728x90
KT Aivle School 에이블스쿨 중간점검] 데이터전처리, 불필요한 부분 제거, 결측치 대체, 중앙값, 최빈값
진행단계
- 먼저 필요한 라이브러리들을 불러오자 - 데이터 전처리, 시각화
- 데이터를 불러오고 데이터를 확인하자
- 불필요한 부분을 제거하자
- 데이터 결측치를 처리하자 - 최빈값으로 대체하자
- 데이터 결측치를 처리하자 - 중앙값으로 대체하자
먼저 필요한 라이브러리들을 불러오자 - 데이터 전처리, 시각화
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
데이터를 불러오고 데이터를 확인하자
df = pd.read_csv('voc_data.csv') # csv 파일을 읽어오자
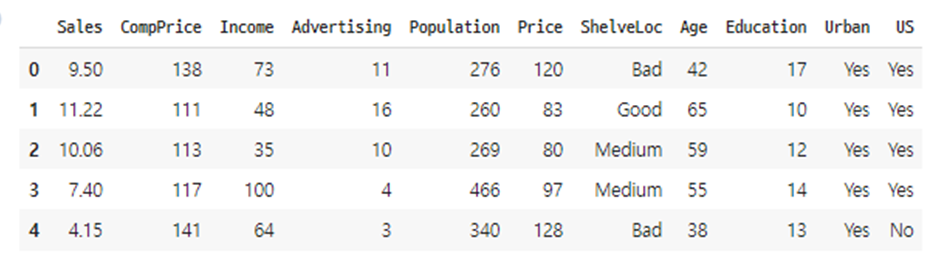
df.head() # 앞부분 5줄을 출력하자
df.tail() # 뒷부분 5줄을 출력하자
df.info() # 데이터의 정보를 종합적으로 확인하자
df.info()
df.index() # 데이터프레임의 인덱스 확인
df.columns # 데이터프레임 컬럼을 확인
df.values # 데이터프레임 값을 확인
df['voc_trt_perd_itg_cd'].value_counts() # voc_trt_perd_itg_cd 컬럼 데이터별 건수를 나열
df['voc_trt_perd_itg_cd'].value_counts(normalize = True)
# voc_trt_perd_itg_cd 컬럼 데이터별 건수 비율 보기
불필요한 부분을 제거하자
df1 = df.drop(columns=['voc_trt_perd_itg_cd', 'voc_trt_reslt_itg_cd', 'oos_cause_type_itg_cd', 'engt_cperd_type_itg_cd',
'engt_tgt_div_itg_cd', 'fclt_oos_yn'], axis=1)
# 불필요한 컬럼 삭제
# DataFrame drop() 함수 사용
# 컬럼 삭제한 결과를 "df1" 데이터프레임에 저장한다.
# 다중 컬럼 삭제
df1.drop(columns = ['voc_mis_pbls_yn'], inplace = True) # 단일 컬럼 삭제
df.drop(columns = ['new_date','opn_nfl_chg_date', 'cont_fns_pam_date'], inplace =True)
# 다중 컬럼 삭제
데이터 결측치를 처리하자 - 최빈값으로 대체하자
df1.replace('_', np.nan, inplace = True) # 모든 컬럼에 대하여 '_' 값을 null로 변경한다.
df1.isnull().sum() # 변경이 잘 되었는지 확인한다.
df1['cust_class_itg_cd'].value_counts() # 최빈값을 찾자
df1['cust_class_itg_cd'].fillna('L', inplace = True) # 최빈값 'L'로 결측치를 대체하자
df1['cust_class_itg_cd'].isnull().sum() # 잘 대체되었는지 Null 값을 확인하자
df1.info()
데이터 결측치를 처리하자 - 중앙값으로 대체하자
df1['age_itg_cd'].median() # 중앙값을 확인하자
df1['age_itg_cd'].replace(np.nan, 위에서 계산한 중앙값, inplace = True)
# 위에서 나온 중앙값으로 Null 값을 대체하자.
df1['age_itg_cd'].dtypes # 데이터 타입을 확인하자
df1['age_itg_cd'] = df1['age_itg_cd'].astype(int) # 값을 정수형으로 변환하자
df1['age_itg_cd'].isnull().sum() # Null 값 개수를 확인하자
df1.info() # age_itg_cd가 "int32" 타입인지 확인하자728x90
'Aivle School 4기 > Aivle School 중간점검' 카테고리의 다른 글
| KT Aivle School 에이블스쿨 중간점검] 딥러닝_DNN (0) | 2023.10.31 |
|---|---|
| KT Aivle School 에이블스쿨 중간점검] 머신러닝 RandomForestClassifier (0) | 2023.10.26 |