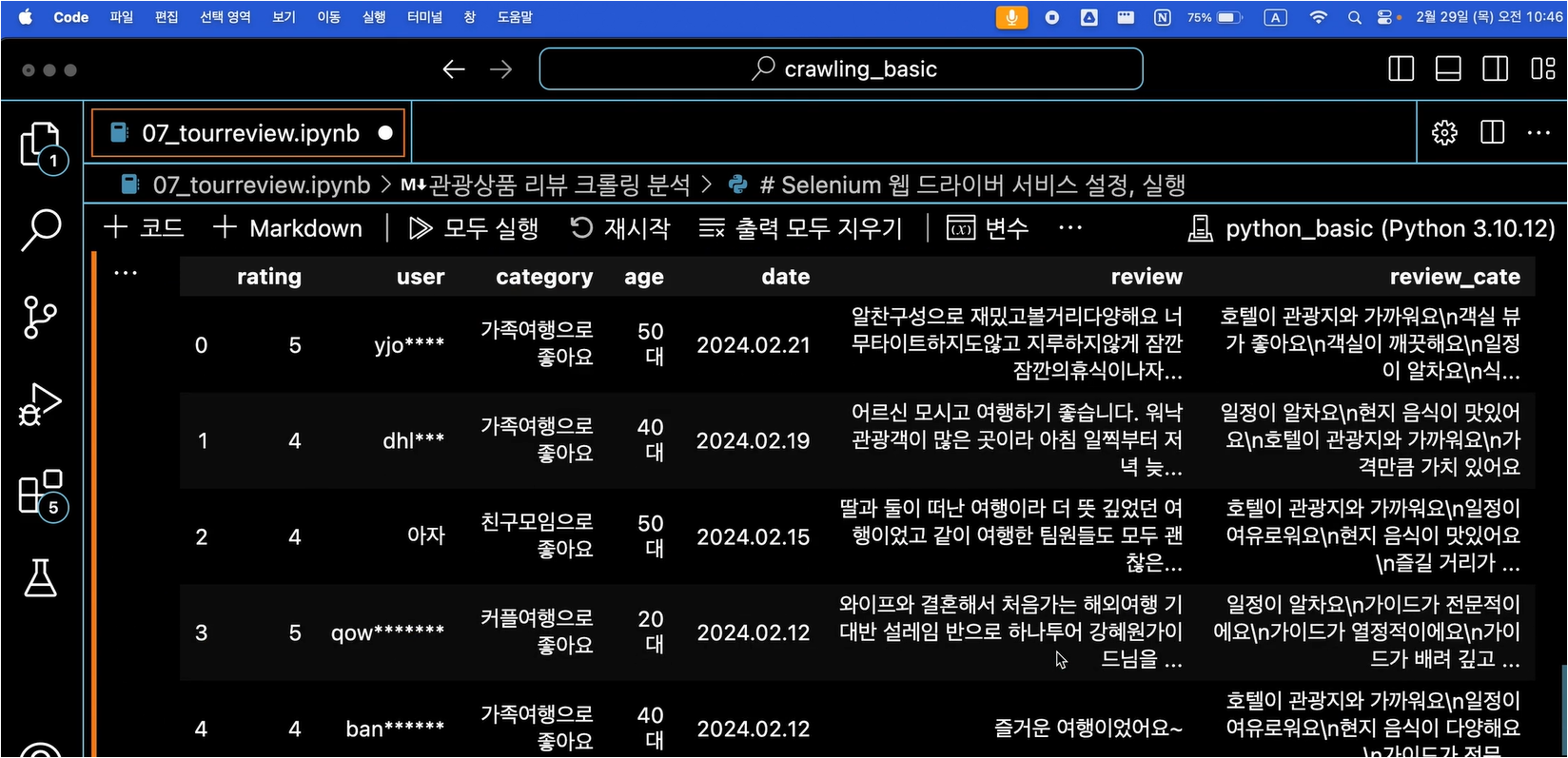
BeautifulSoup, selenium, ChromeDriverManager, WebdriverWait 라이브러리 등을 불러옵니다.
from bs4 import BeautifulSoup
import pandas as pd
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
아래 코드를 통하여, Selenium 웹 드라이버를 실행하는 과정을 수행합니다.
