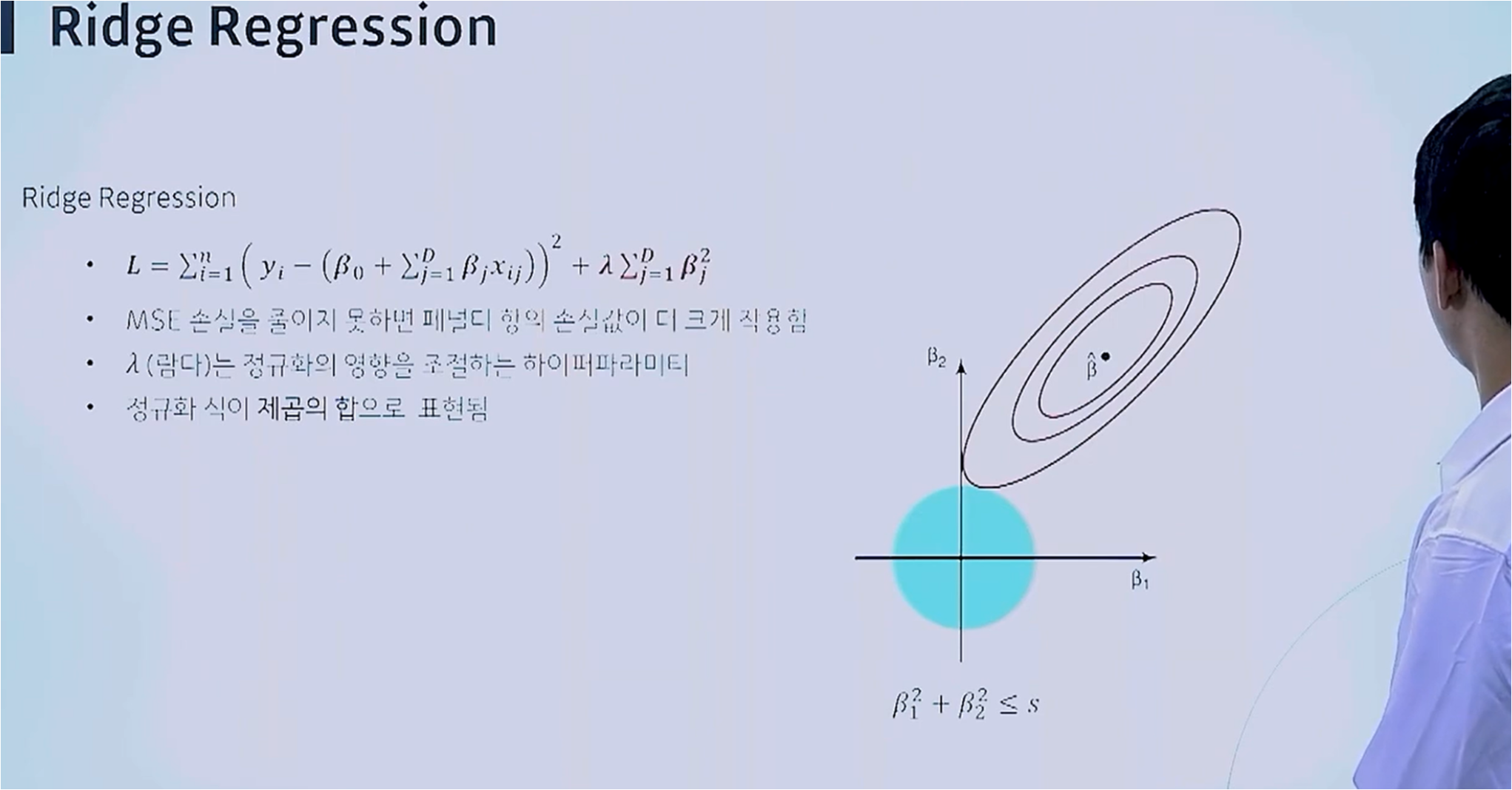
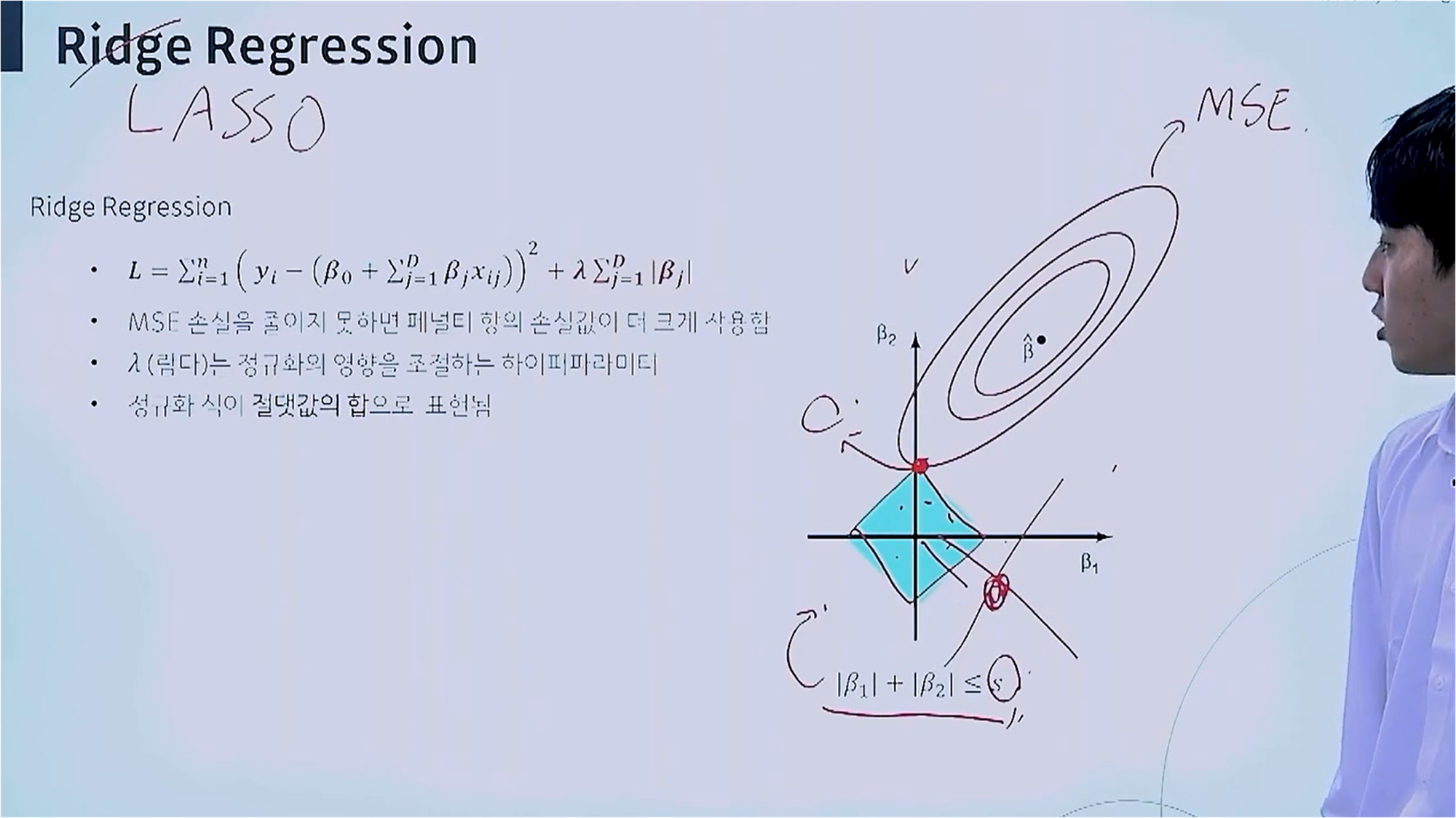
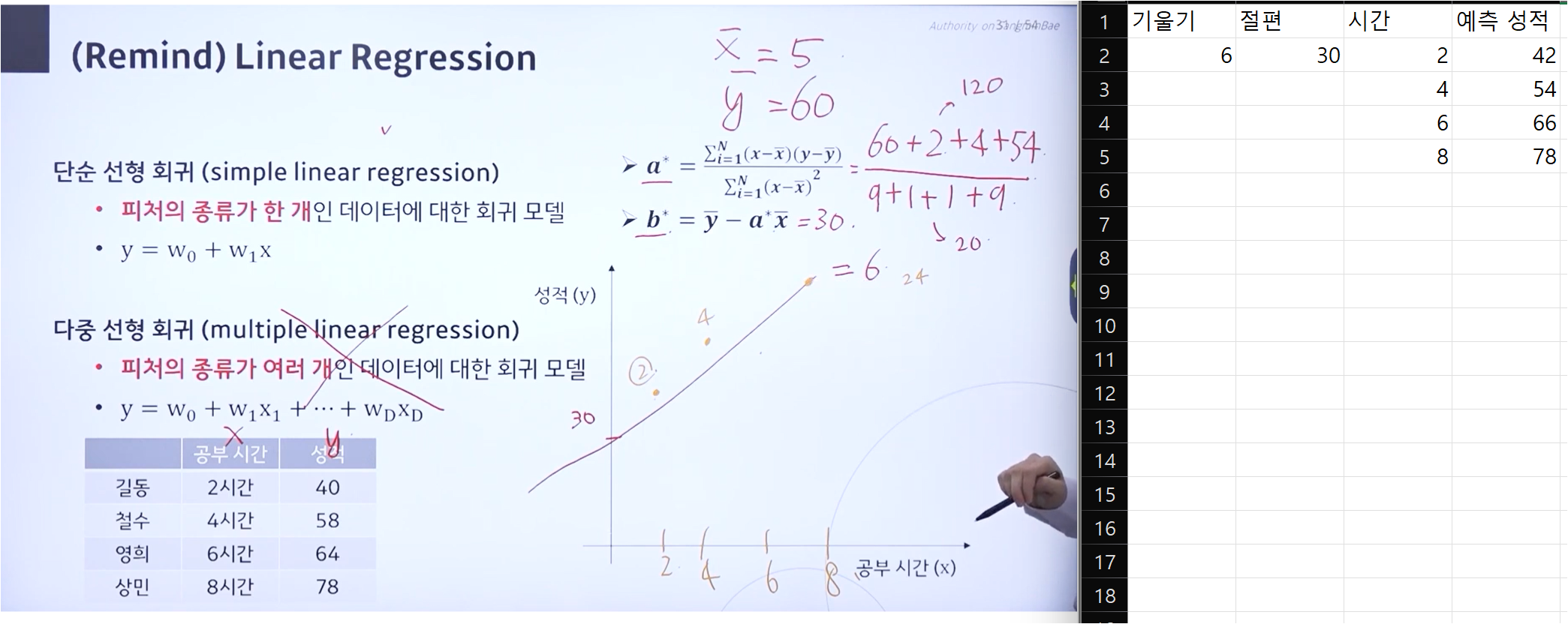
[메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "1단원 실습"
머신러닝 입문 부트캠프ㅣKAIST AI 박사과정
www.metacodes.co.kr
안녕하세요 메타코드 서포터즈 5기 송주영입니다.
드디어 1단원 이론 수업을 마치고, 코딩 실습을 하게 되었습니다.
실습을 하면서 이론 때 배워둔 내용을 더 확실하게! 이해하는 게 목표에요
인공지능 혹은 코딩 관련 분야에 관심을 갖고 계신다면 "이론 공부 and 코딩 실습" 루틴으로 공부를 하는 게 좋을 거 같아요
강의 리뷰 시작하겠습니다.
실습 환경 - Colab

코딩 실습은 Colab 환경에서 진행되었습니다.
Colab은 구글에서 제공하는 온라인 코딩 환경입니다.
Python 언어를 Jupyter 환경에서 제공하여 마크다운 셀을 통해 편리하게 필기할 수 있다는 장점을 갖습니다.
