[메타코드 강의 후기] SQL과 Python 연결하고 데이터분석 실습 - "데이터분석 마무리"
SQL과 Python 연결하고 데이터분석 실습 - [ 데이터 전처리 / 시각화 ]
www.metacodes.co.kr
안녕하세요 메타코드 5기 서포터즈 송주영입니다
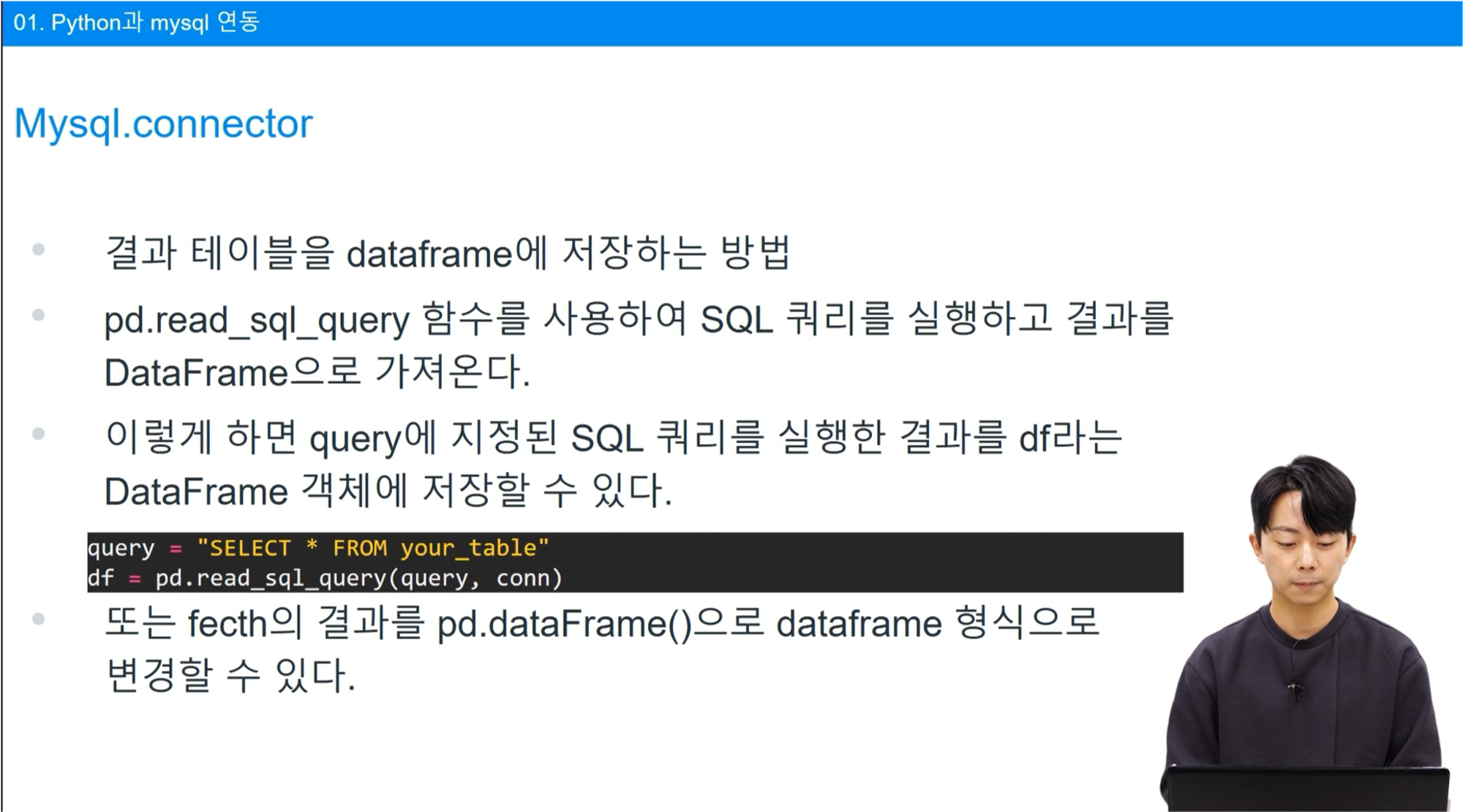
저번 강의을 들으며, Python과 SQL 질의문을 둘 다 공부할 수 있어서 유용한 수업이라고 느껴졌습니다
특히 인사이트를 뽑아내는 과정을 알려주셔서 데이터를 바라보는 능력을 키울 수 있었다고 생각했어요
이 강의에서 배운 내용들을 잘 정리해두고 참고하며 새로운 데이터를 마주하게 되었을 때 의미있는 분석을 하고자 합니다
"SQL과 Python 연결하고 데이터분석 실습" 수업 리뷰 진행하겠습니다.
