KT Aivle School 에이블스쿨 기자단] 10.30(월)~ 11.05(일) 미프, 에이블데이, 기자단 발표
이번주 미프 훈남들
저번 미프에서는 현규님이 멋있게 보였고, 이번 미프에서는 민성님, 현빈님이 멋있다고 느껴졌다.
안정적인 발표를 보여준 민성님
월요일 발표 직후 반응
발표도 발표지만 마지막 저 멘트가 기억에 남았다.
높은 응용력을 보여준 현빈님
나는 주어진 과제 따라서 지도 정도까지 그리니까 시간이 끝났는데, Naver API 사용해서 지도까지 그린 걸 보고 대단하다고 생각을 했었다. 기회가 된다면 많이 배워보고 싶네요.
기자단 발표
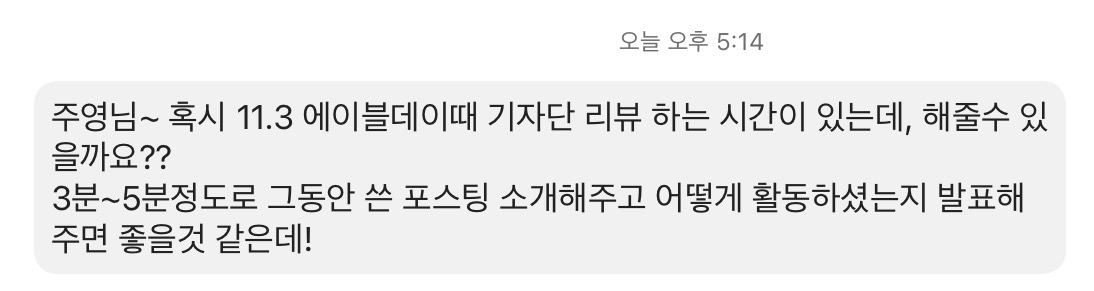
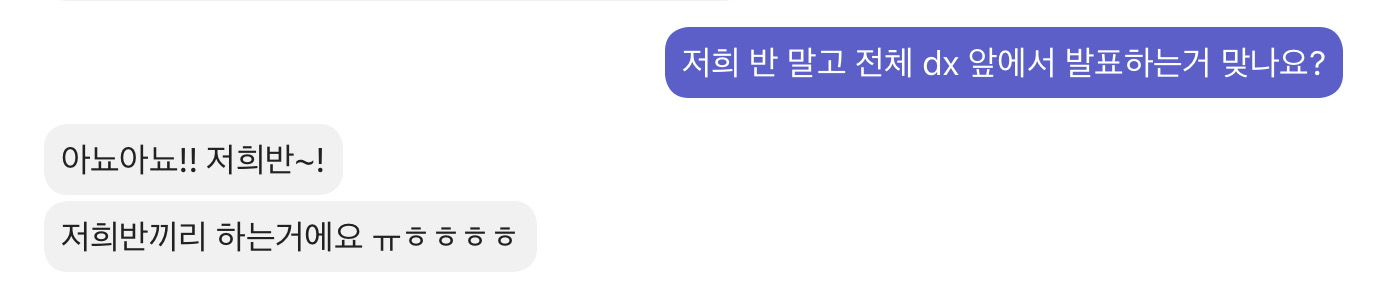
처음에 매니저님한테 메세지를 받았을 때는 DX가 모두 있는 Zoom에서 화면 공유하고 발표하는 알았다. 사람들이 많은 곳에서 발표하면서 그릇을 키워볼까 그냥 가만히 있을까 고민을 했는데, 다시 확인을 해보니 우리반에서 진행하는 걸 알게됐고 이정도면 할만하지 생각하고 하겠다고 말씀을 드렸다.
로젠택배 알림이 떠서 최근에 주문한게 없는데 뭘까..? 생각이 들었었다. 읽어보니 발송인이 AIVEL School로 써있었고 선물은 텀블러였다. 소소하게 기분이 좋았고, 나중에 이 텀블러로 커피를 마신다면 인증 사진을 올려야겠다.