# Selenium 웹 드라이버 실행
driver = webdriver.Chrome(service = service)
driver.get(url)
wait = WebDriverWait(driver, 10)
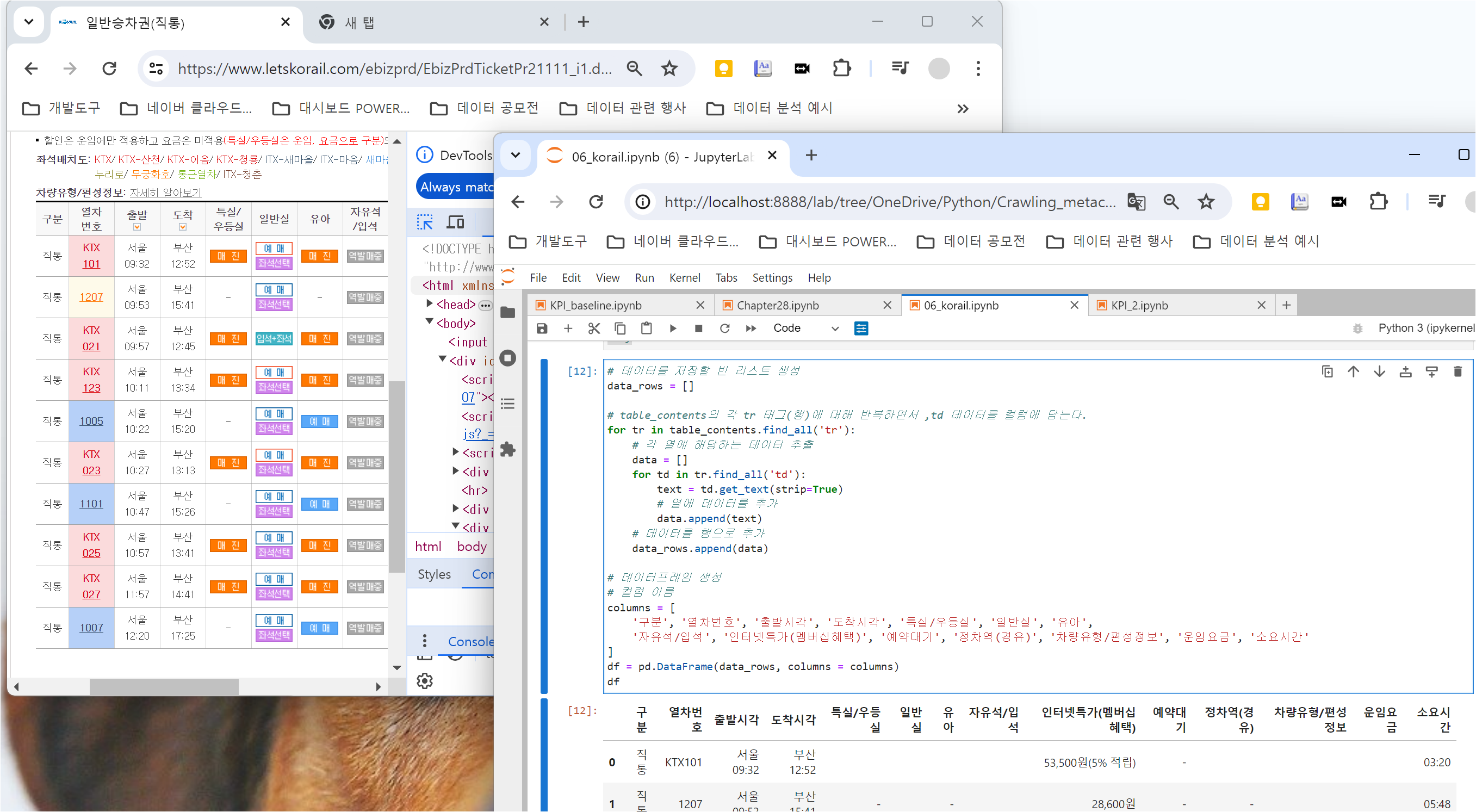
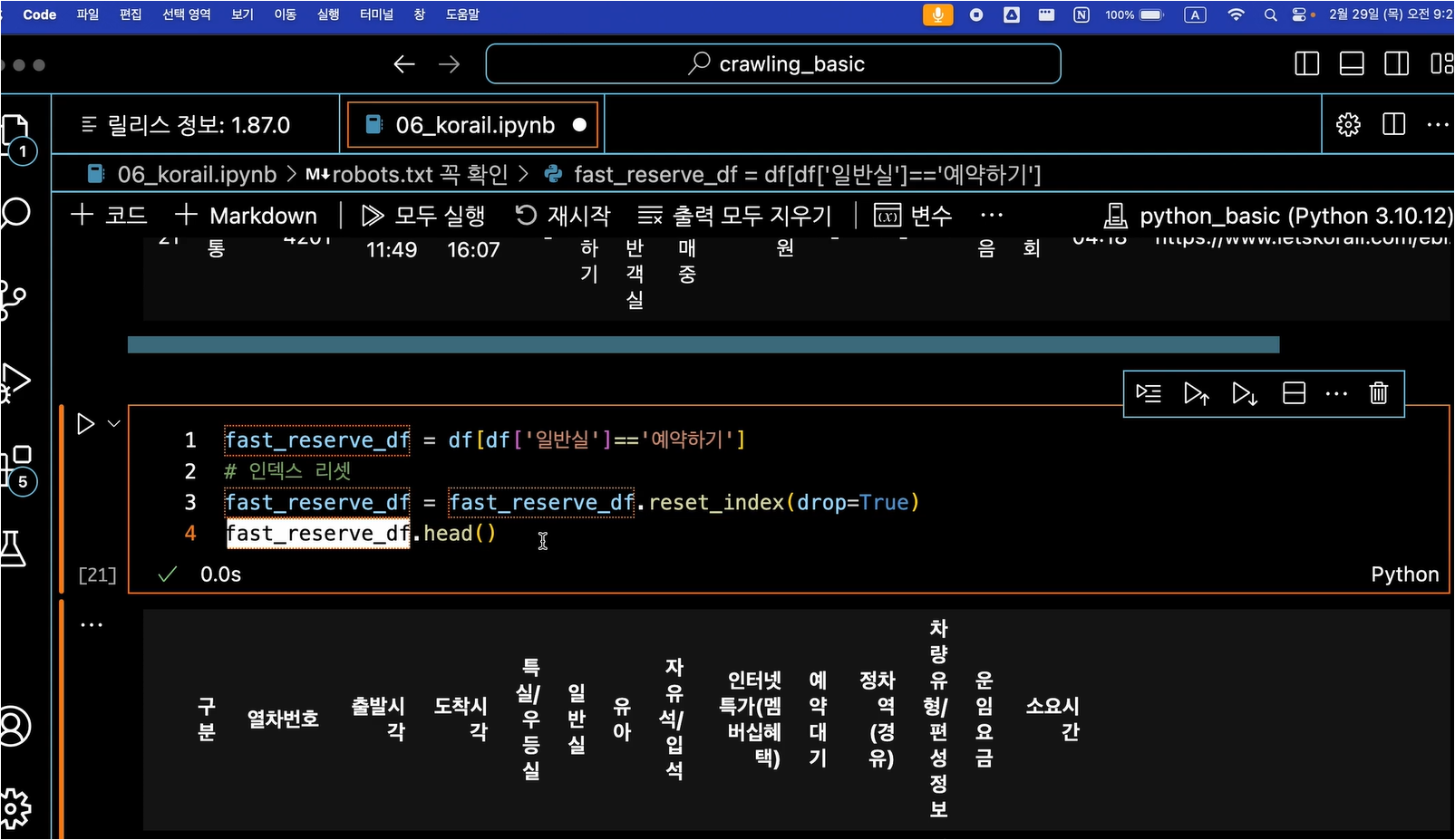
테이블 정보를 담는 데이터프레임을 생성합니다.
