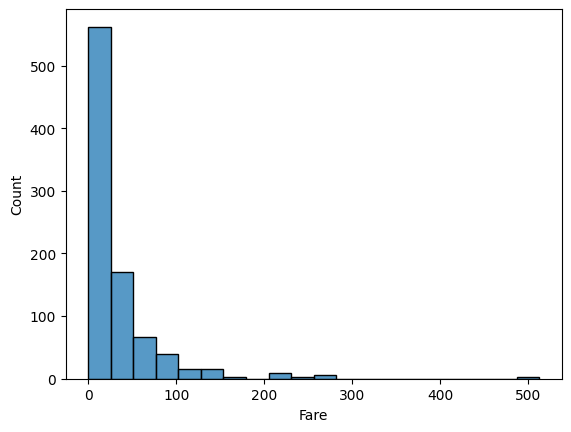
KT Aivle School 에이블스쿨 기자단] 9.11(월) ~ 9.17(일) 해커톤 회의, 코딩 마스터즈 마감, 그 와중에 예비군 작성
이번 주의 스케줄
월~금 KT 에이블스쿨 머신러닝 수업
금요일 코딩마스터즈 마감
토요일 예비군(인천 서구동구 예비군 훈련장)
일요일 5시 해커톤 회의
일요일 8시 프로그래머스 스터디(내가 주관!)
일요일 책 하나 읽을 예정이었으나 예비군, 해커톤, 프로그래머스 스터디 3연타로 포기....
이장래 강사님 마지막 수업
회귀와 분류
공모전 빅콘 --> DBI 2023
코멘토
코딩 마스터즈 최종 성적
아직 난 하찮은 실력임을 다시 확인할 수 있었다
이번 주는 공모전 준비와 토요일 예비군으로 바빴지만 에이블러라면 이거를 핑계로 삼지는 말자!
이장래 강사님과의 마지막 수업ㅠ
파이썬 기초 문법으로 뵈었던게 얼마 안된 거 같은데 머신러닝 지도학습 수업을 마지막으로 이제 에이블스쿨 교육에서는 뵐 일이 없어졌다ㅠ 나는 인프런 강의에서 또 뵙겠지만 아쉬운건 어쩔 수 없는 거 같다
해커톤 일요일 회의
이번 해커톤 회의에서 개인적으로 기뻤던 부분은 내 아이디어가 매우 긍정적인 평가를 받았던 것이다
나의 해커톤 아이디어
난이도 문제로 살짝의 수정이 필요하지만 develop하는 과정 또한 흥미로울 거라 생각한다 DX 참여자로서 기획, 데이터 부분에서 밥값을 해야한다고 느끼고 있는데 일단 첫 단추는 잘 끼운 듯 아이디어에 대한 자세한 설명은 해커톤이 어느 정도 진행되면 첨부할게요~
공모전 변경
처음 함께 서울 공공 데이터 활용 공모전에 나갔던 에이블러들과 새로운 공모전을 탐색 중이다. 나는 다시 조장 역할을 수행 예정이다
기존에 생각했던 빅콘테스트
처음에는 이 공모전을 선정했으나 시간 관리 문제로 서류 작성 시간이 모자라져서 아래 공모전으로 변경했다
최종 결정한 DBI2023 공모전
도메인 지식을 늘리는 데 도움이 될 거 같긴 하지만 아래의 데이터들이 내가 분석해야 할 데이터 목록들... 나 할 수 있겠지...?? 10,000개의 기업들을 분석해야 한다. 결측치들은 또 어떻게 처리해야 될라나
공모전 제공 데이터 총 10,000개의 기업 분석
내용정리
# 선언하기
model = LogisticRegression()
# 학습하기
model.fit(x_train, y_train)
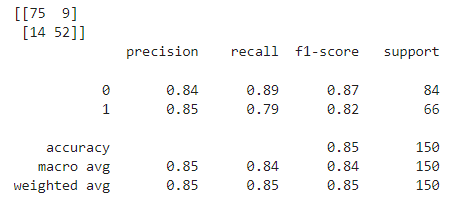