import streamlit as st
import folium
import pandas as pd
map_data = pd.DataFrame({
'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97],
'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5],
'name': ['Buenos Aires', 'Paris', 'Melbourne', 'St Petersburg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'],
'value': [10, 12, 40, 70, 23, 43, 100, 43]
})
# folium.Map(): Folium에서 지도 객체를 생성# location: 지도가 초기에 어떤 위치에서 시작할지를 정의# map_data['lat'].mean()과 map_data['lon'].mean(): 평균 위도와 경도 위치를 지도 중심으로 설정# zoom_start: 이 매개변수는 지도의 초기 확대 수준 (default=10, 숫자가 클수록 확대)
my_map = folium.Map( location=[map_data['lat'].mean(), map_data['lon'].mean()], zoom_start=2 )
# 지도에 원형 마커와 값 추가for index, row in map_data.iterrows(): # 데이터프레임 한 행 씩 index, row에 담아서 처리
folium.CircleMarker( # 원 표시 선언
location=[row['lat'], row['lon']], # 원 중심- 위도, 경도
radius=row['value'] / 5, # 원의 반지름
color='pink', # 원의 테두리 색상
fill=True, # 원을 채움
fill_opacity=1.0# 원의 내부를 채울 때의 투명도
).add_to(my_map) # my_map에 원형 마커 추가
folium.Marker( # 값 표시 선언
location=[row['lat'], row['lon']], # 값 표시 위치- 위도, 경도
