import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
target = '등록차량수'for feature in analyze_features:
print(f"[{feature}] 통계 분석 및 그래프 분석")
# 통계 분석 : 통계 분석print(" ***** 통계 분석 *****")
result = spst.pearsonr(data[feature], data[target])
print(feature, " vs ", target, " 상관 분석: ", spst.pearsonr(data[feature], data[target]))
if result[1] > 0.05:
print(f"통계분석 결과 : {feature}는 등록차량수에 영향을 주지 않는다")
else:
print(f"통계분석 결과 : {feature}는 등록차량수에 영향을 준다")
# 그래프 분석 : regplot# plt.figure(figsize = (12,8))print(" ***** 그래프 분석 *****")
sns.regplot(x = feature, y= target, data = data)
plt.grid()
plt.show()
print("")
print("-"*50)
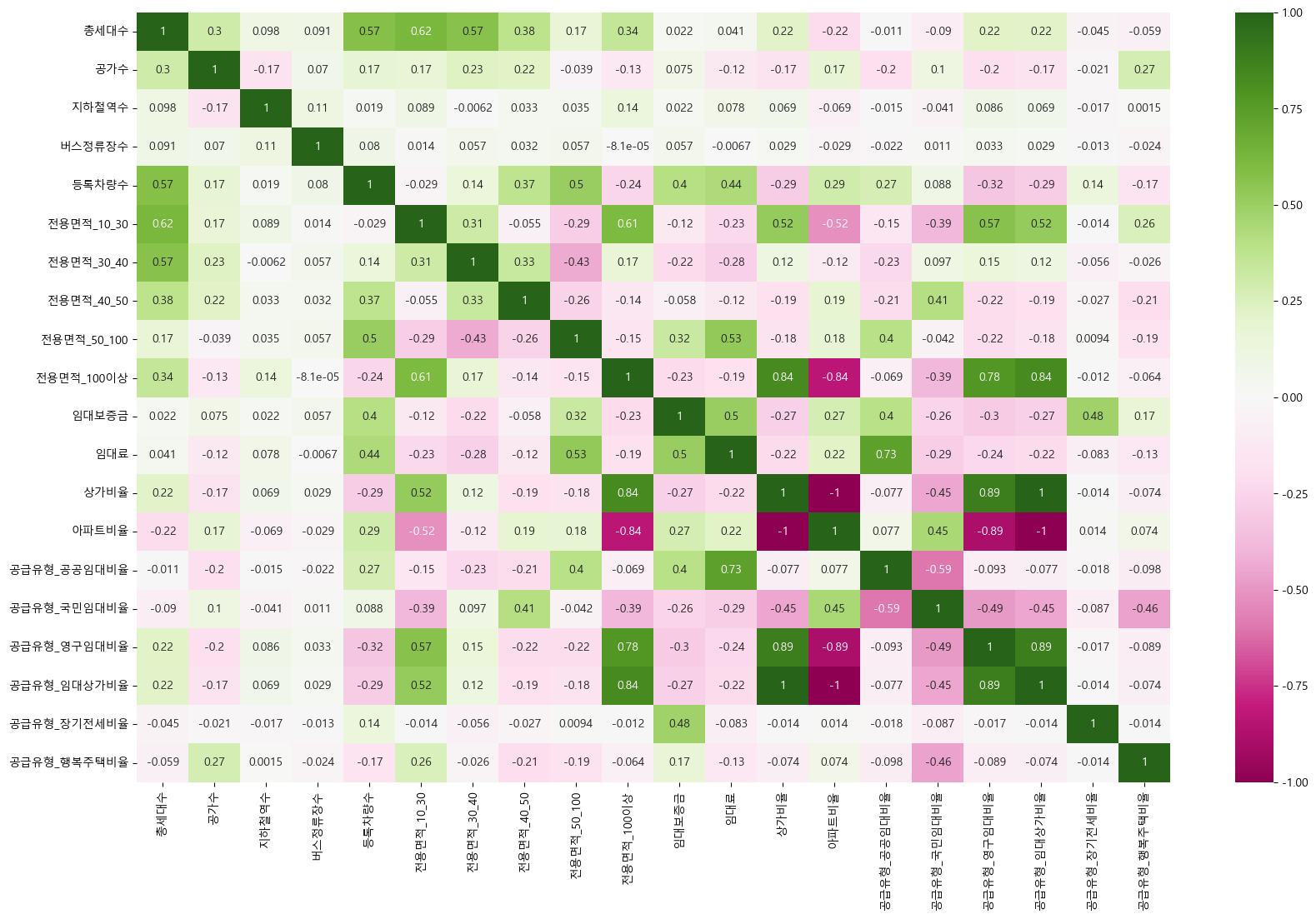
heatmap
## 각 컬럼간 상관계수에 대한 heatmap 그래프 분석
plt.figure(figsize = (20,12))
sns.heatmap(data[col_num].corr(),cmap="PiYG", annot=True)
plt.show()
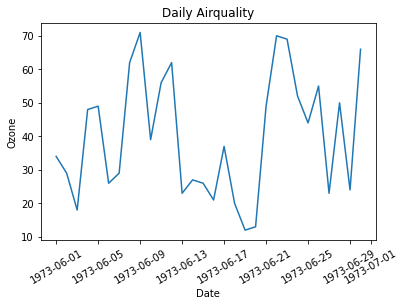
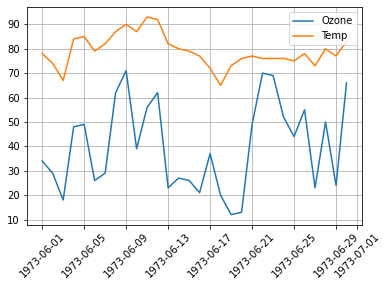
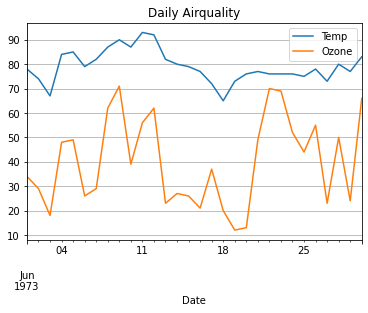
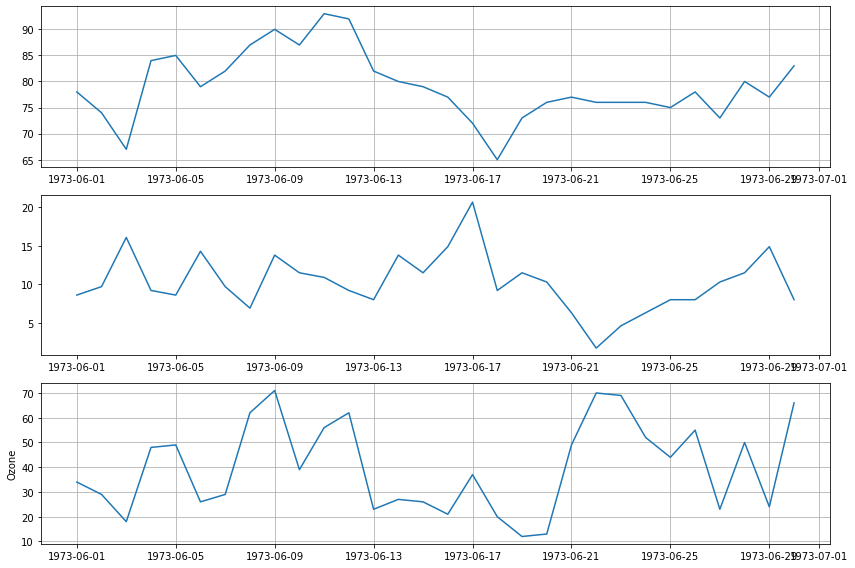
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()