# 평가하기
print(confusion_maxtrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
학습 완료 시, 출력 결과평가 실행 시, 출력 결과
# KNN에서 스케일링을 수행하는 이유 검색
언제나 고마운 GPT
# 수업 필기
수업시간 필기
이번주 프로그래머스
이번 프로그래머스 스터디를 진행하며 당황스러웠던 점은 하는 중간에 프로그래머스 팀즈 채널이 삭제된 것이었다! 팀원들에게 자유롭게 팀즈 공간을 꾸밀 수 있도록 모두 소유자 권한을 주었는데 아마 한 분이 실수한거 아닐까 싶다 이번 사태 이후로는 소유자 권한은 현재 리더를 맡고 있은 나만 가질 계획
KT Aivle School 에이블스쿨 기자단] 9.04(월) ~ 9.10(일) 시즌 1호 발표 & ADsP 합격
이번 주의 스케줄
미니 프로젝트
ADsP 발표
데이터 수집 -> 웹 크롤링을 잘 활용하면 쏠쏠하게 아르바이트를 할 수 있다고 해서 좀 더 흥미가 갔다 “크몽” 사이트는 메모
데이터 분석
이번 셀프 테스트 잘 본건가.. 알쏭달쏭
데이터 분석 삽질 ㅠ
2차 미니프로젝트 1일차
시즌 1호 발표 완료~
저번 1차 미니 프로젝트에서는 스스로에게 만족스럽지 못해서 열심히 준비한 결과,
발표를 하고 칭찬을 받을 수 있었다
코딩 파일 시작 부분에 뚜렷한 목적성을 잘 나타낸게 어필한 포인트
시즌 1호 발표 완료!! 칭찬 받은 시작 부분 9.06(수)
첫 발표라 그런지 우쭈쭈해주는 고마운 팀원들ㅜ
이번 주 미니 프로젝트에서 계속 삽질했던 포인트는 상관분석, 카이제곱검정, t검정에서의 p-value에 따른 귀무가설 기각이었다... ADsP를 땄다는 녀석이 이런 부분에서 실수를 하니 스스로 한심하게 느껴진 부분
이번 수업 리뷰
이번주 수업 중 인상 깊었던 내용수업 때 적었던 내용들 중 일
브라우저 홈페이지에서 F12를 눌러 페이지 내의 정보를 탐색하는 내용이 흥미로웠다.
Beautiful Soup 라이브러리, CSS를 열심히 배워서 웹 크롤링을 통해 추후에 해커톤이든 개인 프로젝트에서든 정보 수집 능력을 키우고 싶다는 생각을 했다!!
ADsP 합격!!
1 과목 만점으로 점수를 많이 딴게 다행 민트 이론 한 바퀴 돌리고, 모의고사 + 기출을 5바퀴 돌리니 시험 때 큰 어려움 없이 문제를 풀 수 있었다 역시 자격증은 무조건 기출 뺑뻉이
이번 주 셀프 테스트
그동안 셀프 테스트 점수가 잘 나와서 만만하게 봤는데 이번에는 수업 때 이론 부분에서 잘 집중을 못해서 그런지 쉽지 않게 느껴졌다
앞으로 수업에서 딴짓하지 말고 빡 집중 해야지!!