icon=folium.DivIcon(html=f"<div>{row['name']}{row['value']}</div>"), # row['name'], row['value'] 표시
).add_to(my_map) # my_map에 값 추가
# 타이틀과 캡션 표시하기
st.title('Map with Location Data')
st.caption("Displaying geographical data on a map using Streamlit and Folium")
# 지도 그리기# st.components.v1.html : Streamlit 라이브러리의 components 모듈에서 html 함수 사용# ._repr_html_() : 지도를 HTML 형식으로 표시
st.components.v1.html(my_map._repr_html_(), width=800, height=600)
# 파일실행: File > New > Terminal(anaconda prompt) - streamlit run streamlit\7-2.folium_map_ans.py
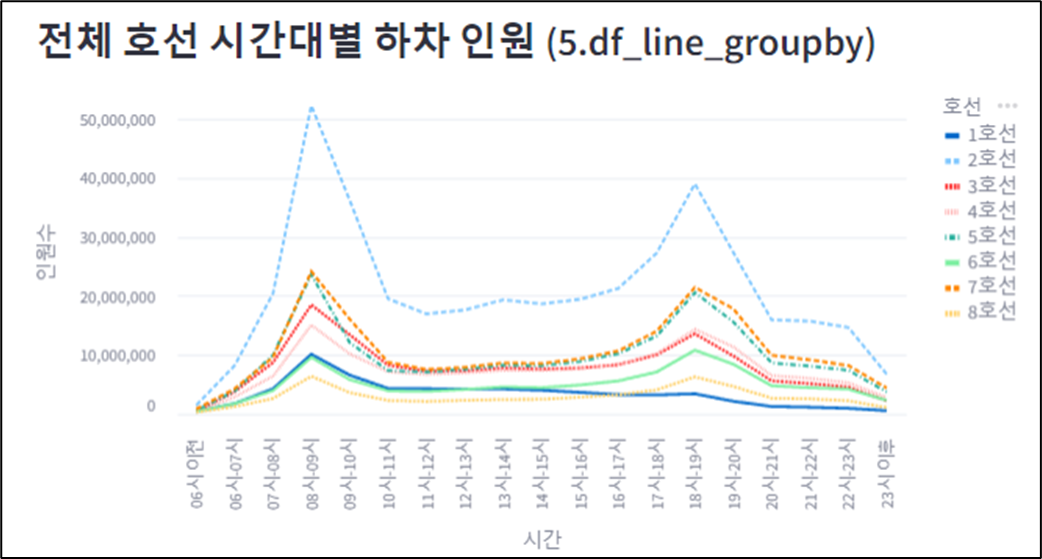
st.subheader('선택한 호선의 시간대별 하차 인원')
# 데이터프레임- df_line_groupby ('호선', '시간대별' 인원 집계 )# ['호선'] 컬럼에 대해 .unique() 매소드를 사용하여 # selectbox에 호선이 각각 하나만 나타나게 함
option = st.selectbox('호선 선택 (5.df_line_groupby)', df_line_groupby['호선'].unique())
# .loc 함수를 사용하여 선택한 호선 데이터 선별하고# 새로운 데이터 프레임-에 저장 & 확인
df_selected_line = df_line_groupby.loc[df_line_groupby['호선'] ==option]
st.write(option, ' 데이터 (df_selected_line)', df_selected_line)
