KT Aivle School 에이블스쿨 기자단] 12.04(월)~ 12.10(일) 빅프로젝트, Aivle Day 2차

Aivle Day 2차 일정
2차 Aivle Day의 경우, 오전에는 희망하는 인원에 한해 코딩 테스트를 진행하였고, 오후에는 다함께 취업 컨설팅 강의를 들었다. 가장 기억에 남는 내용은 자기소개서에 "수치화" 요소를 담으라는 조언이었고, 이 부분과 관련하여 채팅창에 질문을 드렸고, 친절한 답변을 얻을 수 있었다. 또한 "3-step 전략"에 대해서도 강조를 하셨고, 실제 합격 자소서와 불합격 자소서의 사례를 들어서 보여주시니 이해하기 쉬웠고, 나 또한 전략적으로 자소서를 구성할 수 있도록 해야겠다고 마음을 다짐했다.
Aivle Day 선물 - 치킨
내가 평소에 좋아하는 BBQ 치킨을 쿠폰으로 받아서 만족스러웠고, 돈을 추가로 지불하여 "황금올리브 콤보"로 주문했다. 원래는 금요일 Aivle Day 2차 랜선 회식 때 시켜 먹는거였지만, 목요일에 치킨이 너무 간절하여 밤에 주문해서 먹었다.
Aivle Day 선물 - 샴푸, 핸드크림 등
타지 사람이라 빅프 기간 동안에 광주에 고시텔을 잡고, 내려가서 머물게 되었는데 마침 필요했던 샴푸, 로션, 바디워시에 더해 핸드크림까지 받아서 나에게는 더욱 실용적인 선물이었다. 자취를 하게 되면 이러한 물품들을 사는 게 개인적으로 돈이 아깝게 느껴지는데 이를 해결할 수 있었다.
