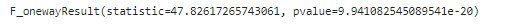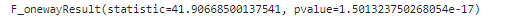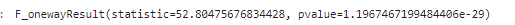- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
ㆍ 카이제곱 검정
- 귀무가설 : 두 집단의 빈도 분포가 독립적이다.
- p-value < 0.05 : 귀무 가설 기각, 두 집단의 빈도 분포가 독립적이지 않을 것이다.
ㆍANOVA
- 귀무가설 : 집단(세 개 이상)의 평균 간에 차이가 없을 것이다.
- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
(1) Gender
plt.figure(figsize = (15,8))
sns.barplot(x='Gender', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
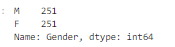
## 범주 데이터 확인 : value_counts()
base_data['Gender'].value_counts()
## 평균 분석 : ttest_indt_male = base_data.loc[base_data['Gender']=='M', 'Score_diff_total']
t_female = base_data.loc[base_data['Gender']=='F', 'Score_diff_total']
spst.ttest_ind(t_male, t_female)
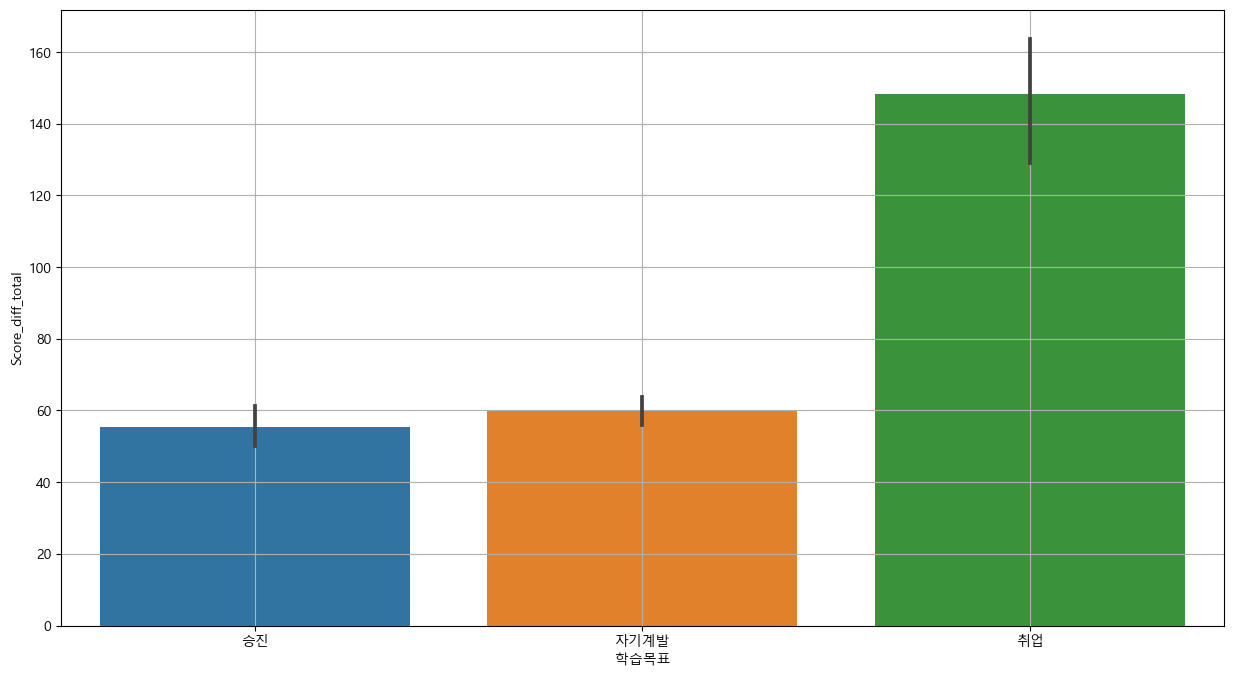
3-2-2) 학습목표
# 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습목표', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습목표'].value_counts()
## 분산 분석 : f_onewayanova_1 = base_data.loc[base_data['학습목표']=='승진', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습목표']=='자기계발', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습목표']=='취업', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
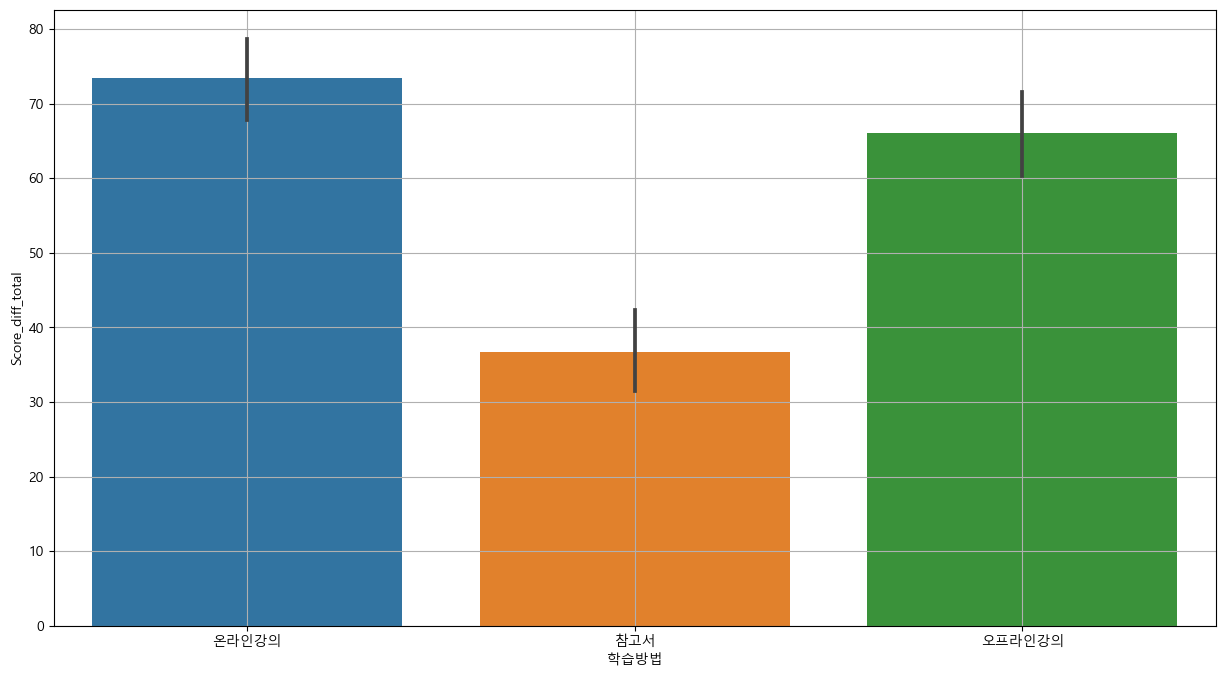
3-2-3) 학습방법