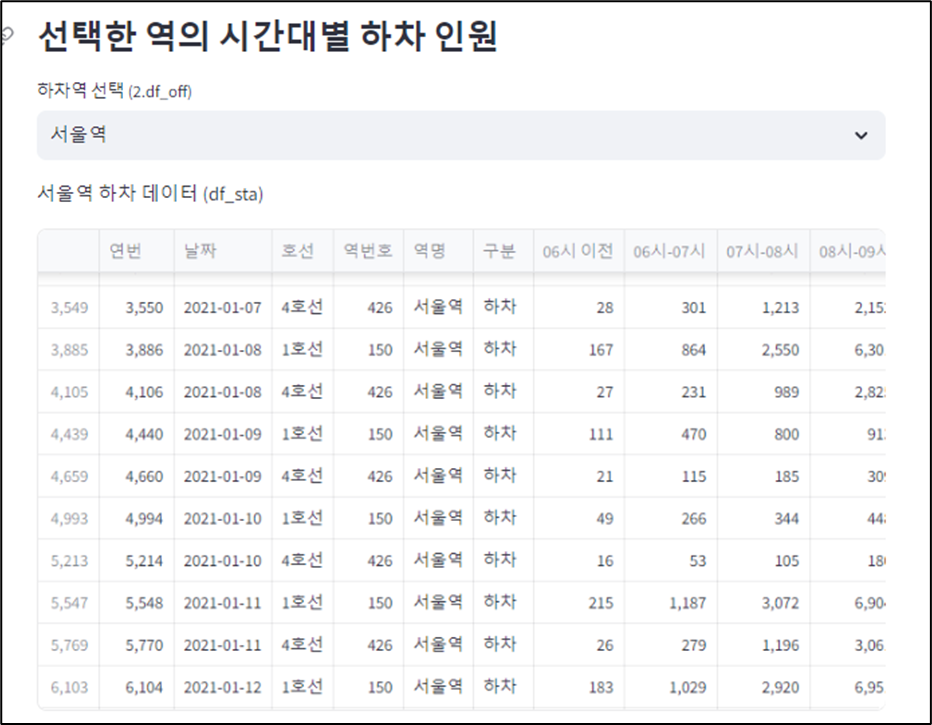
st.subheader('선택한 역의 시간대별 하차 인원')
# selectbox를 사용하여 '하차역' 선택# ['역명'] 컬럼에 대해 .unique() 매소드를 사용하여 # selectbox에 역명이 각각 하나만 나타나게 함
option = st.selectbox('하차역 선택 (2.df_off)', df_off['역명'].unique())
# .loc 함수를 사용하여 선택한 역의 데이터를 선별하고# 새로운 데이터 프레임에 저장
df_sta = df_off.loc[df_off['역명'] == option]
st.write(option, '하차 데이터 (df_sta)', df_sta)
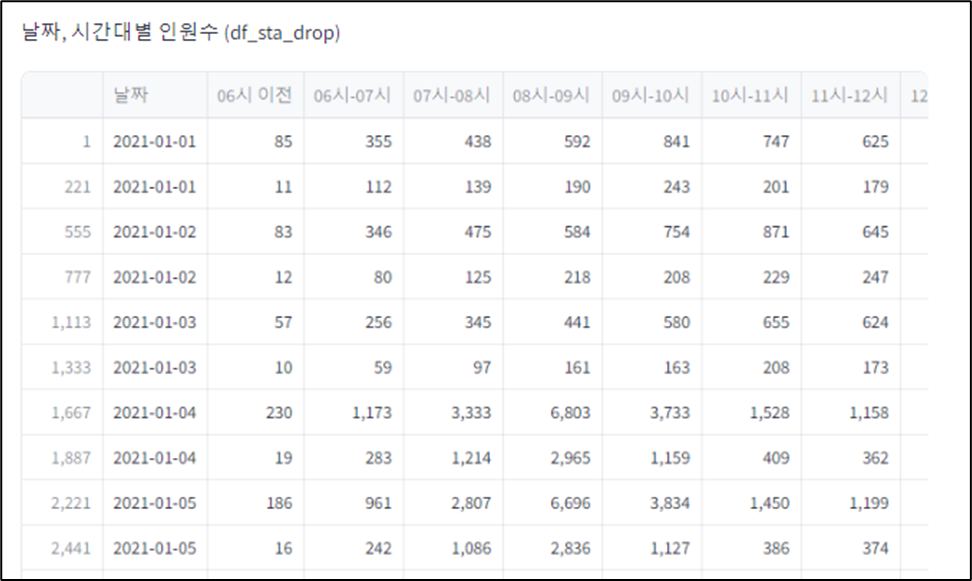
# 불필요한 컬럼 '연번','호선','역번호','역명','구분','합계' 제외하고 기존 데이터 프레임에 저장# 참고) df_sta = df_sta[df_sta.columns.difference(['연번', '호선', '역번호', '역명','구분','합계'])]
df_sta_drop = df_sta.drop(['연번', '호선', '역번호', '역명','구분','합계'], axis=1)
st.write('날짜, 시간대별 인원수 (df_sta_drop)', df_sta_drop)
# melt 함수 사용 unpivot: identifier-'날짜', unpivot column-'시간', value column-'인원수' # 새로운 데이터 프레임-에 저장 & 확인
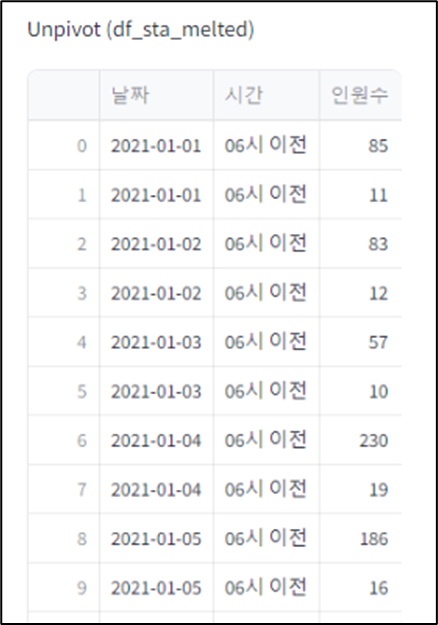
df_sta_melted = pd.melt(df_sta_drop, id_vars=['날짜'], var_name='시간', value_name='인원수')
st.write('Unpivot (df_sta_melted)', df_sta_melted)
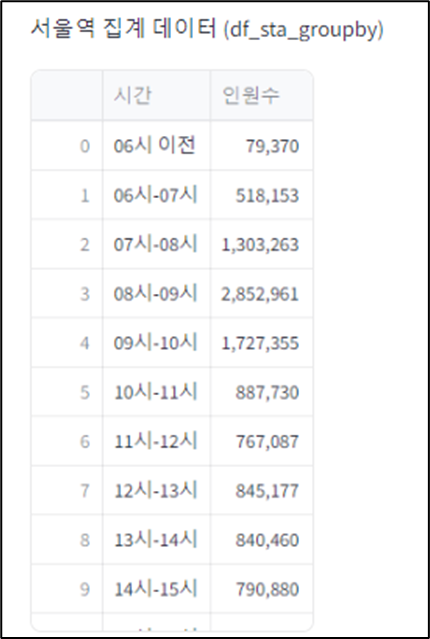
# '시간' 별 '인원수' 집계 , as_index=False# 새로운 데이터 프레임-에 저장 & 확인
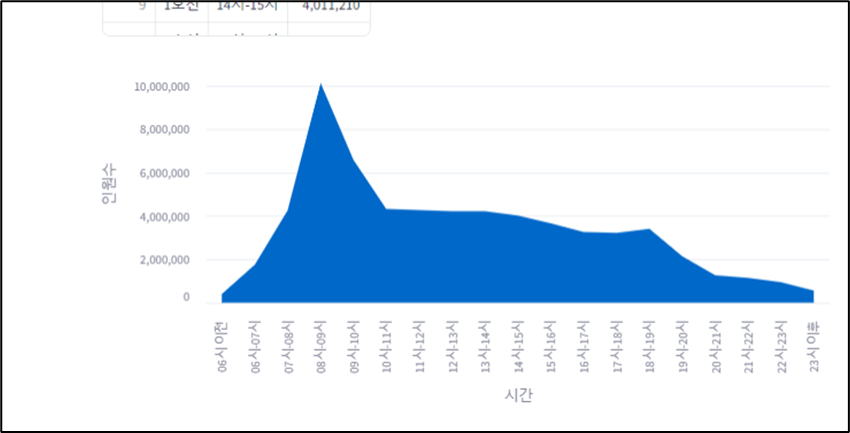
