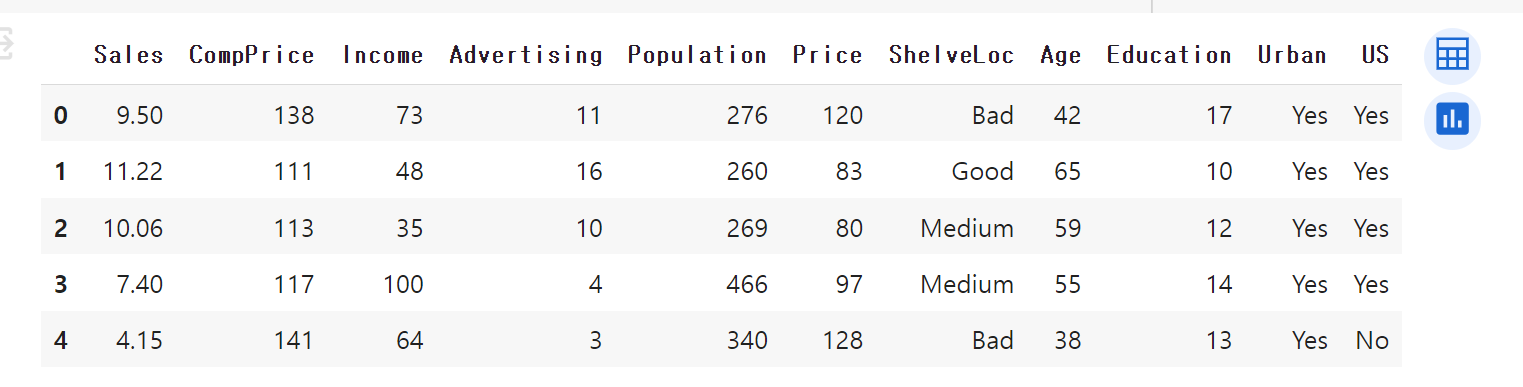
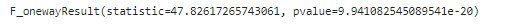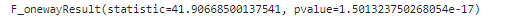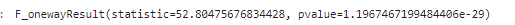SELECT FOOD_TYPE, MAX(FAVORITES) AS MaxFavorites
FROM REST_INFO
GROUP BY FOOD_TYPE
(1) FROM REST_INFO
(2) GROUP BY FOOD_TYPE
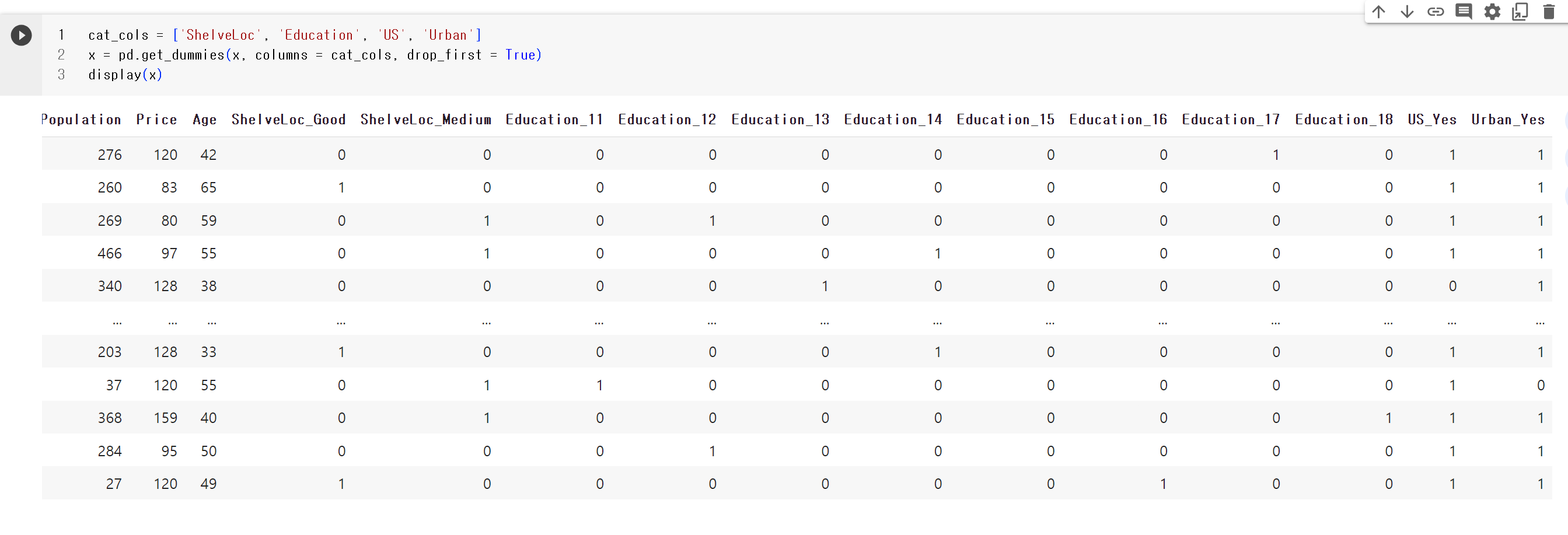
2] 기존 테이블과 INNER JOIN
-- 코드를 입력하세요
SELECT r.FOOD_TYPE, r.REST_ID, r.REST_NAME, r.FAVORITES
FROM REST_INFO r
INNER JOIN(
SELECT FOOD_TYPE, MAX(FAVORITES) AS MaxFavorites
FROM REST_INFO
GROUP BY FOOD_TYPE
) AS max_res ON r.FOOD_TYPE = max_res.FOOD_TYPE
AND r.FAVORITES = max_res.MaxFavorites
ORDER BY r.FOOD_TYPE DESC;
# 홈 디렉토리 확인
from pathlib import Path
print(Path.home())
# 작업 디렉토리 확인
from pathlib import Path
print(Path.cwd())
# 디렉토리 내용 확인
from pathlib import Path
files = Path.cwd().glob('*')
for f in files:
print(f)
기본적인 파일 읽고 쓰기
파일 쓰기
# 파일 열기
f = open('MyFile.txt', 'w')
# 파일 쓰기
f.write('안녕하세요?\n')
# 파일 닫기
f.close()