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습방법', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습방법'].value_counts()
## 분산 분석 : f_onewayanova_1 = base_data.loc[base_data['학습방법']=='온라인강의', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습방법']=='오프라인강의', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습방법']=='참고서', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
3-2-4) 강의 학습 교재 유형
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='강의 학습 교재 유형', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['강의 학습 교재 유형'].value_counts()
## 분산 분석 : f_onewayanova_1 = base_data.loc[base_data['강의 학습 교재 유형']=='일반적인 영어 텍스트 기반 교재', 'Score_diff_total']
anova_2 = base_data.loc[base_data['강의 학습 교재 유형']=='영상 교재', 'Score_diff_total']
anova_3 = base_data.loc[base_data['강의 학습 교재 유형']=='뉴스/이슈 기반 교재', 'Score_diff_total']
anova_4 = base_data.loc[base_data['강의 학습 교재 유형']=='비즈니스 시뮬레이션(Role Play)', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3, anova_4)
3-2-6) 취약분야 인지 여부
## 그래프 분석 : barplot
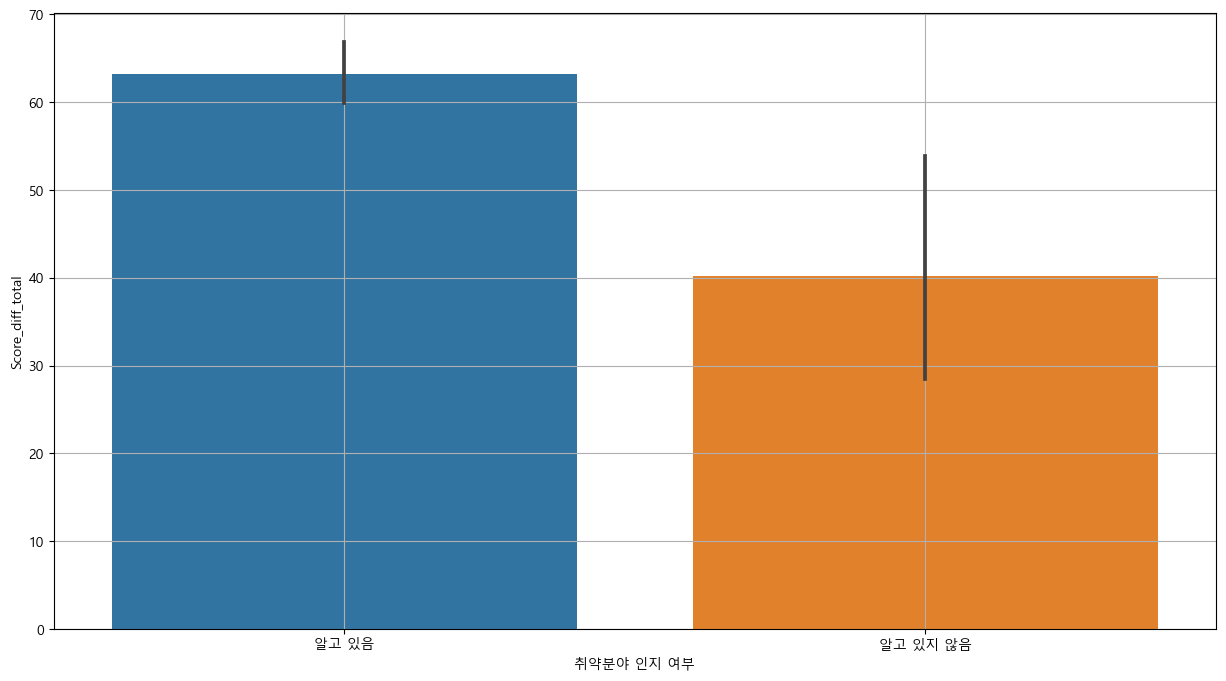
plt.figure(figsize = (15,8))
sns.barplot(x='취약분야 인지 여부', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['취약분야 인지 여부'].value_counts()
## 평균 분석 : ttest_indt_yes = base_data.loc[base_data['취약분야 인지 여부']=='알고 있음', 'Score_diff_total']
t_no = base_data.loc[base_data['취약분야 인지 여부']=='알고 있지 않음', 'Score_diff_total']
spst.ttest_ind(t_yes, t_no)