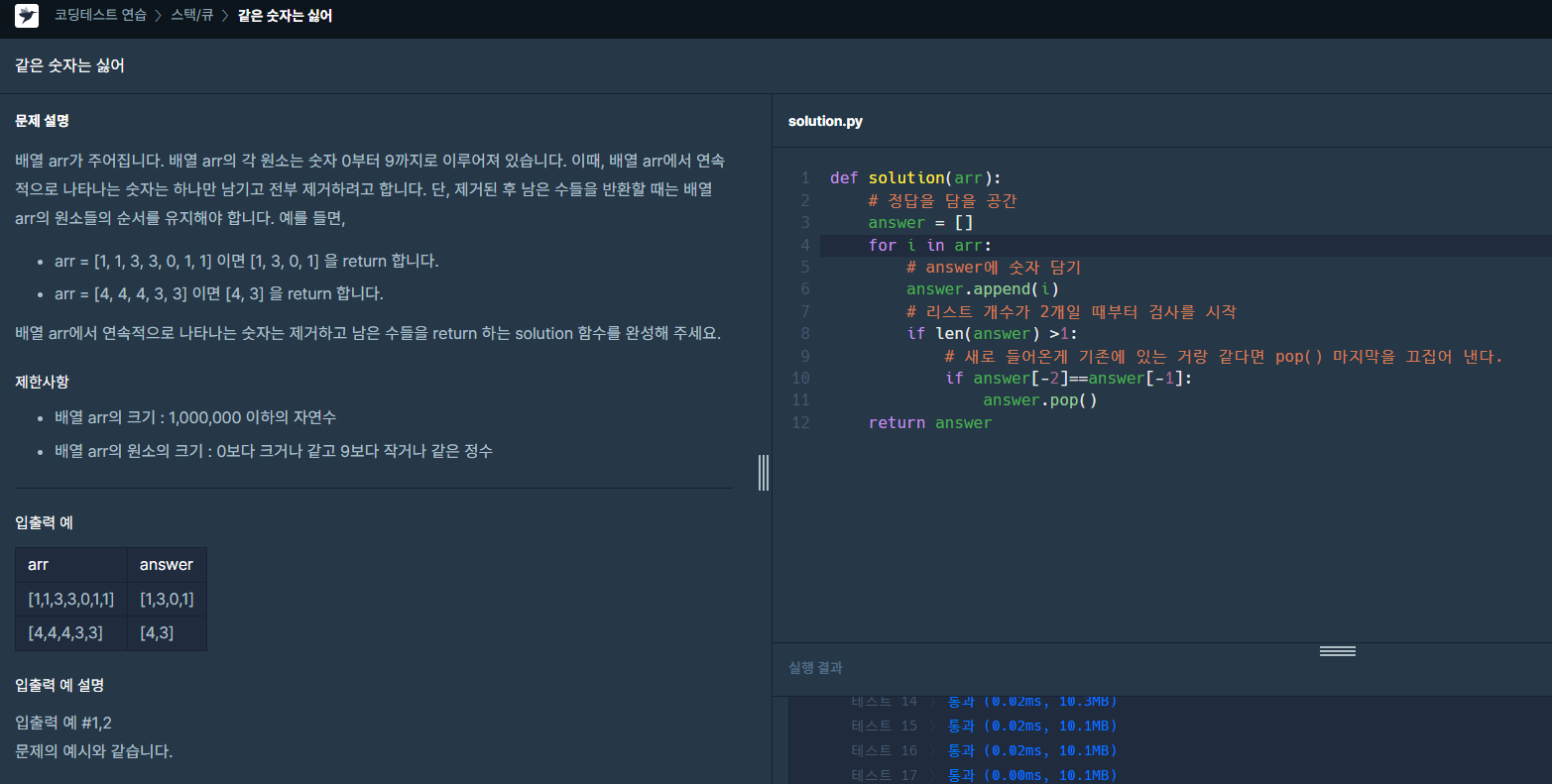
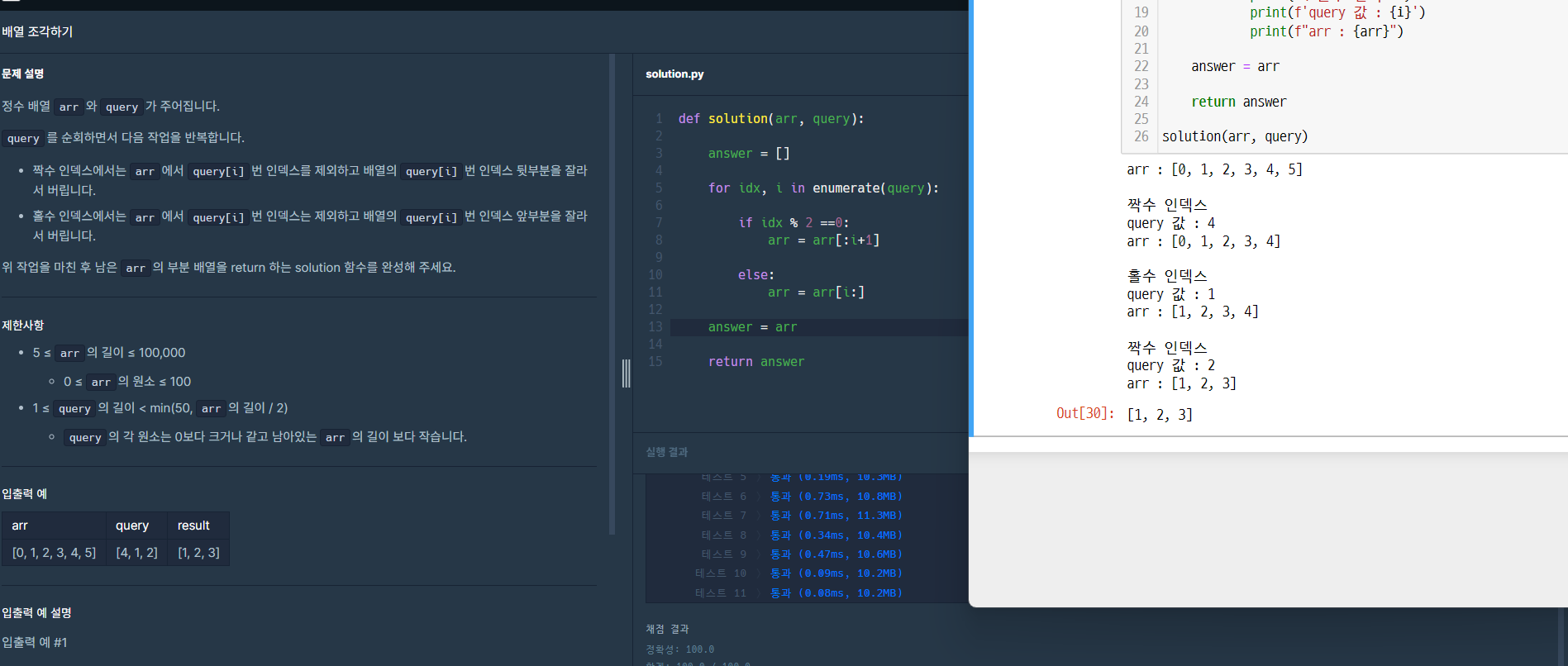
이번 주 프로그래머스 문제 풀이
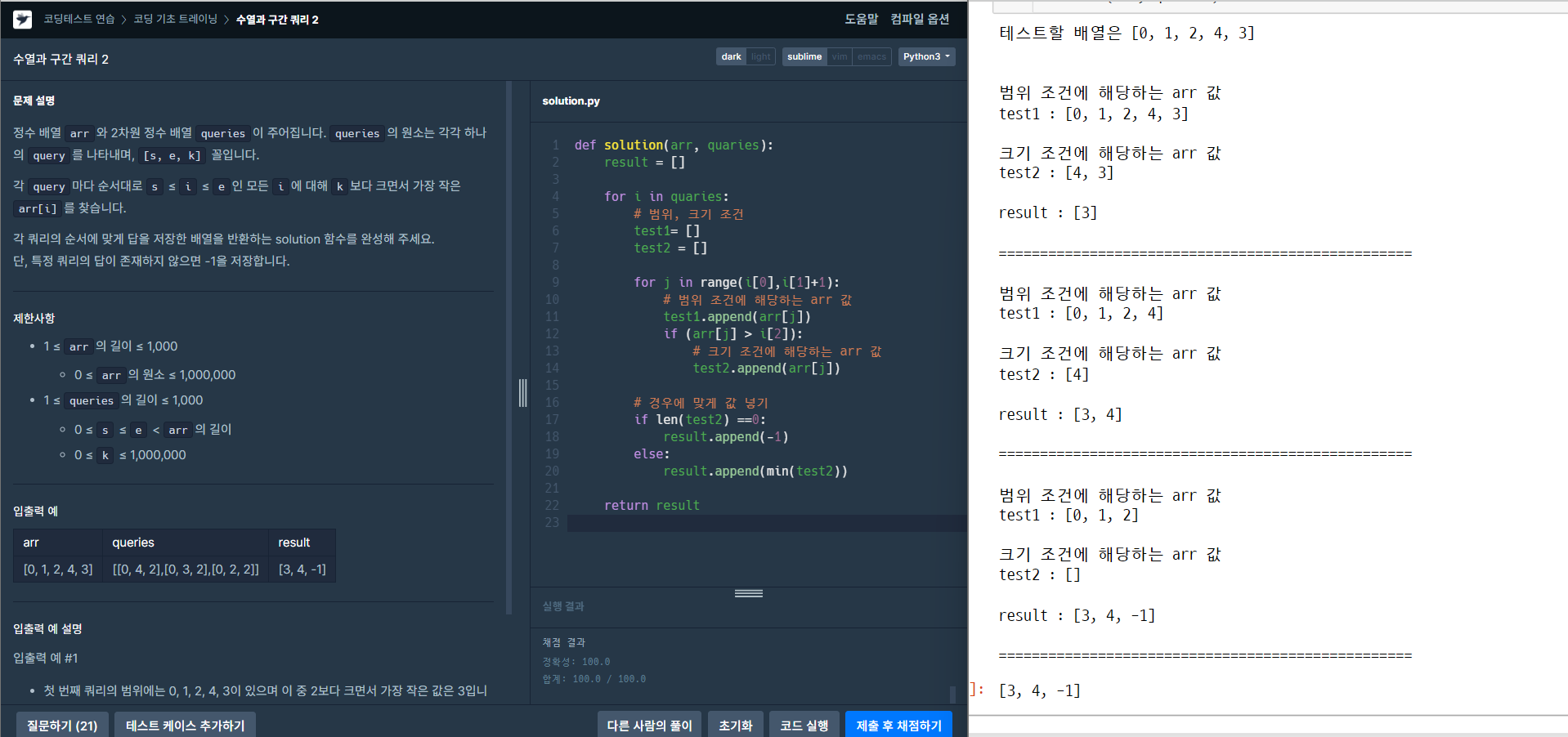
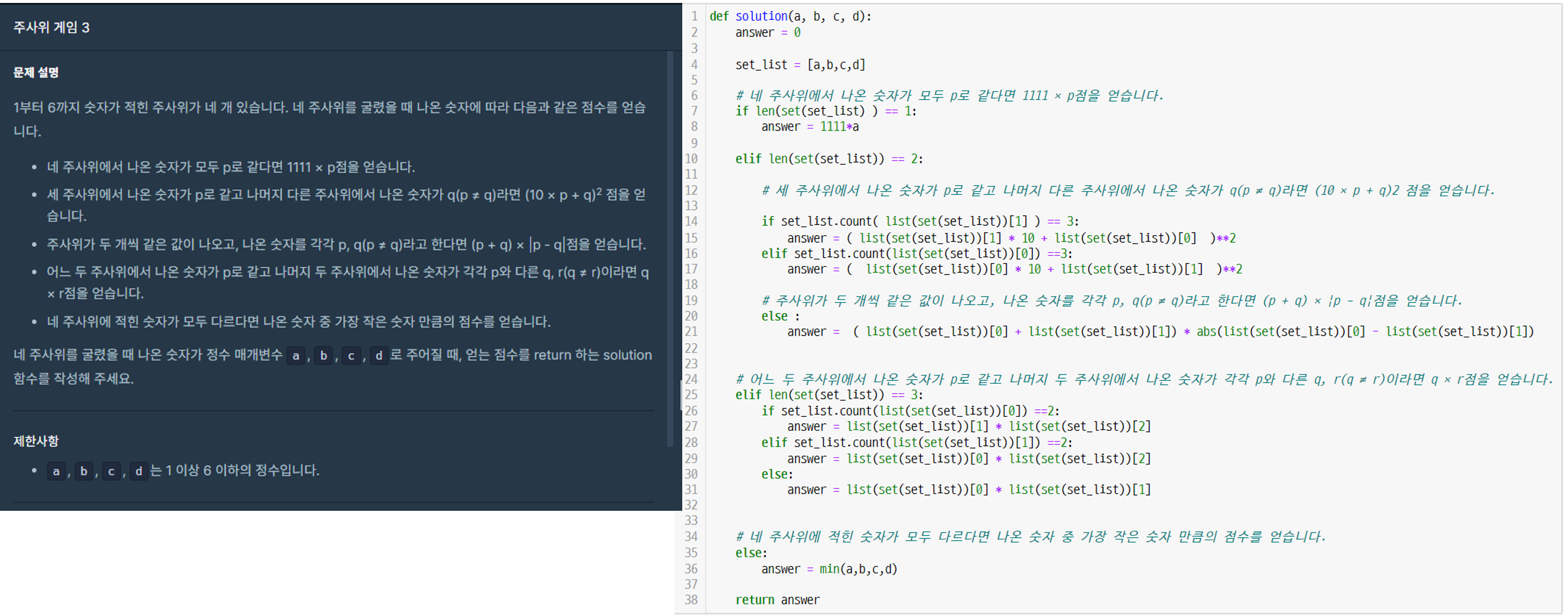
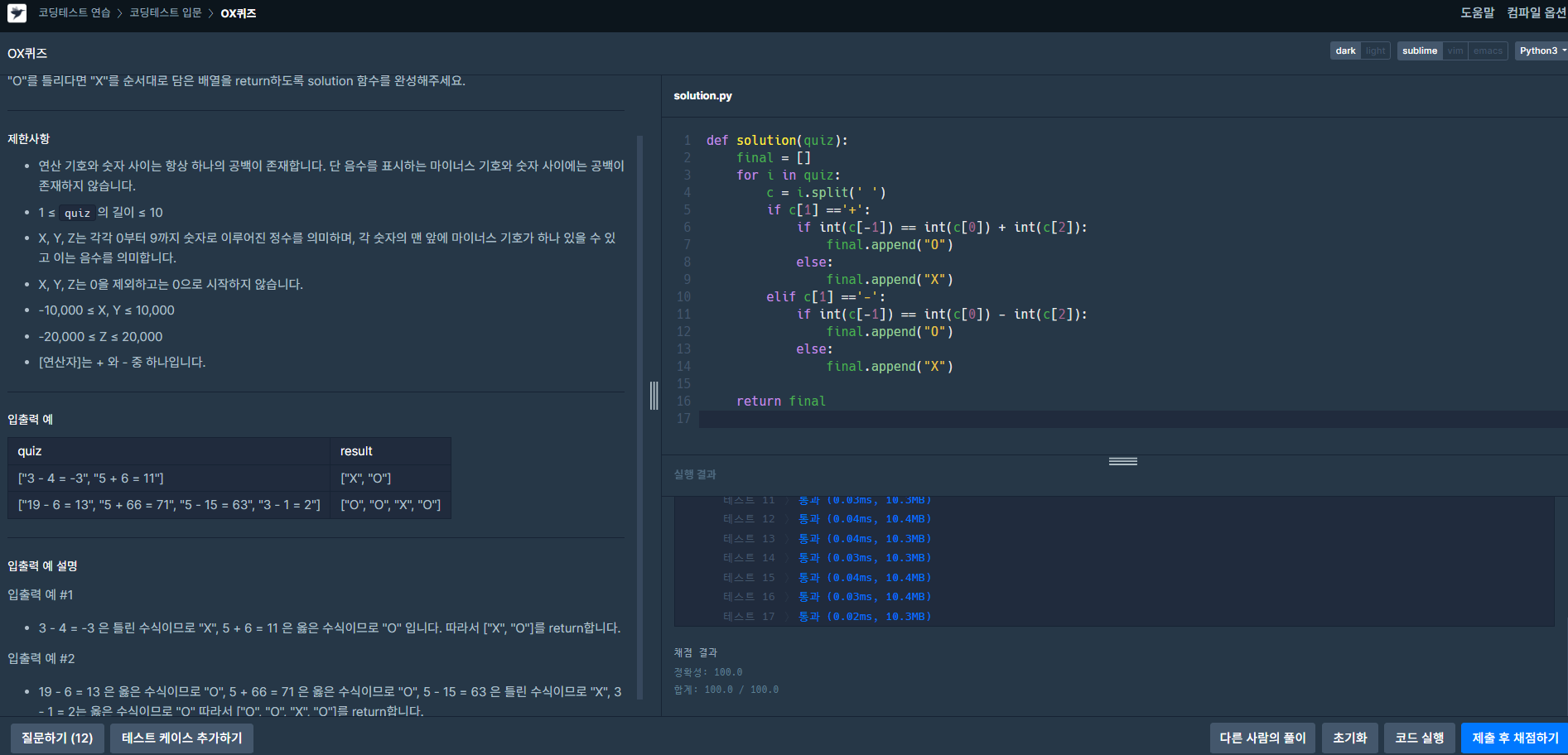
문제 <3진법 뒤집기>문제 <배열 조각하기>문제 <수열과 구간 쿼리 2>문제 <주사위 게임 3>
코드 정리
수치형 상관분석 p-value 내림차순 정렬