디렉토리 만들기
# 디렉토리 만들기
Path('Files').mkdir(exist_ok=True)
파일 열기, 쓰기, 닫기
# 파일 열기
f = open('Files/MyFile.txt', 'w')
# 파일 쓰기
f.write('모두들 안녕하세요?\n')
# 파일 닫기
f.close()
파일 읽기
# 파일 열기
f = open('MyFile.txt', 'r')
# 내용 읽기
print(f.read())
# 파일 닫기
f.close()
경로 지정해서 읽기
# 파일 열기
f = open('Files/MyFile.txt', 'r')
# 내용 읽기
print(f.read())
# 파일 닫기
f.close()
파일 내용 추가
# 파일 열기
f = open('MyFile.txt', 'a')
# 내용 추가
f.write('만나서 반갑습니다!')
# 파일 닫기
f.close()
x 모드, 같은 파일이 있으면 오류 발생
# 파일 열기
f = open('MyFile.txt', 'x')
# 내용 쓰기
f.write('만나서 반갑습니다!')
# 파일 닫기
f.close()
# 오류 핸들링
try:
f = open('MyFile.txt', 'x')
f.write('만나서 반갑습니다!')
f.close()
except FileExistsError: # 이미 파일이 있으면
print('같은 이름의 파일이 있습니다.')
else: # 그렇지 않으면
print('파일 쓰기 성공했습니다.')
finally: # 마무리
print('수고하셨습니다.')
파일 다루기 실습
python 파일 만들기
# 파일 열기
f = open('Python.txt', 'w')
내용 입력
# 내용 쓰기
f.write('''<파이썬과 나>
시인: 홍길동''')
# 파일 닫기
f.close()
내용 추가
# 파일 열기
f = open('Python.txt', 'a')
# 내용 추가
f.write('''
어느날
파이썬이 나에게 왔다.
