DX 의 중요성
나이키와 포드를 예시로 성공적인 DX를 이루어내는 데에 중요한 요인을 배울 수 있었다.
나이키는 고객 중심으로 서비스를 기획하며 코로나 시기에도 높은 실적을 기록했다.
포드는 기술 성장을 위해 많은 돈을 들여 다양한 스타트업을 인수하고 "포드 스마트 모빌리티"를 설립했다.
하지만, 각 사업부가 독립적으로 일이 진행되면서 기술과 업무가 통합되지 않았고다. 이에 따라 포드 스마트 모빌리티는 기계의 변속기 이상, 안정성 등의 문제가 반복되는 모습을 보여주었다.
클라우드 이론 및 AWS 경험
수업 때 클라우드 이론을 배운 뒤, AWS를 통해 실습을 진행하며 VPC, Subnet, 인터넷 게이트웨이, 보안그룹 등을 다루어 보니 클라우드 개념에 대한 이해도를 높이는 데에 도움이 되었다.
수업에서 받은 계정은 금요일 수업 종료와 동시에 삭제되어 아쉬움이 있었고, AWS 홈페이지를 뒤져보며 무료로 연습을 해볼 방법이 있는지 알아보고 있다.
돌아오는 주에는 6차 미니 프로젝트 진행
돌아오는 주 3일 동안은 미니 프로젝트를 진행하게되었다.
현재까지 미프를 진행해온 결과, 여러 번 같은 조가 된 에이블러들을 볼 수 있었다.
현재 우리 조 상황은 조원들이 온다면 수요일에 많이 올 것으로 예상되고, 나도 상황을 보면서 대면 교육장을 갈지 결정하려고 한다.

SQL 스터디원 모집
회사 채용 공고들을 보면서 느낀 결과, SQL은 많은 직무에서 우대 받을 수 있는 역량임을 볼 수 있었고, DX 과정에서는 SQL 수업을 따로 진행하지 않기 때문에 이를 꾸준히 공부하고자 직접 스터디원들을 모집했다.
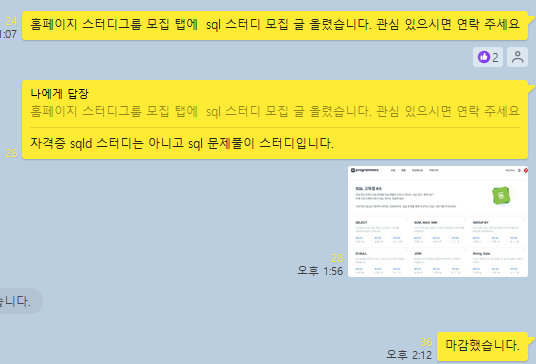
하고 싶은 일이 생겼을 때는 망설이지 않는 스타일이기에 바로 KT 에이블러들 단체 카톡방에 말을 했고, DX 에이블러 스터티그룹원 모집 게시판에도 글을 올렸다.
이 부분에 비슷한 고민이 있는 사람들이 있어서였는지 생각보다 빠르게 스터디원들을 구하고 마감할 수 있었다.

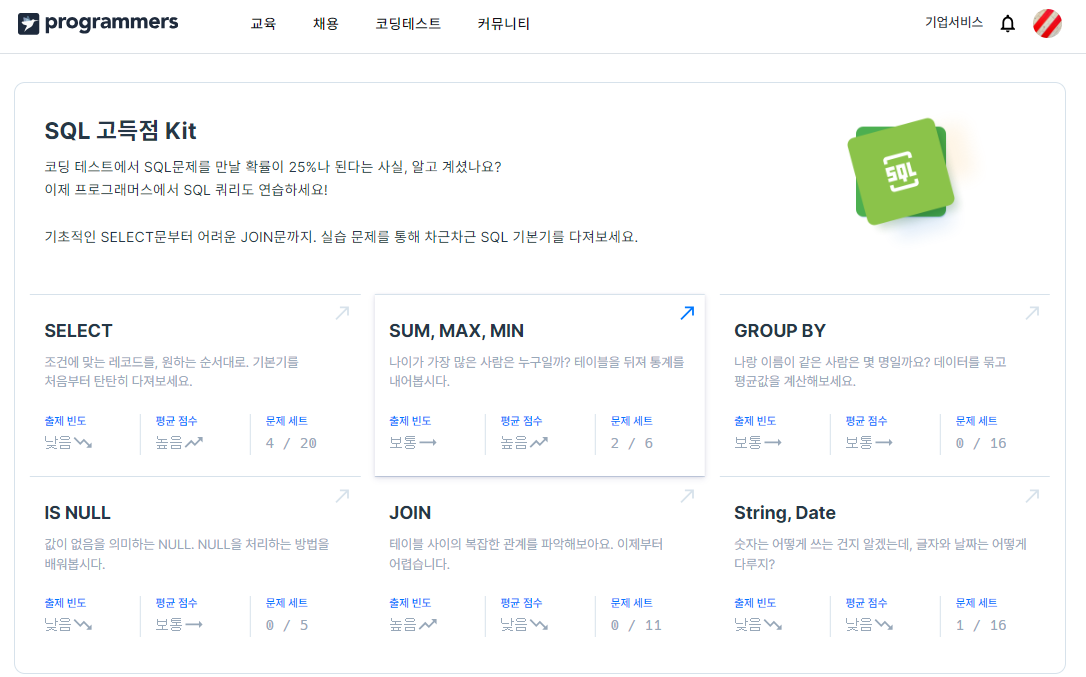
스터디에서 활용할 프로그래머스 SQL 고득점 Kit
'Aivle School 4기 > 기자단 주별' 카테고리의 다른 글
| KT Aivle School 에이블스쿨 기자단] 11.20(월)~ 11.26(일) 미프 6차, 기획서 (2) | 2023.11.26 |
|---|---|
| KT Aivle School 에이블스쿨 기자단] 5기 모집 (0) | 2023.11.18 |
| KT Aivle School 에이블스쿨 기자단] 11.06(월)~ 11.12(일) Virtual Box, Cacoo (0) | 2023.11.06 |
| KT Aivle School 에이블스쿨 기자단] 10.30(월)~ 11.05(일) 미프, 에이블데이, 기자단 발표 (0) | 2023.11.01 |
| KT Aivle School 에이블스쿨 기자단] 10.23(월) ~ 10.29(일) streamlit, 상담 메일 (0) | 2023.10.23 |