리스트 구조를 활용하여 for문을 돌면서 각 tr의 td 데이터를 담는 데이터프레임을 생성합니다.
아래와 같이 tr 안의 td에 들어있는 값들을 하나씩 리스트에 추가하는 코드를 작성합니다.
# 데이터를 저장할 빈 리스트 생성
data_rows = []
# table_contents의 각 tr 태그(행)에 대해 반복하면서 ,td 데이터를 컬럼에 담는다.for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# 데이터를 행으로 추가
data_rows.append(data)
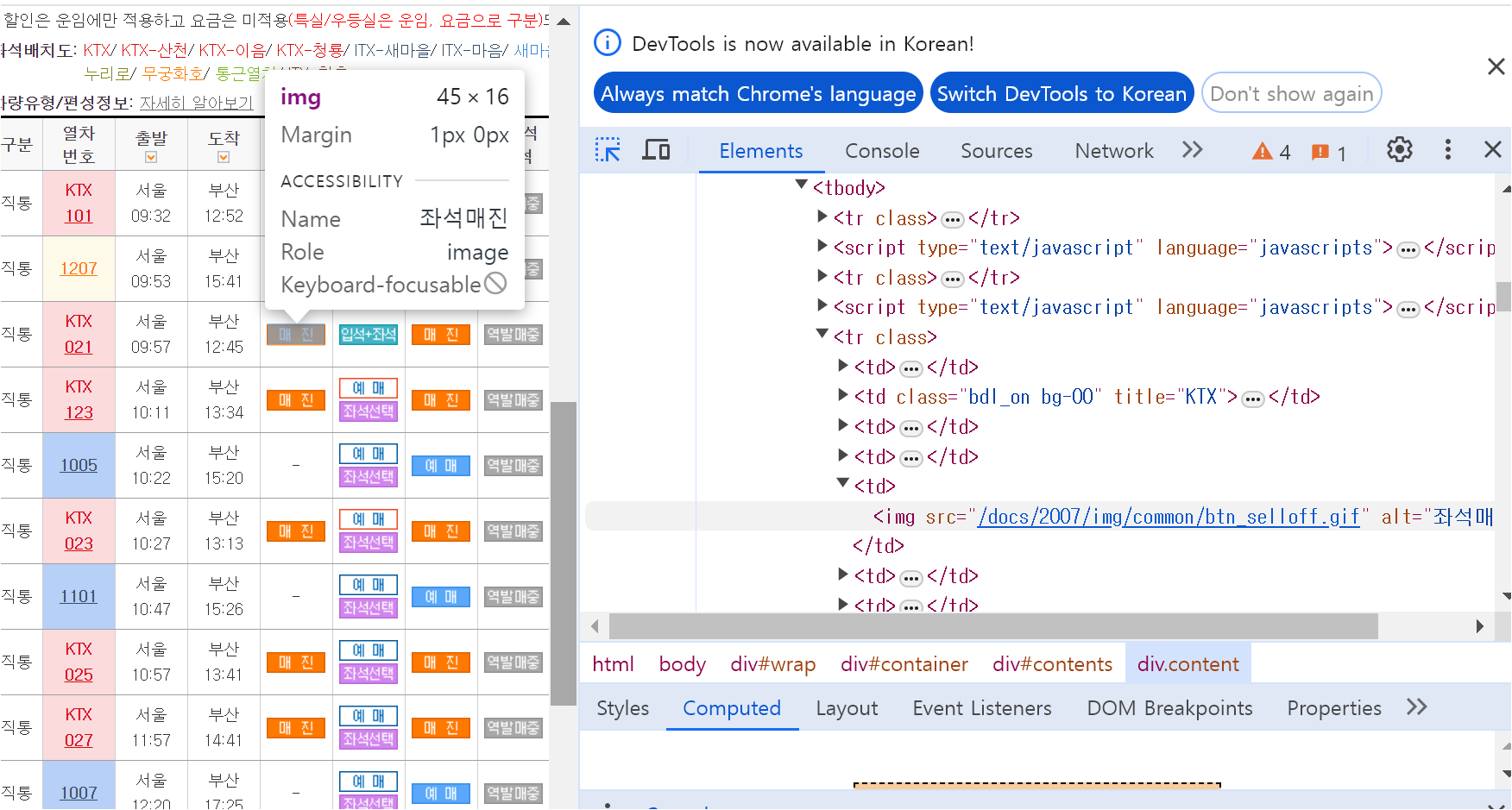
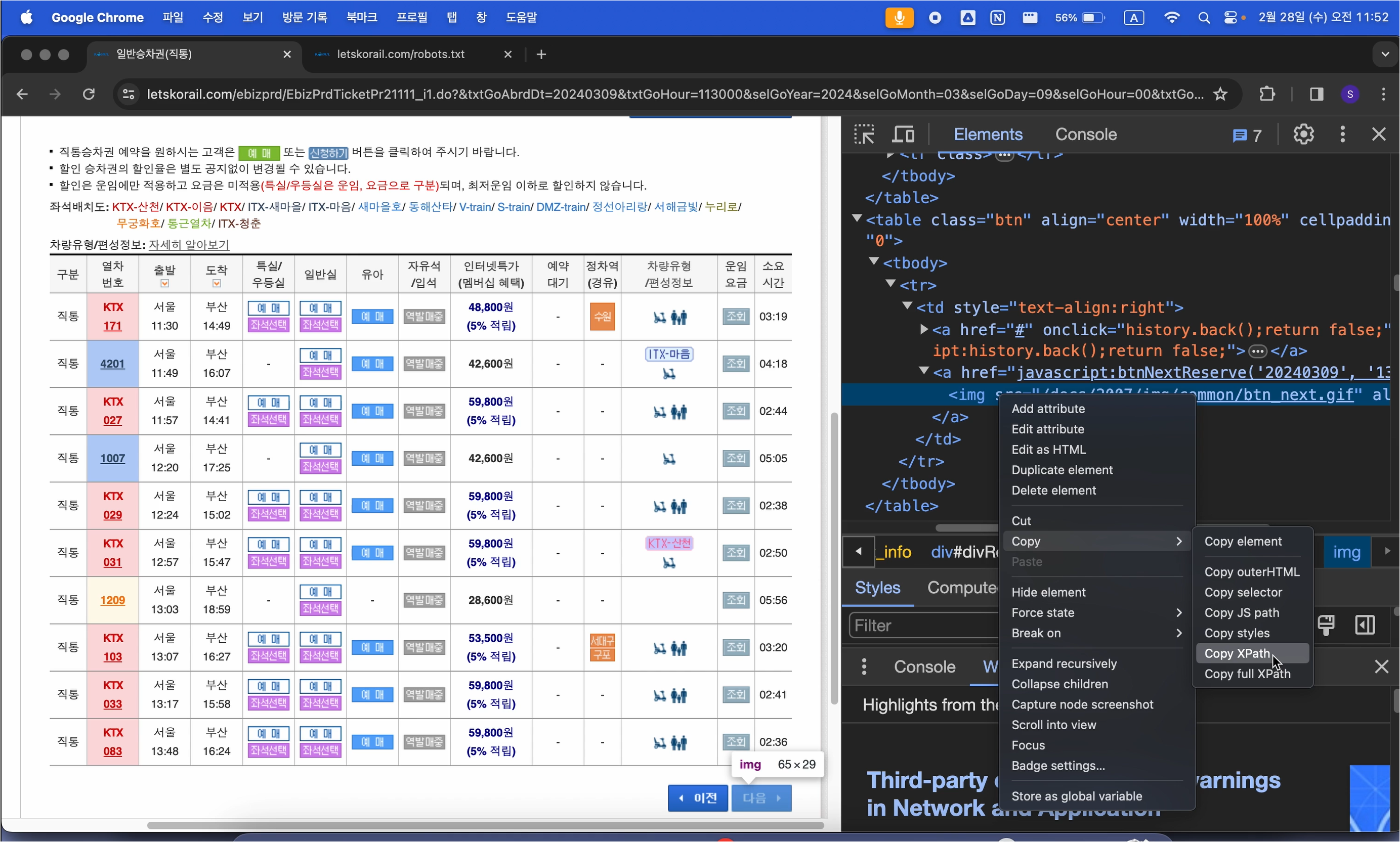
위에서와 마찬가지로 for문 구조를 작성하는데, 이번에는 td.find('img') 코드를 추가하여,
위에서 만든 데이터프레임에 빈 칸이 생기는 경우가 없도록 할 것입니다.