df_sta_groupby = df_sta_melted(['시간'], as_index = False)['인원수'].sum()
st.write(option, ' 집계 데이터 (dfa_sta_groupb)', df_sta_groupby)
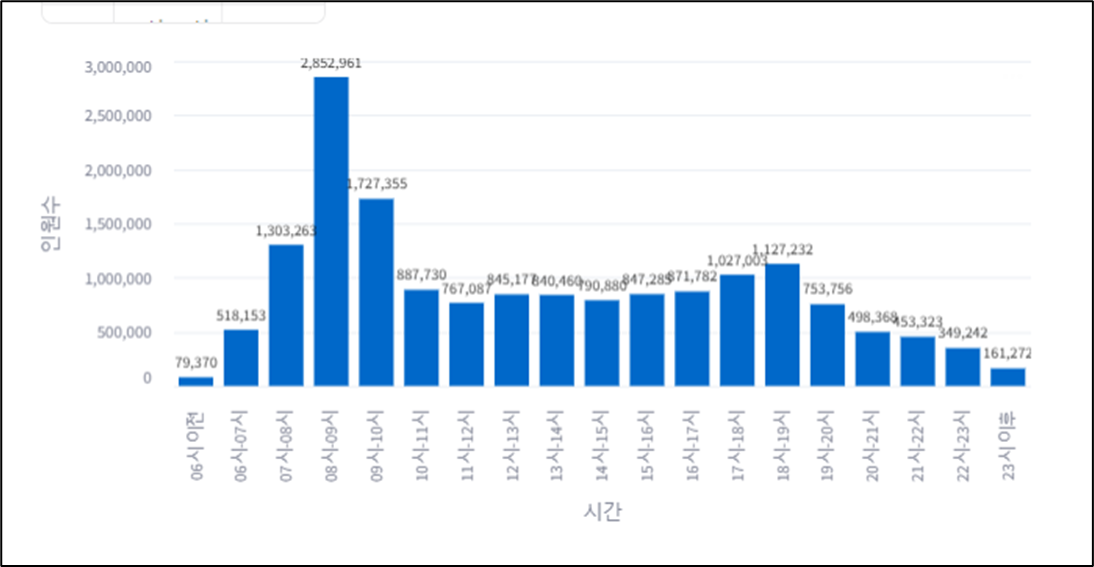
altair mark_bar chart + text 그리기 mark_bar()
# 데이터프레임- df_sta_groupby, x-'시간', y-'인원수'
chart = alt.Chart(df_sta_groupby).mark_bar().encode(
x = '시간', y = '인원수').properties(width = 650, height = 350)
text = alt.Chart(df_sta_groupby).mark_text(dx = 0, dy = -10, color = 'black').encode(
x = '시간', y = '인원수', text = alt.Text('인원수:Q', format = ',.0f') )
# format=',.0f' : 천 단위 구분기호+소수점 이하 0
st.altair_chart(chart+text, use_container_width = True)
미프 시작, 언어 지능 2일 & 시각 지능 3일 <- 아쉽게도 예비군으로 언어 지능 2일은 통째로 불참
목요일 미프 내려가는 날
현규님 첫 발표
미프 시작
저번 주에 배운 언어 지능 수업과 시각 지능 수업을 토대로 일주일 동안 미니 프로젝트가 진행된다. 미니 예비군으로 인해 2일 동안 진행하는 언어 지능 미니 프로젝트는 통째로 참가하지 못하는 것이 아쉽다.
꾸준히 쌓여가는 미프 자료들
위의 파일들을 제외하고 1~3차 프로젝트들도 저렇게 깔끔하게 정리해두었다. 이렇게 정리해둔 것이 빅프로젝트 때 아이디어에 대한 영감을 얻을 때 도움이 될 거라 기대한다. 개인적으로 공부할게 있어서 내가 참여하지 못한 언어지능 프로젝트에 대해 복습을 하지 못했기에 주말을 이용하여 정리할 예정이다.
