[통계 기초의 모든것 올인원] 메타코드 강의 후기 - 모분산, 두 집단 비교
통계 기초의 모든것 올인원 [ 1편, 2편 ]ㅣ18만 조회수 검증
www.metacodes.co.kr
모분산 검정의 필요성, 예시

모분산 검정은 두 가지 집단이 모평균의 차이가 있냐 없냐를 판단할 때 중요하다.
왜냐하면, 그러한 검정은 두 집단의 모분산이 같다가 전제되어야 하기 때문이다.
등분산 조건을 의미한다.
이 문제에서 대립 가설은 분산이 0.1보다 작다는 것이 된다.
확률 표현은 오른쪽 영역을 기준으로 한다.
기각역은 10.117이 되는데 검정통계량 계산량은 9.5가 되므로 귀무가설을 기각할 수 있게 된다.
집단 비교
두 집단의 비교에는 분산이 고려되어야 한다는 것이 중요한 포인트이다.
분산이 고려되었을 때 객관적 비교가 가능하기 때문이다.
모분산은 아는데, 정규 모집단이면 Z 통계량을 사용한다.
모분산은 모르는데, 정규 모집단이긴 하다면,
모분산이 같은지 혹은 모분산이 다른지 확인하는 절차가 필요하다.
모분산 아는 경우의 모집단 비교

정규모집단 가정이 되어있는 상태이다.
기댓값 E의 경우 하나의 항에서 두 개의 항으로 분리가 가능하다.