수량과 금액으로 나누어 제품 판매 분석

제품 판매를 분석함에 있어서는 판매 수량, 판매 금액을 모두 확인할 필요가 있습니다.
좌측은 판매수량에 대한 시각화 정보이고, 우측은 판매 금액에 대한 시각화 정보입니다.
페라리를 보면 판매수량도 많고, 판매 금액 또한 높은 모습을 보입니다.
Lincoln을 확인해보면 판매 수량에서는 높은 비중을 차지하였으나, 판매 금액에서는 높은 비중을 나타내지는 않습니다.
지역별 매출 비교
지역에 따라 총 매출액과 평균 매출액의 차이가 어떠한지 시각화하였습니다.
총 매출액에서는 미국이 압도적으로 높은 위치를 차지하였으나, 평균 매출에서는 가장 높은 비중을 차지하지는 않습니다.
그래프를 보면 홍콩은 총 매출이 가장 적은 모습을 보입니다.
따라서, 홍콩에서의 매출을 높이기 위해서는 어떠한 요소들이 필요할 지 알아볼 필요가 있습니다.
전략 수립
위의 결과를 살펴보았을 때, 매출이 높은 국가와 매우 낮은 국가를 대상으로 어떤 전략을 취해야 하는 지 나누어 볼 필요가 있습니다.
하나의 국가에 지나치게 의존도가 높다면 그 국가의 상황에 따라 회사의 매출이 좌우될 위험이 존재합니다.