# table_contents의 각 tr 태그(행)에 대해 반복하면서, td 데이터를 컬럼에 담아준다.for tr in table_contents.find_all('tr'):
# 각 열에 해당하는 데이터 추출
data = []
for td in tr.find_all('td'):
# td 안에 있는 im 태그가 있는지 확인, alt 속성 추출
img_tag = td.find('img')
# img_tag가 존재하면if img_tag:
text = img_tag.get("alt", "")
else:
text = td.get_text(strip=True)
# 열에 데이터를 추가
data.append(text)
# data, 즉 방금까지 td 태그들이 쌓인 data 리스트에 url도 하나 더 추가
data.append(url)
# 데이터를 행으로 추가
data_rows.append(data)
"if img_tag" 조건문을 추가하고 img 태그가 있는 경우에는 "img_tag.get("alt", "")" 과정이 수행되도록 합니다.
그 외의 경우에는 위에서 진행한 대로 "td.get_text(strip=True)" 과정이 진행되도록 합니다.
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.mime.base import MIMEBase
from email import encoders
파일
defsend_email(subject, body, recipient, files):
sender = '메일@메일.com'
password = '앱 비밀번호'
server = smtplib.SMTP('smtp.gmail.com', 587)
server.starttls()
server.login(sender, password)
message = MIMEMultipart()
message['From'] = sender
message['To'] = recipient
message['Subject'] = subject
message.attach(MIMEText(body, 'plain'))
for file in files: # files의 항목들을 연다.
attachment = open(file, 'rb')
part = MIMEBase('application', 'octet-stream') # MIMEBase 타입을 설정한다. 'application', 'octet-stream' 이것은 일반적인 바이너리 파일을 나타내는 MIME, 다양한 유형의 파일 첨부 가능
part.set_payload((attachment).read())
encoders.encode_base64(part) # ASCII 문자열로 변환하여 이메일을 통한 전송 중에 데이터가 손상되지 않도록 한다.