이때, 각각의 기댓값은 뮤이다.
Variance는 분해를 할 때, 독립이라는 전제가 되어있다면 분해가 가능하다. 이때, 괄호 안이 + 부호이든 - 부호이든 더하기 형태로 분해된다.
모집단 비교 - 예시 #1
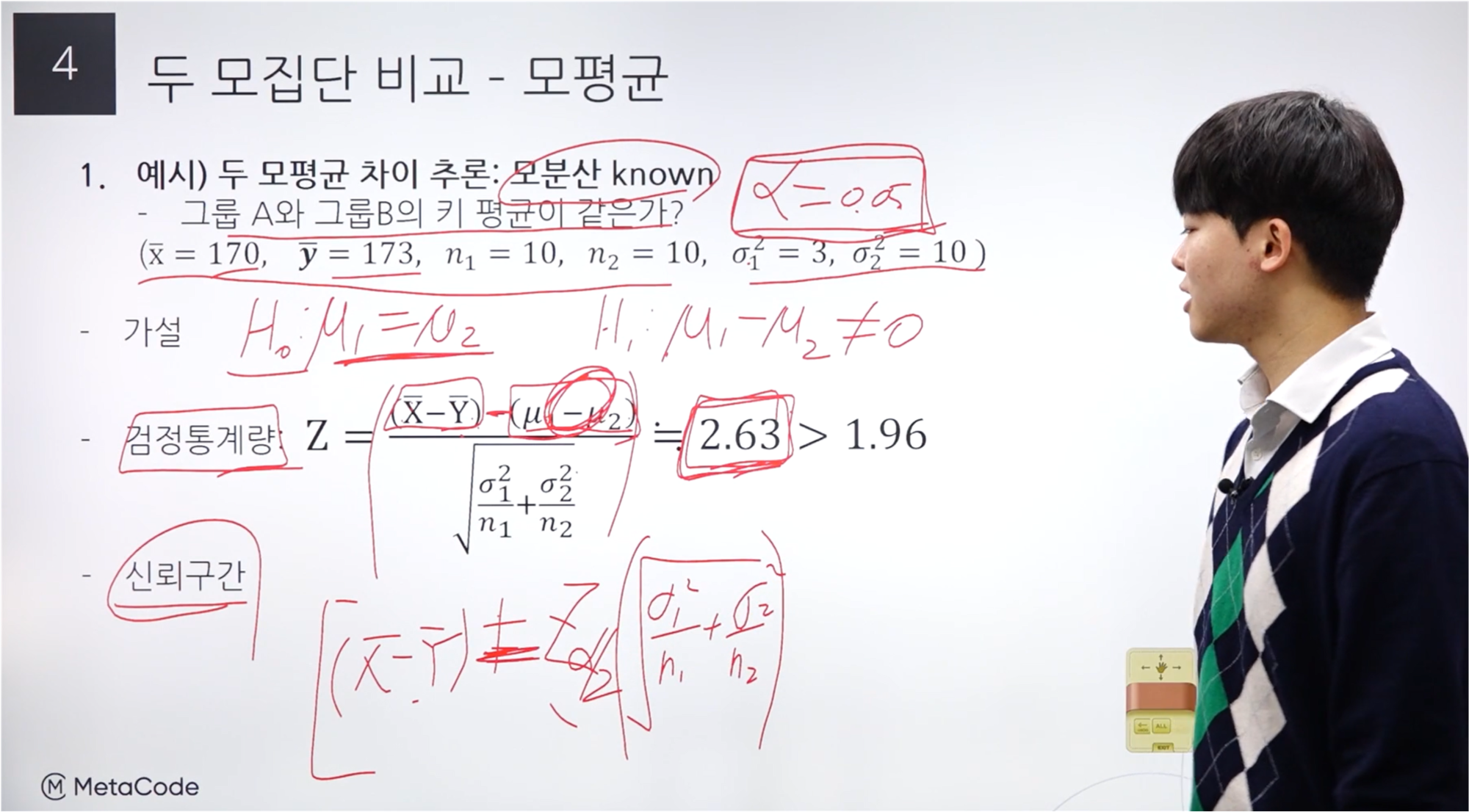
문제 조건에서 모분산을 알고 있다고 가정한다.
같은 지 물어보는 것이기 때문에 양측 검정에 해당한다.
대립 가설은 키 평균이 같지 않다는 것이 된다.
검정 통계량 식은 윗 슬라이드에 있던 내용이다.
검정은 귀무가설의 입장을 기준으로 한다. 즉, 일단 귀무 가설의 말이 맞다고 가정한다는 의미이다.
뮤 1과 뮤2는, 귀무가설이 “평균이 같다”이므로 0이 된다.
계산 결과가 2.63이므로 귀무가설을 기각할 수 있게 된다.
모집단 비교 - 예시 #2

t 통계량을 사용하는 경우의 문제이다.
귀무가설은 평균이 같다는 경우가 되고, 대립 가설은 같지 않다가 된다.
같지 않다가 조건이므로 양측 검정에 해당하며 ( 알파 / 2 ) 값을 확인한다.
이 문제에서는 계산 결과가 유의수준보다 크기 때문에 귀무가설을 기각할 수 있게 된다.
슬라이드에서 검정 통계량에 Z 가 아니라 T로 수정해야 한다.