매출이 낮은 국가에게서 매출액을 높일 수 있다면 이러한 위험성을 분산시킬 수 있을 것입니다.
해당 국가의 문화적 특성, 시장 특성들을 고려하여 마케팅 전략을 수립한다면 보다 다양한 국가에게서 높은 매출을 기록할 수 있을 것입니다.
제품 카테고리별 분석
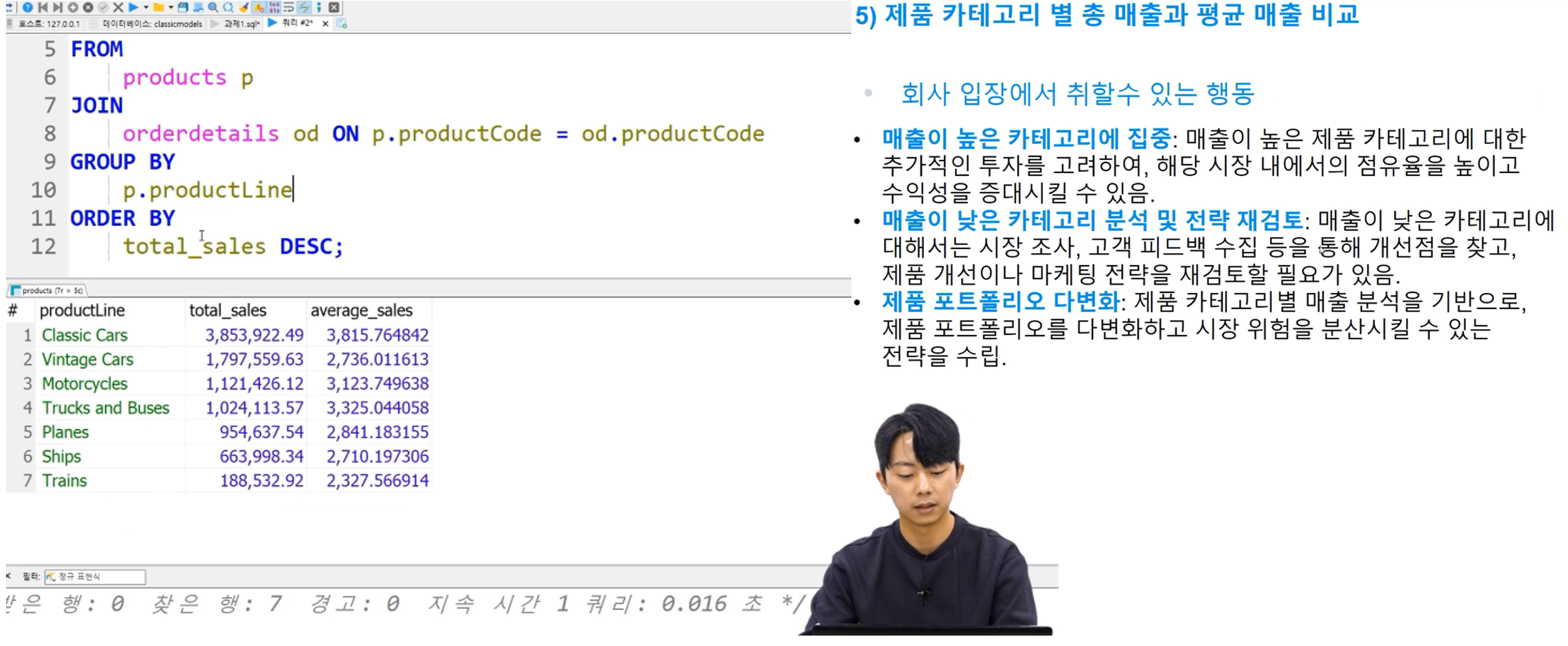
제품 카테고리별로 분석을 진행하였습니다.
총 매출과 평균 매출을 비교하였고, 총 매출이 높다고 해서 반드시 평균 매출이 높지는 않음을 확인했습니다.
카테고리에 대해서는 매출이 높은 경우와 낮은 경우로 나누어서 전략을 수립합니다.
매출이 높은 카테고리에 대해서 꾸준히 높은 매출을 얻을 수 있도록 하며, 매출이 낮은 카테고리의 매출을 늘려 보다 위험성을 분산시킬 수 있도록 합니다.
제품군의 연도별 매출 분석
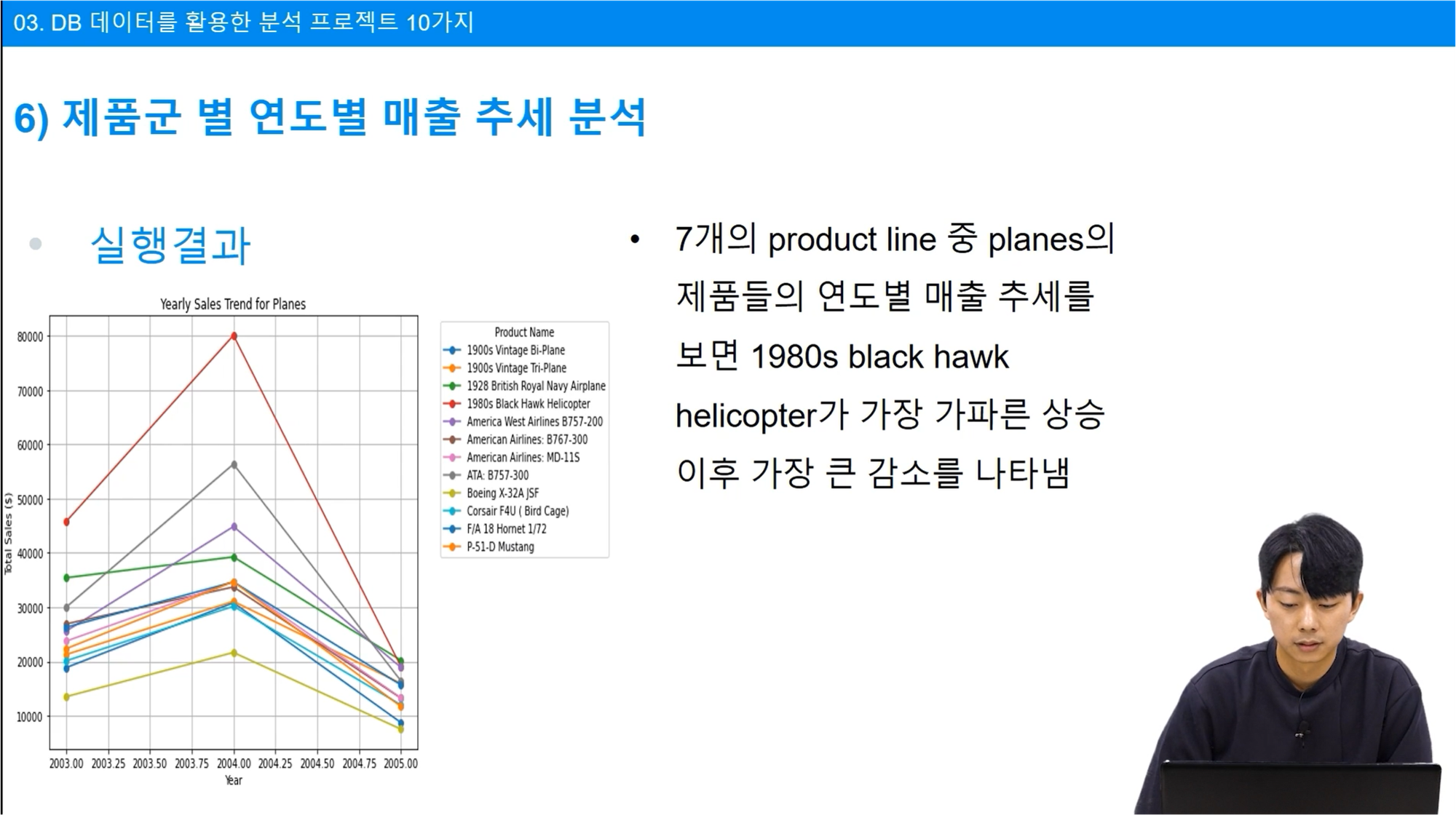
제품별 매출을 연도별로 구분하여 분석하였습니다.
이러한 시각화 정보를 통해 매출액의 절대적 수치도 확인할 수 있지만, 이들의 변화가 어떤지 또한 확인할 수 있습니다.
전년대비 큰 상승을 기록하는 제품들도 존재하고, 상대적으로 변동폭이 적은 제품들도 존재합니다.