part.add_header('Content-Disposition', "attachment; filename= %s" % file)
message.attach(part)
# 이메일 발송
server.send_message(message)
server.quit()
함수 사용
if st.button('Sending email'): # streamlit 전송 버튼
send_email(
subject = '제목',
body = 'Check This File',
recipient = '메일@메일.com',
files = ['./under.csv', './over.csv']
)
st.write('Complete')
from datetime import datetime
from datetime import timedelta
import pandas as pd
import requests
import pprint
from os import name
import pandas as pd
import bs4
response = requests.get(url, params=params)
# xml 내용
content = response.text
print('content',content)
# 깔끔한 출력 위한 코드
pp = pprint.PrettyPrinter(indent=4)
print('pp', pp)
### xml을 DataFrame으로 변환하기 ###from os import name
import pandas as pd
import bs4
#bs4 사용하여 item 태그 분리
xml_obj = bs4.BeautifulSoup(content,'lxml-xml')
print('xml_obj', xml_obj)
rows = xml_obj.findAll('item')
print(rows)
# 각 행의 컬럼, 이름, 값을 가지는 리스트 만들기
row_list = [] # 행값
name_list = [] # 열이름값
value_list = [] #데이터값# xml 안의 데이터 수집for i inrange(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집for j inrange(0,len(columns)):
if i ==0:
# 컬럼 이름 값 저장
name_list.append(columns[j].name)
# 컬럼의 각 데이터 값 저장
value_list.append(columns[j].text)
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]
#xml값 DataFrame으로 만들기
water_df = pd.DataFrame(row_list, columns=name_list)
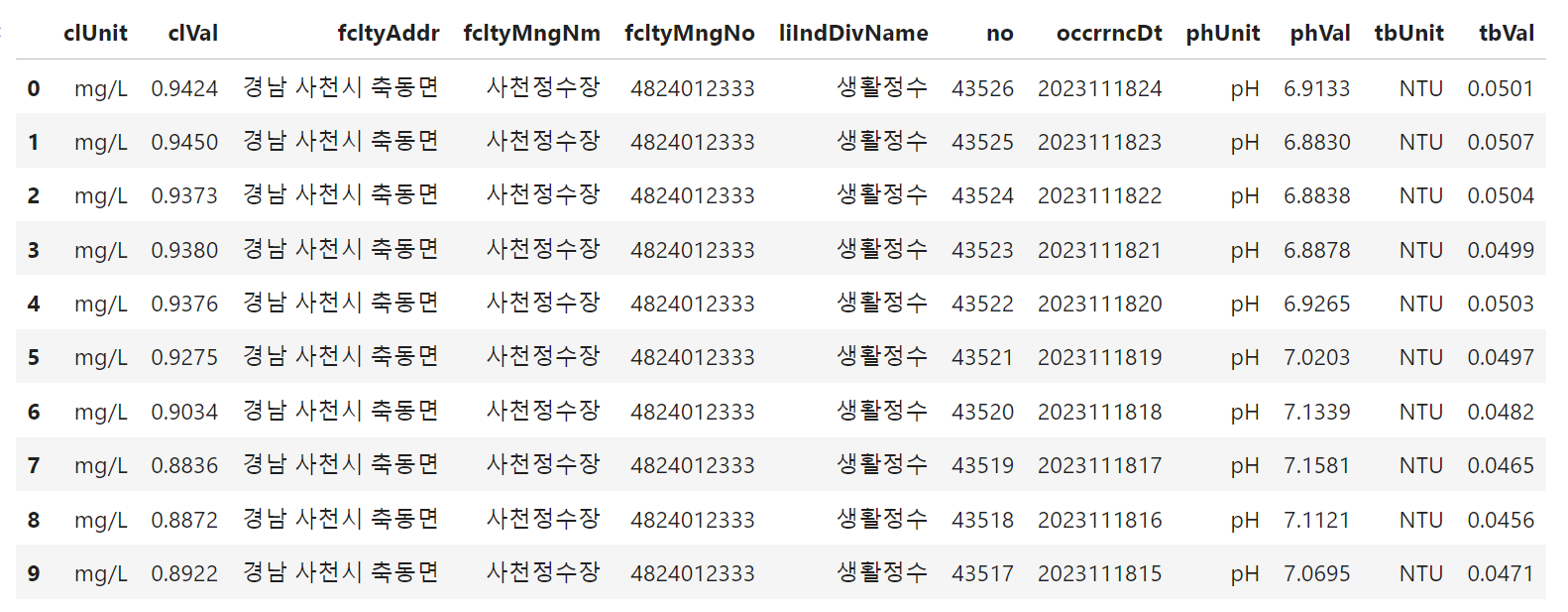
print(water_df.head(19))
#xml값 DataFrame으로 만들기#Assertion Error가 난 경우
water_df = pd.DataFrame(water_df)
# 이후에 컬럼을 설정해 주세요.
water_df