모집단 비교 - 예시 #3
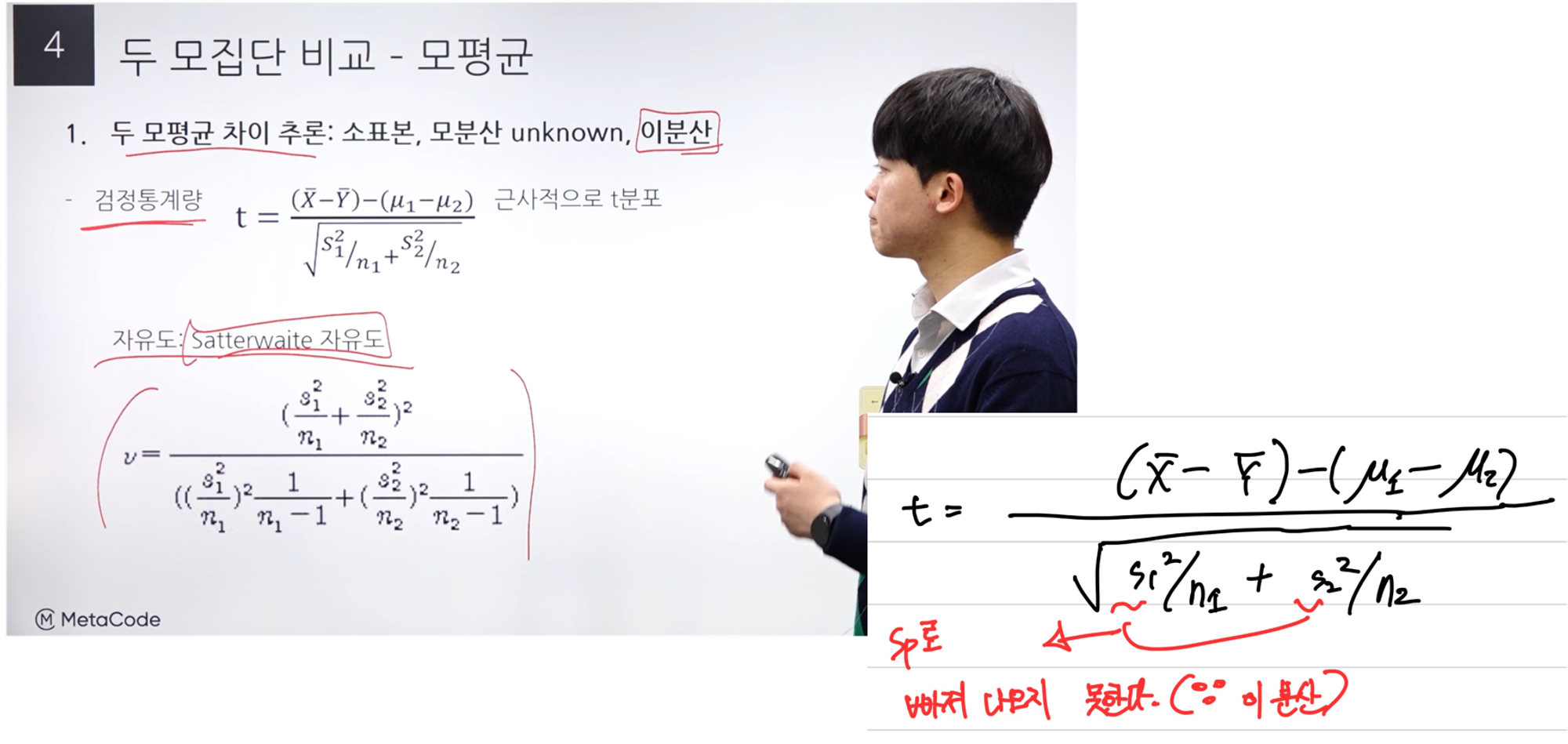
다른 조건은 같지만 분산이 다른 경우이다.
이분산인 경우에는 t 검정 통계량을 사용한다.
이분산이기 때문에 검정 통계량 식에서 s1, s2가 빠져나오지 못한다는 것이 앞의 문제와 차이이다.
밑의 자유도 식은 뒷 과정에서 다룰 것이다.
'통계 - 메타코드' 카테고리의 다른 글
| [메타코드 강의 후기] 통계 기초의 모든것 올인원 - 일원분산분석_240623 (0) | 2024.06.23 |
|---|---|
| [메타코드 강의 후기] 통계 기초의 모든것 올인원 - 대응비교, 모비율, 모분산 비교_240616 (0) | 2024.06.16 |
| [통계 기초의 모든것 올인원] 메타코드 강의 후기 - 검정 (0) | 2024.05.30 |
| [통계 기초의 모든것 올인원] 메타코드 강의 후기 - 구간추정/표본크기결정, 검정 (0) | 2024.05.29 |
| [통계 기초의 모든것 올인원] 메타코드 강의 후기 - 점추정/구간추정 (1) | 2024.05.26 |