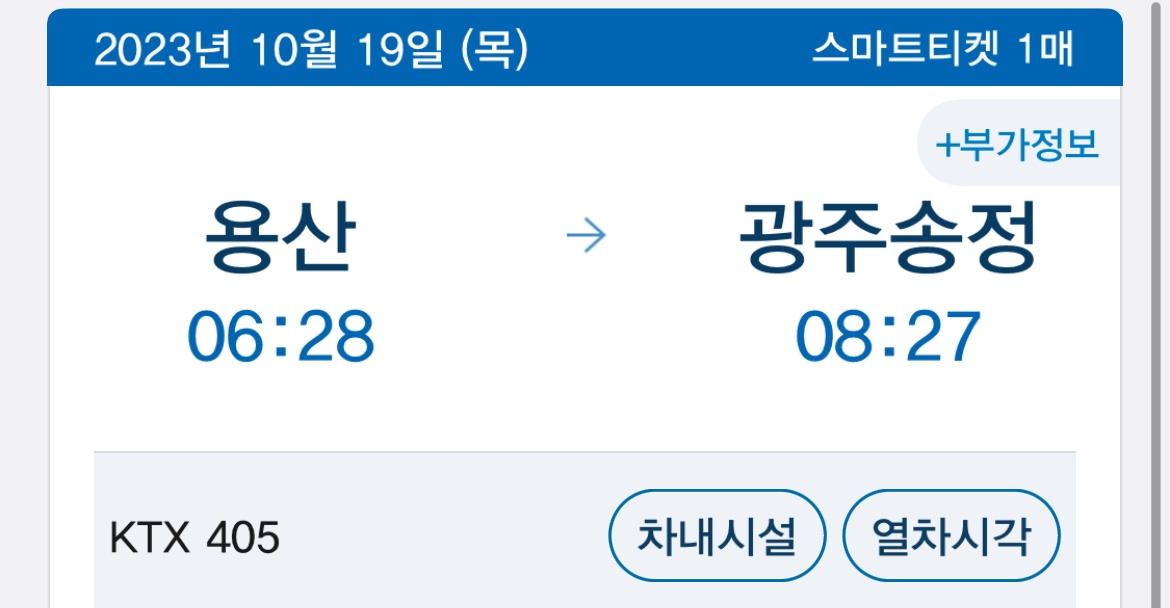
목요일 미프 내려가는 날
서울에서 광주까지 당일치기를 하기 위해 하루를 4시 20분에 시작했다. KTX 안에서 갈 때 2시간, 올 때 2시간이면 이론상 4시간 수면 확보 가능!
오랜만에 온 교육장
저번에도 왔었지만 다시 오니 감회가 새롭다.
현규님 첫 발표
미프 초창기를 제외하고 우리 권역에서 한동안 발표가 없었는데 목~금으로 현규님이 발표를 해주었고, 높은 수준으로 다른 분반 사람들에게 칭찬을 들었다. 평소 스터디를 진행하시며 꾸준히 노력하셔서 이런 성과를 내신 거라 생각했고 나도 스터디에 참여하겠다는 의사를 전달했다. 다음 미프 때는 내가 발표할 수 있도록 좀 더 노력해야겠다는 자극을 받을 수 있었다.
YOLOv5 학습 모델
이번 미프 때 배운 YOLO 학습 모델로 우측으로 갈수록 학습률이 좋으나 구조가 복잡해져 용량이 크고 학습 속도가 느리다는 단점을 갖는다. 현재 가지고 있는 데이터셋을 보고 알맞은 모델을 사용한다면 정확도와 용량, 속도 면에서 모두 좋은 결과가 있을 것이다.