Aivle Day 빙고 ( 주제 : 빅프 KSA )

빅프 때 필요한 KSA ( 지식, 기술, 태도 ) 키워드에 대해 조사를 하였고, 이를 주제로 빙고를 하였다. 나는 "냉철함"을 중요한 요소로 골랐고, 나와는 다른 생각을 하는 에이블러들의 생각을 들으니 흥미로웠다. 나는 비록 상품을 받지 못했지만, 재밌는 경험이었다. 각자 생각이 다른 부분이 있어서 빅프로젝트를 진행하는 동안 다툼없이 진행되려면 생각해야 할 부분이 많다고 느껴졌다.
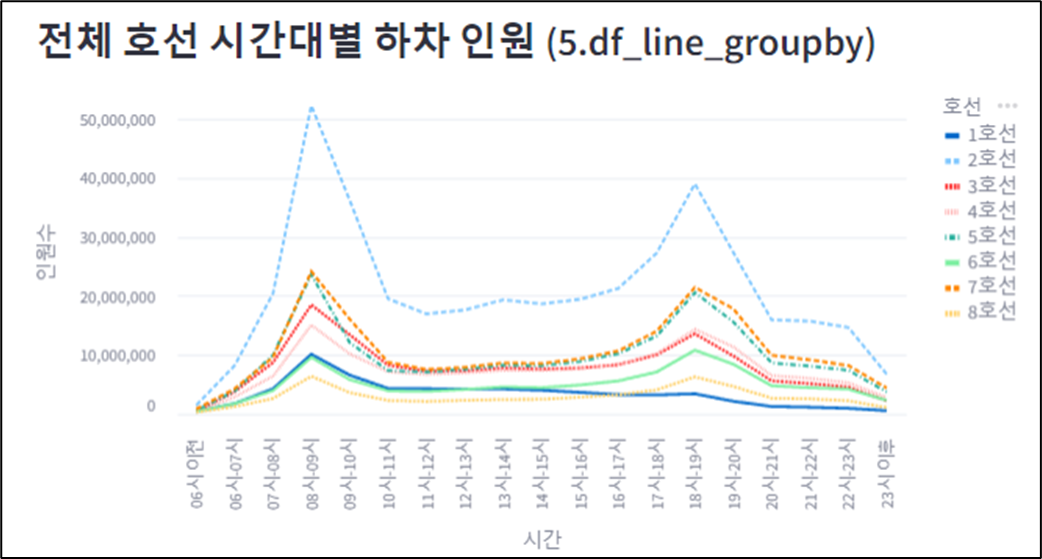
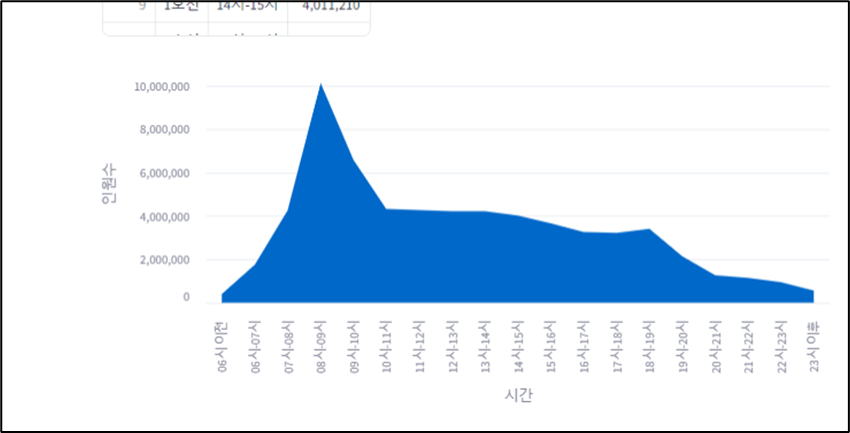
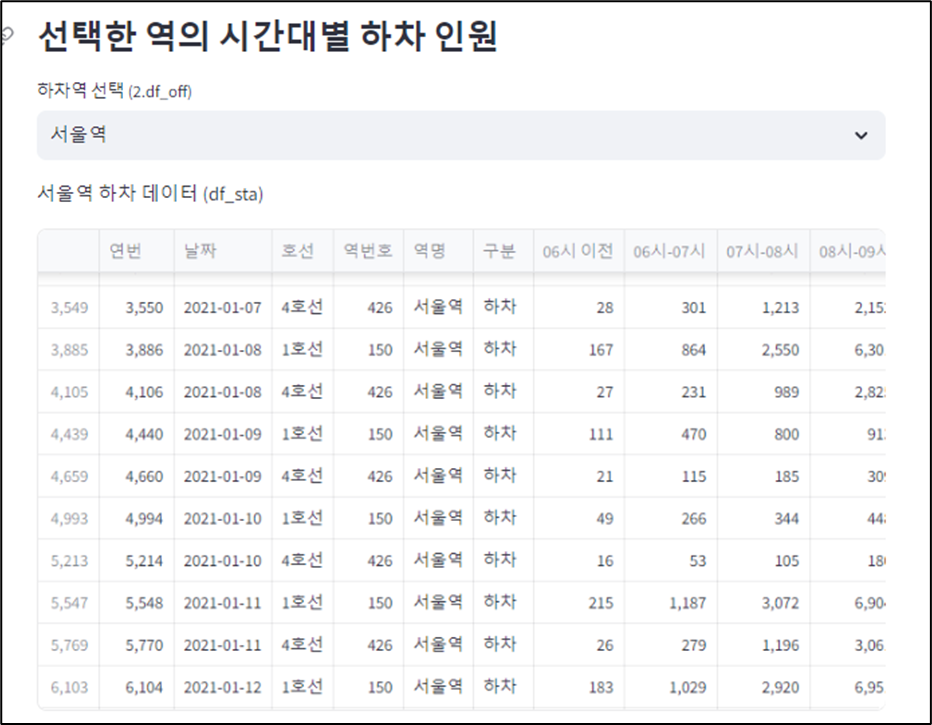
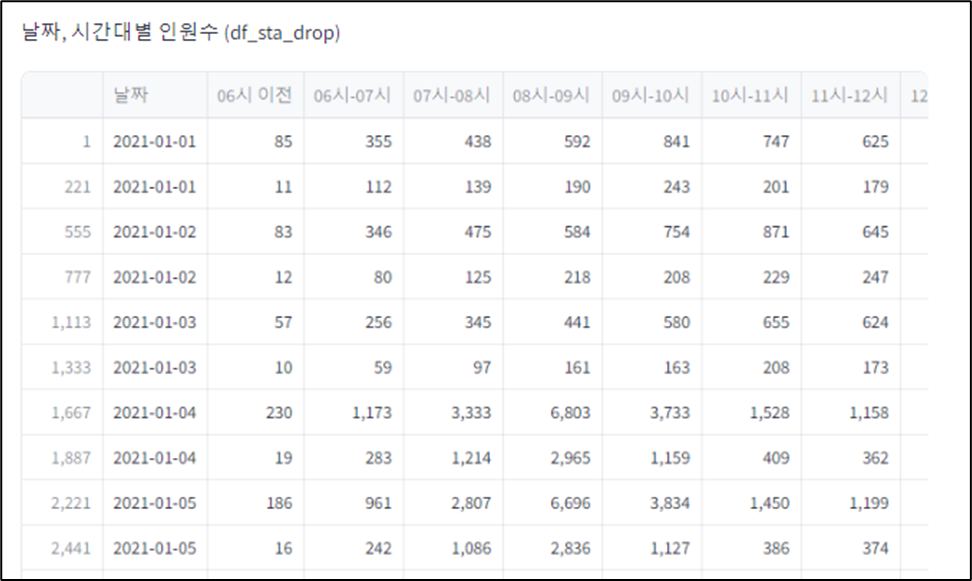
미니프로젝트 7차 - 제안전략 수립 및 제안서 작성

저번에 진행했던 6차 프로젝트의 주제를 이어서, 이번 미니 프로젝트에서는 구체적으로 고객사의 요구에 맞는 제안서를 작성해보는 시간을 가졌다. 6차 미니프로젝트와 같은 인원들로 구성되었고, 저번 미프에 이어서 조장 역할을 수행했다. 개인적으로 이번 미니 프로젝트에서는 발표를 굉장히 많이 시켜서 조장으로서 지치는 부분이 있었다. 목요일에는 휴가를 사용하여 하루 편하게 쉬었는데, 이번 미니 프로젝트에서 조장으로서 너무 힘들었기에 휴가가 더욱 만족스럽게 느껴졌다.