def pearson_value(df): keys = [] spst_list=[] spst_dict = {} for i in df.columns: if ( df[i].dtypes=='int64'): # print(i, base_data[i].dtypes) keys.append(i) # print(keys)
# 피어슨 상관분석 p-value 값을 value로 사용하기 위해 준비 for i in keys: spst_list.append(list(spst.pearsonr(df[i], df['Score_diff_total'] ))[1]) # print(spst_list) # print('='*100, '\n상관계수 p-value 출력', sep='') spst_dict = dict(zip(keys, spst_list)) # display(spst_dict) # 딕셔너리 형태로 만들어 p-value 값을 아래로 오름차순으로 출력 # lambda 매개변수 : 표현식 # items를 통해 키-값 쌍을 나타내는 튜플 리스트를 생성 # key = lambda x : x[1] 부분에서 'x'는 리스트에서 하나의 튜플 # x[1] 은 value 값을 정렬 기준으로 삼는다. spst_dict = sorted( spst_dict.items(), key = lambda x : x[1]) # display(spst_dict)
for key, value in spst_dict: print(f'{key}:{value}')
>> 두 개 이상의 범주형 변수 간에 독립성을 검정하는 데 사용한다 따라서, 검정을 통해 변수 간의 연관성을 파악하려면 원본 교차표를 사용해야 한다. Normalize하면 행과 열 합이 1이 되도록 스케일을 조정한다. 범주 간의 상대적 비율을 확인할 때는 유용하지만, 카이제곱 검정의 경우, 범주 간의 독립성을 여부를 확인하는 것이 목적이므로 스케일 조정을 하지 않는다.
카이제곱 검정
귀무가설 : 두 변수 간에 독립성이 있다. p-value가 0.05보다 클 때, 채택 대립가설 : 두 변수 간에 독립성이 없다. p-value가 0.05보다 작을 때, 채택
<주의>
ttest
귀무가설 : 두 집단 간의 평균에 유의미한 차이가 없다. p-value가 0.05보다 클 때, 채택 대립가설 : 두 집단 간의 평균에 유의미한 차이가 있다. p-value가 0.05보다 작을 때, 채택