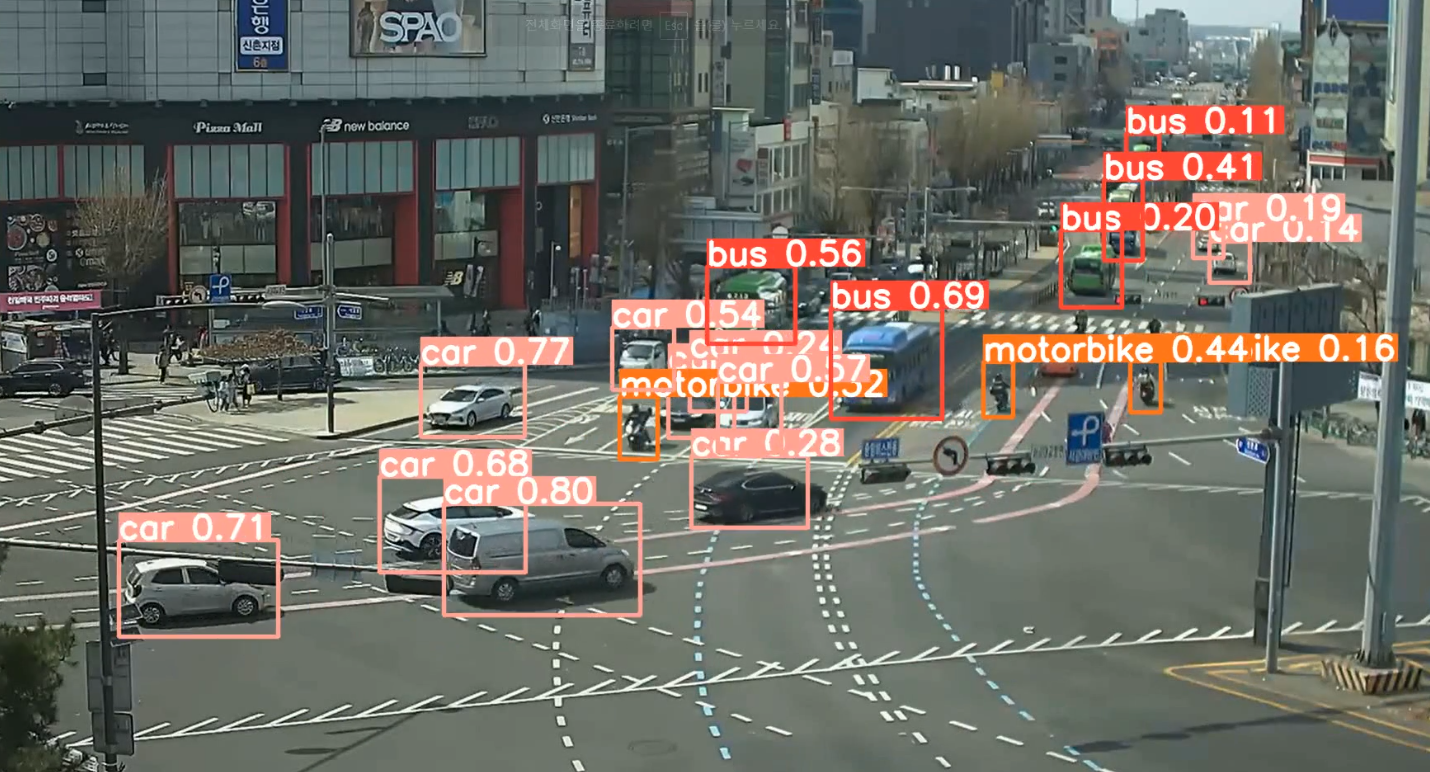
금요일에 진행한 CCTV 영상 속 차량 인식 프로젝트 사진이다. 목요일에 만든 130장의 사진과 추가로 구한 사진을 사용하였고, 처음에 할 때는 잘 진행되지 않았는데 200번의 학습을 돌리니 123번에서 얼리 스탑핑이 되고 인식이 잘 되었다.
KT Aivle School 에이블스쿨 기자단] 10.09(월) ~ 10.15(일) YOLO, Github
내용
시각지능
- YOLO
- ROBOFLOW
GitHub 버전 관리 시작
다음주 목요일 미프 교육장 예약
시각지능
시각지능 미니프로젝트에서 유용하게 사용될 예정인 YOLO 모델
실습 교안 중에서 SlowStart 파일로 자세한 설명을 들었다.
YOLO 모델을 사용함에 있어 사이트를 직접 들어가서 파라미터에 대해 스스로 알아보는 것이 필요함을 배웠다.
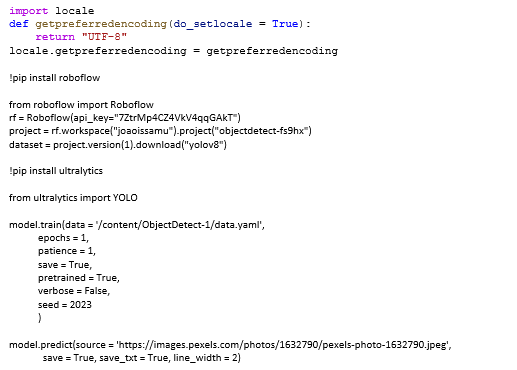
RoboFlow
Donwload Dataset을 눌러 코드를 복사한 이후 붙여 넣기를 하여 다음의 코드를 실행한다.
