728x90
내용
- PCA
- PCA 코드
- 주성분 누적 분산 그래프 elbow method
| PCA 사용하기 | ||
| * 선언 - 생성할 주성분의 개수 지정 - 원래 feature의 수만큼 지정할 수 있음 ( 일반적으로 feature 수 만큼 지정 ) - 생성 후 조정할 수 있음 |
* 적용 - x_train으로 fit & transform - 다른 데이터는 적용 - 결과는 numpy array |
* 코드 # 라이브러리 from sklearn.decomposition import PCA # 주성분 분석 선언 pca = PCA(n_components=n) # 만들고, 적용 x_train_pc = pca.fit_transform(x_train) x_val_pc = pca.transform(x_val) |
| 코드 |
| 1. 데이터 준비 (1) 라이브러리 로딩 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns from sklean.model_selection import train_test_split (2) 스케일링 scaler = MinMaxScaler() x = scaler.fit_transform(x) (3) 데이터 분할 x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = .3, random = 20) 2. 차원 축소 : 주성분 PCA (1) 주성분 만들기 from sklearn.decomposition import PCA (2) 주성분 분석 수행 # 주성분을 몇 개로 할지 결정( 최대값 : 전체 feature 수) n = x_train.shape[1] # 주성분 분석 선언 pca = PCA(n_components = n) # 만들고 적용 x_train_pc = pca.fit_transform(x_train) x_val_pc = pca.transform(x_val) (3) 결과는 numpy array로 주어지므로 데이터 프레임으로 변환 # 컬럼 이름 생성 column_names = ['PC' + str(i+1) for i in range(n) ] # 데이터프레임으로 변환 x_train_pc = pd.DataFrame(x_train_pc, columns = column_names ) x_val_pc = pd.DataFrame(x_val_pc, columns = column_names |
| 연습 # 주성분 1개짜리 pca1 = PCA(n_components = 1) x_pc1 = pca1.fit_transform(x_train) # 주성분 2개짜리 pca2 = PCA(n_components = 2) x_pc2 = pca2.fit_transform(x_train) # 주성분 3개짜리 pca3 = PCA(n_components = 3) x_pc3 = pca3.fit_transform(x_train) |
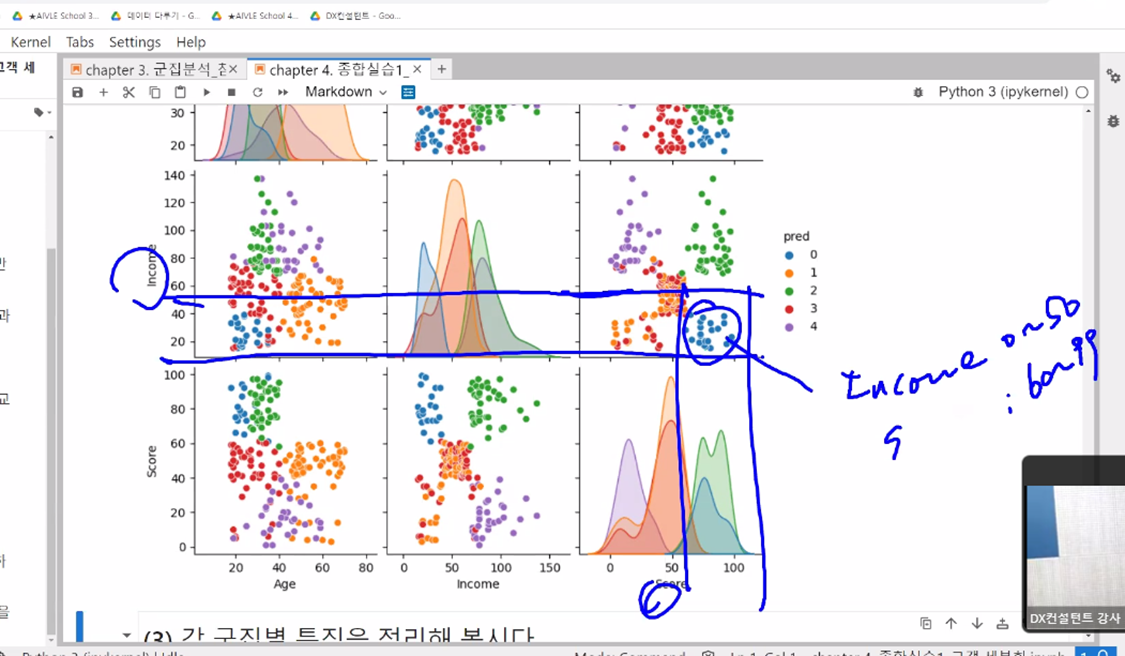
| 주성분 누적 분산 그래프 - 그래프를 보고 적절한 주성분의 개수를 지정(elbow method) - x축 : PC 수 - y축 : 전체 분산크기 - 누적분산크기 |
|
 |
# 코드 plt.plot( range(1, n+1), pca.explained_variance_ratio_, marker = '.') plt.xlabel('No. of PC') |

728x90
'데이터 - 머신러닝 비지도 학습' 카테고리의 다른 글
| 비지도 학습] "k-means 미프 실습" (0) | 2023.09.26 |
|---|---|
| 비지도 학습] k-means (0) | 2023.09.20 |