급격하게 증가한 경우, 급격하게 감소한 경우가 주요 분석 대상이 될 수 있습니다.
분석에 따른 전략 수립

연도별 매출 분석 결과의 예시입니다.
매출이 증가하는 제품에 대해서는 추가 마케팅 자원 투입, 생산 확대를 고려할 수 있고 매출이 감소하는 추세를 보인다면 고 시장 조사, 고객 피드백 수집이 필요할 것입니다.
연도별 분석을 진행하며 특정 시기마다 수요가 증가하는 제품이 있다면 이를 분석하여 새로운 시장을 발굴할 수 있도록 합니다.
재고 관리의 최적화를 위해서 또한 제품들의 매출이 증가하는지 감소하는지를 면밀하게 확인해야 합니다.
이상으로 "SQL과 Python 연결하고 데이터분석" 강의 마무리하도록 하겠습니다.
짧은 시간 동안 핵심 내용들을 잘 짚어준 강의라 몰입감 있게 수업을 들을 수 있었습니다.
강의 수강생들을 대상으로 강의자료, 코드 파일을 주셔서 실제 프로젝트에 활용해보려 합니다.
글 읽어주셔서 감사합니다!!
'SQL_Python_메타코드' 카테고리의 다른 글
| [메타코드 강의 후기] SQL과 Python 연결하고 데이터분석 실습 - "Python과 MySQL 연결, 데이터베이스 생성, 데이터분석(1)" (0) | 2024.07.06 |
|---|