결과
초, 중, 고 갯수 확인
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df_cho = df[df.index.str.contains("초등학교")]
df_jung = df[df.index.str.contains("중학교")]
df_go = df[df.index.str.contains("고등학교")]
print(f"전체 학교 수 : {df.shape[0]}")
print(f"초등학교 수 : {df_cho.shape[0]}")
print(f"중학교 수 : {df_jung.shape[0]}")
print(f"고등학교 수 : {df_go.shape[0]}")
행 개수, 열 개수 확인
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
df
print(f"행 개수 : {df.shape[0]} 열 개수 : {df.shape[1]}")
학교 종류 확인(리스트 타입)
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
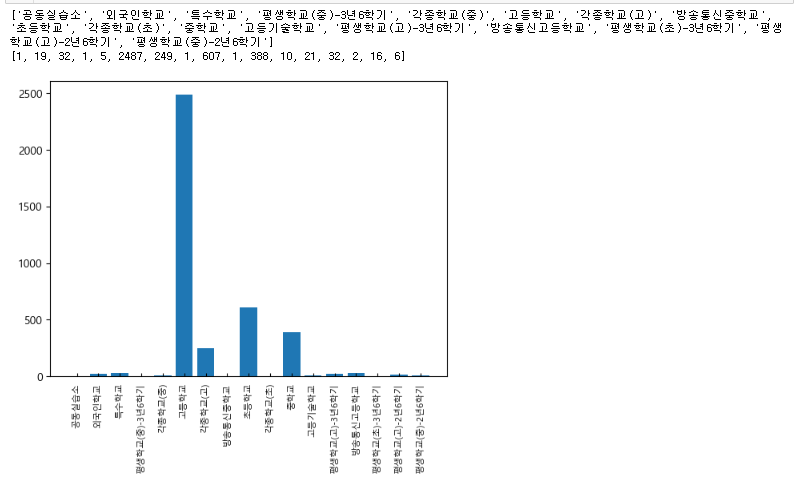
index_info = list(set(df.index.to_list()))
print(index_info)
학교 종류별 갯수
import csv
import pandas as pd
f = open('./csv/school in seoul.csv')
data = csv.reader(f)
df = pd.read_csv('./csv/school in seoul.csv', encoding='cp949', index_col=0)
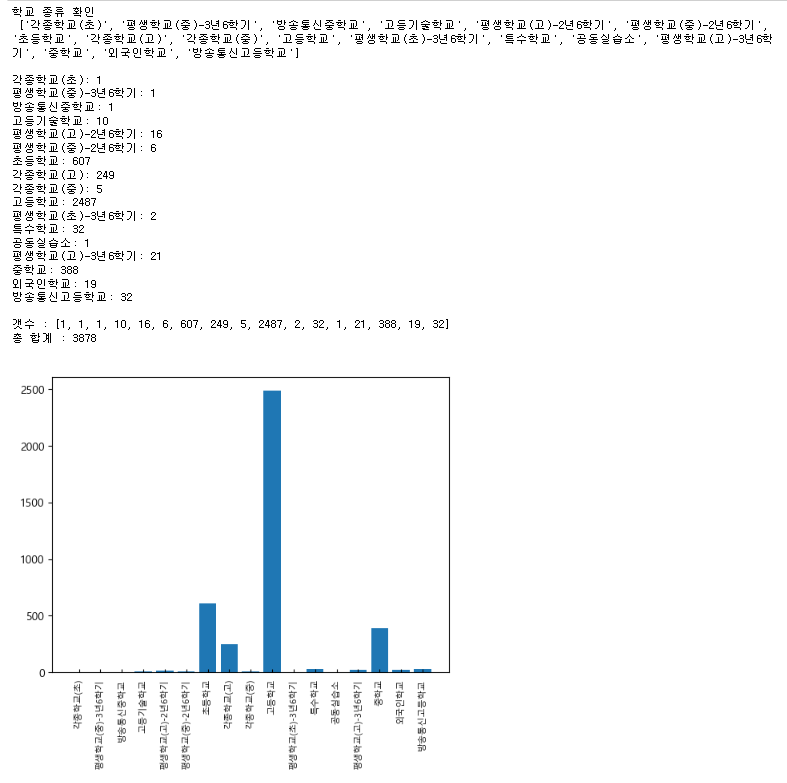
index_info = list(set(df.index.to_list()))
print(f" index_info {index_info}\n\n")
a=[]
for i in index_info:
# 정확한 일치 개수를 세는 방식으로 변경
count = (df.index==i).sum()
print(f"{i}: {count}")
a.append(count)
print('\n\n',a,'\n\n')
print(sum(a),'\n\n')