'Aivle School 4기 > 기자단 주별' 카테고리의 다른 글
| KT Aivle School 에이블스쿨 기자단] 12.18(월)~ 12.24(일) 빅프 진행, 산출물 제출, 컨설팅 진행 (0) | 2023.12.30 |
|---|---|
| KT Aivle School 에이블스쿨 기자단] 12.11(월)~ 12.17(일) 빅프 시작, 개인과제 공유, 조별 코칭 (0) | 2023.12.13 |
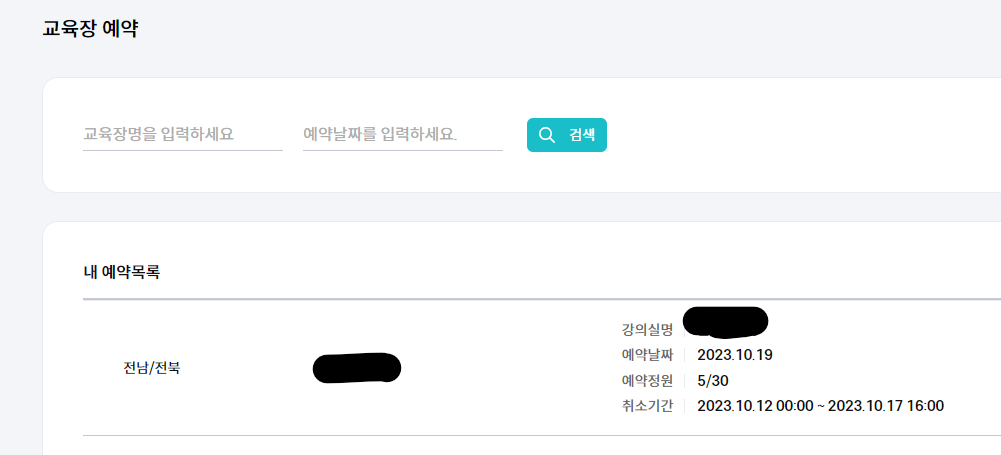
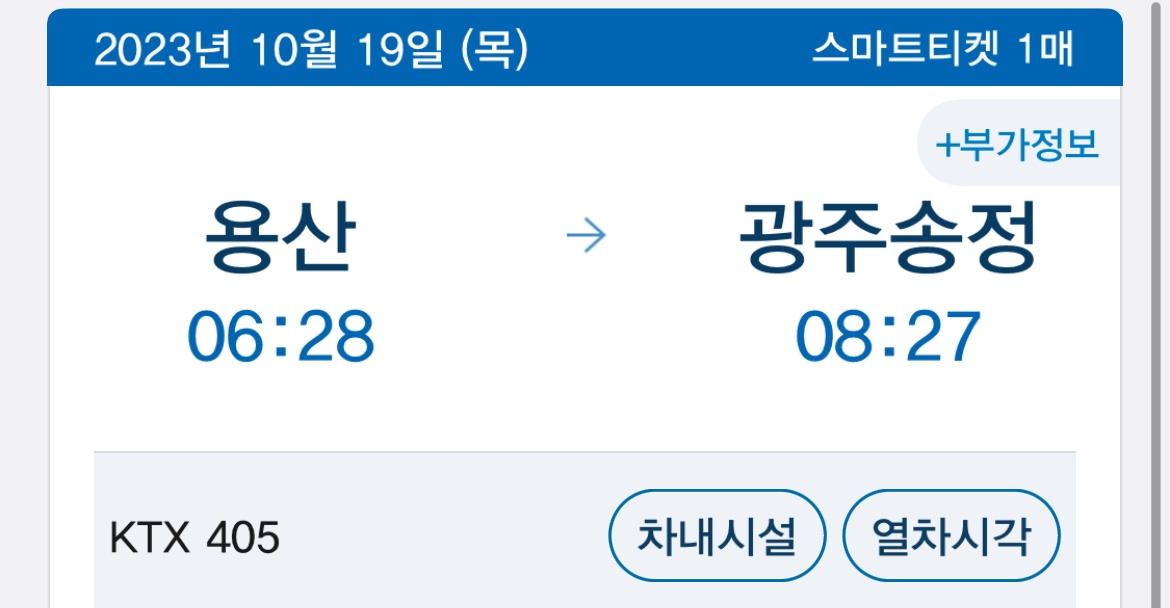
| KT Aivle School 에이블스쿨 기자단] 11.27(월)~ 12.03(일) "제안전략 수립, 제안서 작성, 대면 예약" (0) | 2023.12.05 |
| KT Aivle School 에이블스쿨 기자단] 11.20(월)~ 11.26(일) 미프 6차, 기획서 (2) | 2023.11.26 |
| KT Aivle School 에이블스쿨 기자단] 5기 모집 (0) | 2023.11.18 |