다만, 세션 유지 시간이 정해져 있어서 이 부분을 염두에 둘 필요가 존재합니다.
드라이브 연결
구글 드라이브와 Colab을 연결하는 코드입니다.
해당 코드를 입력하면 연결을 할 것인지 묻는 창이 나오며 동의를 클릭하면 연결이 완료됩니다.
ls 명령어를 통해 현재 디렉토리의 파일을 확인할 수 있습니다.
cd 명령어를 통해 디렉토리의 위치를 변경할 수 있습니다.
학습 데이터와 평가 데이터로 나누기
sklearn을 통하여 데이터를 학습용과 평가용으로 나누었습니다.
test_size를 통해 학습용과 평가용의 비중을 어떻게 할 지 설정합니다. 이 경우에는 90:10 비율로 설정했습니다.
random_state를 통해서는 seed 값을 고정하여 항상 동일한 데이터가 추출되도록 합니다.
나눈 데이터는 X_train, X_test, y_train, y_test 변수에 할당됩니다.
경사하강법
경사 하강법을 활용하여 학습을 진행하는 모습입니다.
loss 변수에 MSE 손실함수 식을 할당했고, numpy의 mean 함수를 활용했습니다.
Gradient 계산을 위한 편미분 값도 dw, db 변수에 할당했고, 아래 줄에서는 w와 b 변수가 업데이트가 됩니다.
lr은 learning_rate입니다.
weights와 bias 값은 리스트에 append 되고 최종적으로는 w, b, w_list, b_list, loss_list의 5개의 변수가 반환됩니다.
LinearRegression 모델 활용, 최소 제곱법(Least Squares Method)
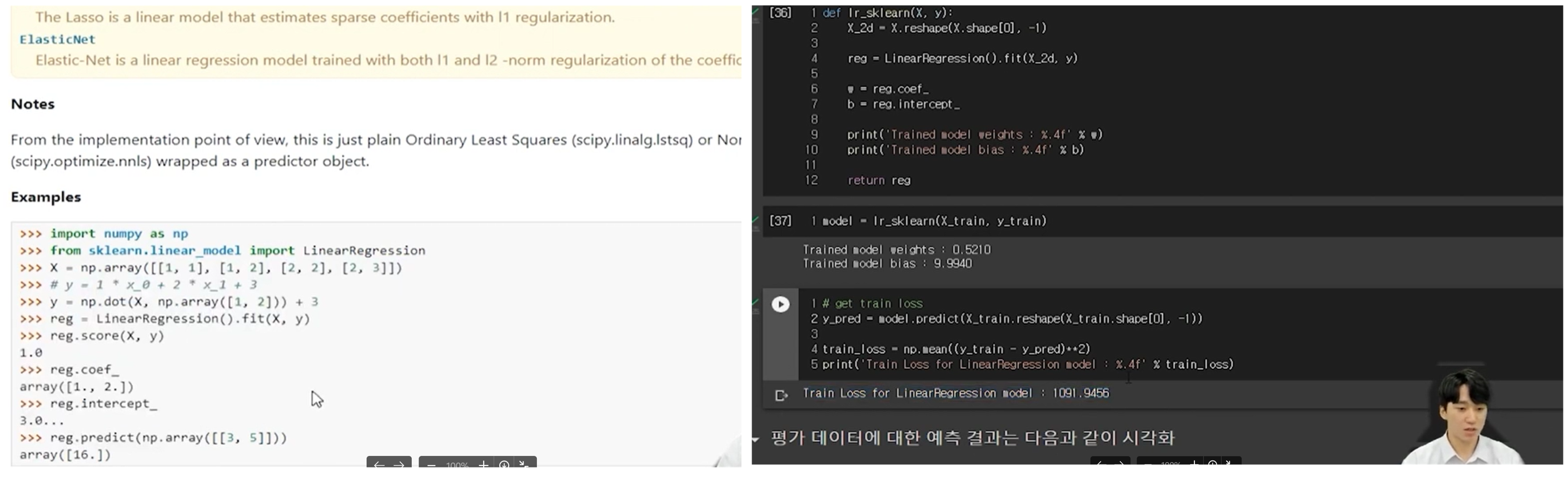
sklearn 라이브러리의 LinearRegression 모델을 활용하여 모델을 학습하는 코드입니다.