Github 버전 관리 시작
부스트 코스 강의를 통해 Git Hud를 다루는 법을 배웠다. 처음에는 Github를 쓰는 이유가 뭘지 알지 못해서 그렇게 필요한지 몰랐었다. 하지만 강의를 듣고 이제 commit, push, pull을 제대로 활용할줄 알게 되니 따로 파일을 정리해둘 때보다 편리함을 느꼈고 앞으로는 꾸준히 이곳에 업로드를 할 생각이다.
어떤 분이 나를 팔로잉 해주었다
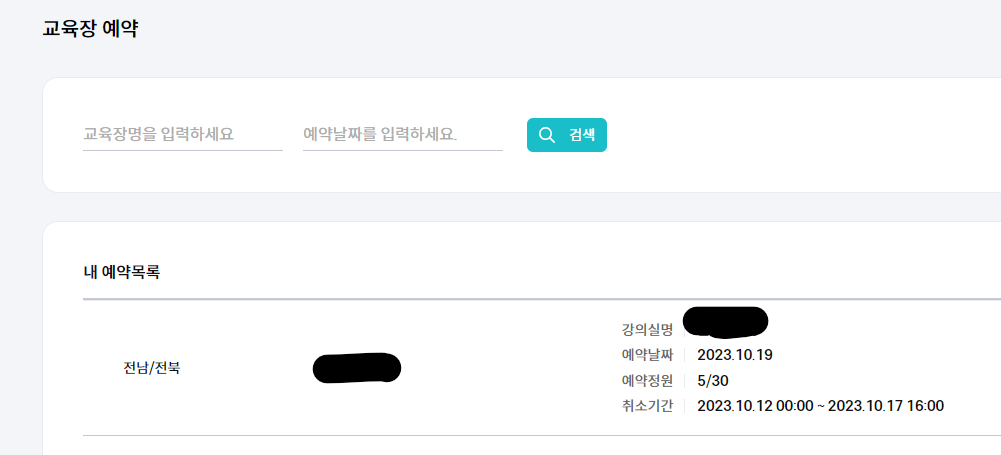
미프 교육장 예약
목요일에는 미니 프로젝트 진행을 위해 교육장을 예약했다. 월~화는 예비군이 잡혀 있기 때문에 선택권이 없고, 남은 요일 중에서는 목요일에 사람들이 많이 몰려서 이 날짜를 선택했다. 왕복 기차표도 예매 완료!
KT Aivle School 에이블스쿨 기자단] 10.02(월) ~ 10.8(일) 코랩 결제, AICE, 듀얼 모니터
내용
구글 코랩 결제
AICE ASSOCIATE 무료 응시 기회!!
집에 있던 모니터와 듀얼 모니터 연결
미프를 위한 구글 코랩 결제
구글 코랩 결제
원활한 미프 진행을 위해 KT에서 구글 Colaboratoy Pro 버전 비용을 지원해주었다
인공지능 학습을 위해서는 GPU의 성능이 중요했기 때문이고, 앞으로는 T4 GPU 기능을 원활하게 사용할 예정
AICE 자격증
AICE 자격증
KT AIVLE School에서는 특별히 에이블러들을 위해 AICE 자격증 ASSOCIATE 등급 시험 비용을 지원해주고 있다.
AI 역량 개발을 위하여 KT가 만든 자격증으로 이 자격증을 공부하고 취득한다면 AI 역량을 키워감에 있어 큰 도움이 될 거라 생각한다.
수업 때 공부한 인공지능 이론을 다시 복습하며 자격증에 도전하려고 한다.
집에 있던 모니터와 듀얼 모니터 연결
그동안은 Twomon SE 어플을 통해 아이패드를 듀얼 모니터로 사용하고 있었으나 코드가 점점 길어지고 내용이 복잡해지며 한계를 느꼈다. 물론 실력이 더 좋았다면 문제가 없었겠지만...
아이패드 듀얼모니터 어플집에 있던 모니터와 듀얼 모니터 설정
HDMI 케이블을 찾기가 귀찮아서 그동안 집 모니터와의 연결을 피했지만, 이제는 연결을 해야겠다는 생각으로 세팅을 완료했다. 확실히 아이패드가 아니라 큰 데스크탑 모니터를 연결하니 다르다고 느꼈고 진작하지 않은 것에 아쉬움을 느꼈다. 앞으로는 이 세팅을 통해 능률을 Up! 할 예정