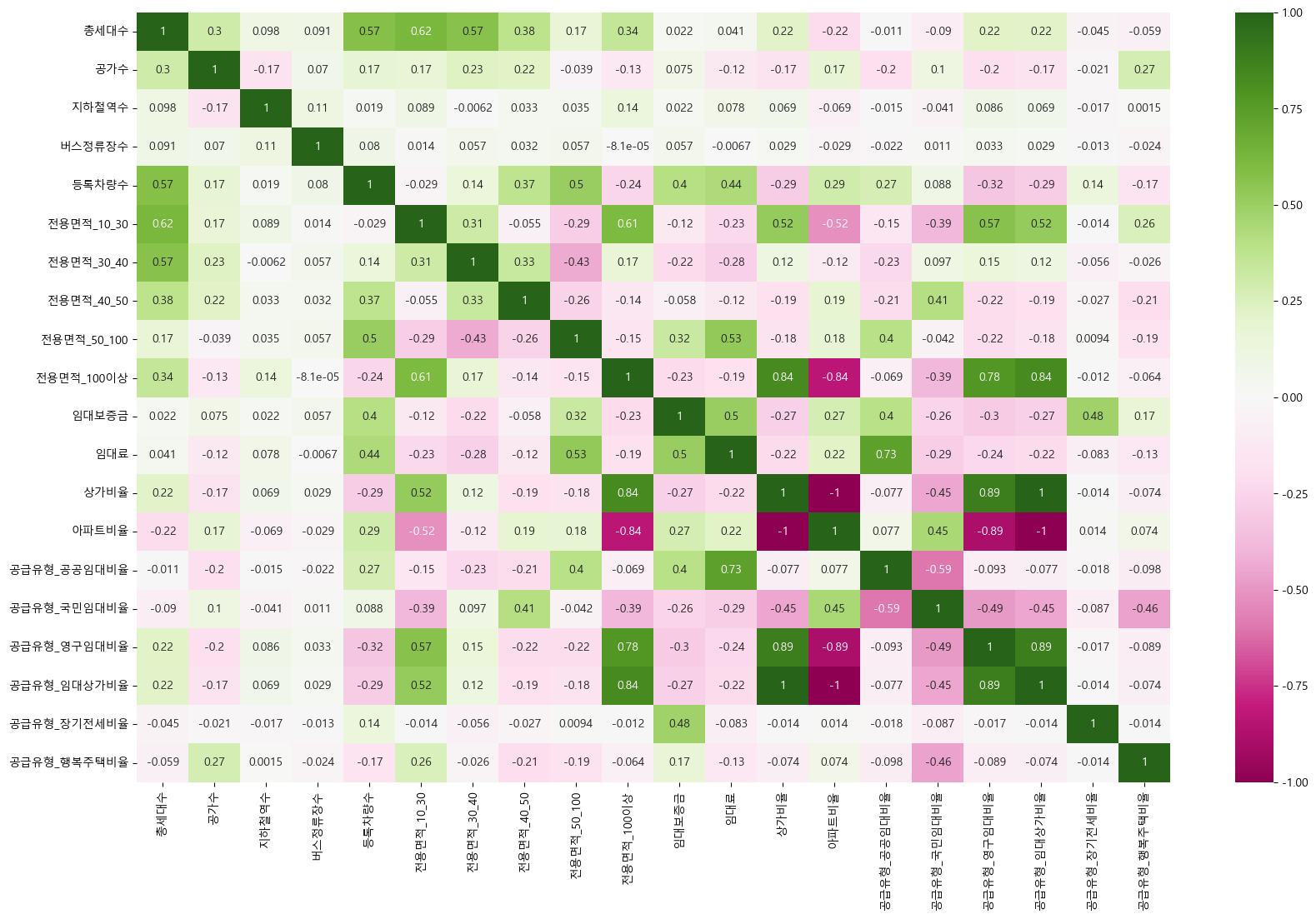
728x90
python 기법] 워드 클라우드
텍스트 전처리
ㆍ 파일 읽기, 내용 확인
# 파일 읽기
file = open('Dream.txt', 'r', encoding='UTF-8')
text = file.read()
file.close()
# 확인(100 글자만)
text[:100]
ㆍ split() 메소드를 이용하여 단어 단위로 잘라 리스트 형태로 만들기
# 공백을 구분자로 하여 단어 단위로 자르기
wordList = text.split()
# 확인(10 개만)
wordList[:10]
ㆍ 단어별 빈도수 계산하여 딕셔너리에 저장
# 중복 단어 제거
worduniq = set(wordList)
# 딕셔너리 선언
wordCount = {}
# 단어별 개수 저장
for w in worduniq:
wordCount[w] = wordList.count(w)
# 제외 대상 조사
del_word = ['the','a','is','are', 'not','of','on','that','this','and','be','to', 'from']
# 제외하기
for w in del_word:
if w in wordCount:
del wordCount[w]
워드 클라우드 그리기
# 패키지 설치
!pip install wordcloud
# 라이브러리 불러오기
import matplotlib.pyplot as plt
from wordcloud import WordCloud
%config InlineBackend.figure_format='retina'
# 워드 클라우드 만들기
wordcloud = WordCloud(font_path = 'C:/Windiws/fonts/HMKMRHD.TTF',
width=2000,
height=1000,
# colormap='Blues'
background_color='white').generate_from_frequencies(wordCount)
# 표시하기
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()
불필요한 단어나 조사 추가 제거
# 제외 대상 조사
del_word = ['for','But','into','So', 'which','by','as','With','am','was','when','who', 'an', 'has', 'in']
# 제외하기
for w in del_word:
if w in wordCount:
del wordCount[w]
워드 클라우드 그리기
# 워드 클라우드 만들기
wordcloud = WordCloud(font_path = 'C:/Windiws/fonts/HMKMRHD.TTF',
width=2000,
height=1000,
background_color='white').generate_from_frequencies(wordCount)
# 표시하기
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()728x90
'Python 기법' 카테고리의 다른 글
| python 기법] 파일 읽고 쓰기 mkdir, read, write, writelines, readlines, readline (1) | 2023.12.03 |
|---|---|
| python 기법] 이메일 (0) | 2023.11.29 |