해당 모듈은 경사하강법 대신에 최소 제곱법을 사용해 모델을 학습합니다.
reshape 메서드를 통해 데이터를 알맞은 형태로 변형하였습니다.
y_pred에 예측값을 저장하고, 이를 통해 train_loss 값을 계산했습니다.
predict() 메서드는 x를 통해 예측을 수행하는 것으로, x 인자만 필요하고 y 인자는 필요로 하지 않습니다.
SGDRegressor
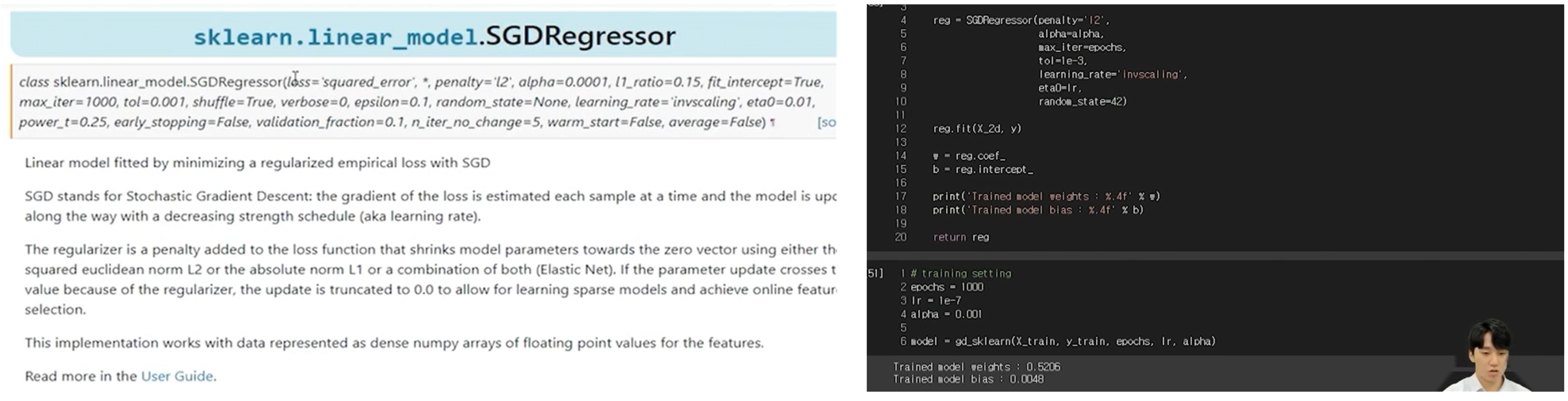
마지막으로 SGDRegressor를 통한 모델 학습입니다.
tol 값을 설정하면 loss 값이 특정 값에 도달하였을 때 학습이 중단되게 할 수 있습니다.
경사하강법, LinearRegerssion, SGDRegressor를 통해 모델을 학습하는 방법을 배웠습니다.
train_loss = np.mean((y_train-y_pred)**2)코드를 통하여 MSE 값을 비교하며 어떤 모델이 가장 학습이 잘 되는지 확인할 수 있습니다.
확인 결과는 LinearRegression을 통해 최소제곱법을 사용했을 때가 가장 높은 성능을 보였습니다.
'인공지능 - 메타코드' 카테고리의 다른 글
| [메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "Logistic Regression" (0) | 2024.07.30 |
|---|---|
| [메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "Validation Data" (0) | 2024.07.27 |
| [메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "Bias and variance Trade-off" (0) | 2024.07.21 |
| [메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "Gradient Descent" (3) | 2024.07.20 |
| [메타코드 강의 후기] 메타코드 머신러닝 입문 부트캠프 - "기초수학 ~ 최소제곱법" (3) | 2024.07.14 |