많이 낯설었다.
지금은 나와 하나가 되었다.
파이썬이 나고,
내가 파이썬이다.''')
# 파일 닫기
f.close()
ㆍ f = open('Python.txt', 'a')에서 'a'는 파일을 "추가 모드(append mode)"로 열기 위한 파일 모드
writelines()
# 파일 여러 줄 쓰기
hello = ['안녕하세요?\n', '만나서 반갑습니다!\n', '우리 사이좋게 잘 지내요.\n']
f = open('MyFile.txt', 'w')
f.writelines(hello)
f.close()
내용 확인
# 파일 읽기
f = open('MyFile.txt', 'r')
print(f.read())
f.close()
readlines()
# 파일 한 번에 읽기
f = open('MyFile.txt', 'r')
result = f.readlines()
f.close()
# 내용 확인
print(result)
# 반복문으로 한 행씩 표시
for txt in result:
print(txt, end='')
readline()
ㆍ 행 단위로 읽기
# 파일 읽기
f = open('MyFile.txt', 'r')
# 내용 읽기
print(f.readline(), end='')
print(f.readline(), end='')
print(f.readline(), end='')
# 파일 닫기
f.close()
ㆍ 반복문을 이용해 모든 행 읽기
# 파일 읽기
f = open('MyFile.txt', 'r')
result = f.readline()
# 반복문으로 한 행씩 읽어 표시
while result:
print(result, end='')
result = f.readline()
# 파일 닫기
f.close()
# 파일 읽기
file = open('Dream.txt', 'r', encoding='UTF-8')
text = file.read()
file.close()
# 확인(100 글자만)
text[:100]
ㆍ split() 메소드를 이용하여 단어 단위로 잘라 리스트 형태로 만들기
# 공백을 구분자로 하여 단어 단위로 자르기
wordList = text.split()
# 확인(10 개만)
wordList[:10]
ㆍ 단어별 빈도수 계산하여 딕셔너리에 저장
# 중복 단어 제거
worduniq = set(wordList)
# 딕셔너리 선언
wordCount = {}
# 단어별 개수 저장
for w in worduniq:
wordCount[w] = wordList.count(w)
# 제외 대상 조사
del_word = ['the','a','is','are', 'not','of','on','that','this','and','be','to', 'from']
# 제외하기
for w in del_word:
if w in wordCount:
del wordCount[w]
워드 클라우드 그리기
# 패키지 설치
!pip install wordcloud
# 라이브러리 불러오기
import matplotlib.pyplot as plt
from wordcloud import WordCloud
%config InlineBackend.figure_format='retina'
# 워드 클라우드 만들기
wordcloud = WordCloud(font_path = 'C:/Windiws/fonts/HMKMRHD.TTF',
width=2000,
height=1000,
# colormap='Blues'
background_color='white').generate_from_frequencies(wordCount)
# 표시하기
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()
불필요한 단어나 조사 추가 제거
# 제외 대상 조사
del_word = ['for','But','into','So', 'which','by','as','With','am','was','when','who', 'an', 'has', 'in']
# 제외하기
for w in del_word:
if w in wordCount:
del wordCount[w]
워드 클라우드 그리기
# 워드 클라우드 만들기
wordcloud = WordCloud(font_path = 'C:/Windiws/fonts/HMKMRHD.TTF',
width=2000,
height=1000,
background_color='white').generate_from_frequencies(wordCount)
# 표시하기
plt.figure(figsize=(12, 6))
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout(pad=0)
plt.show()
- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
ㆍ 카이제곱 검정
- 귀무가설 : 두 집단의 빈도 분포가 독립적이다.
- p-value < 0.05 : 귀무 가설 기각, 두 집단의 빈도 분포가 독립적이지 않을 것이다.
ㆍANOVA
- 귀무가설 : 집단(세 개 이상)의 평균 간에 차이가 없을 것이다.
- p-value < 0.05 : 귀무 가설 기각, 집단 간의 평균에 유의미한 차이가 있다.
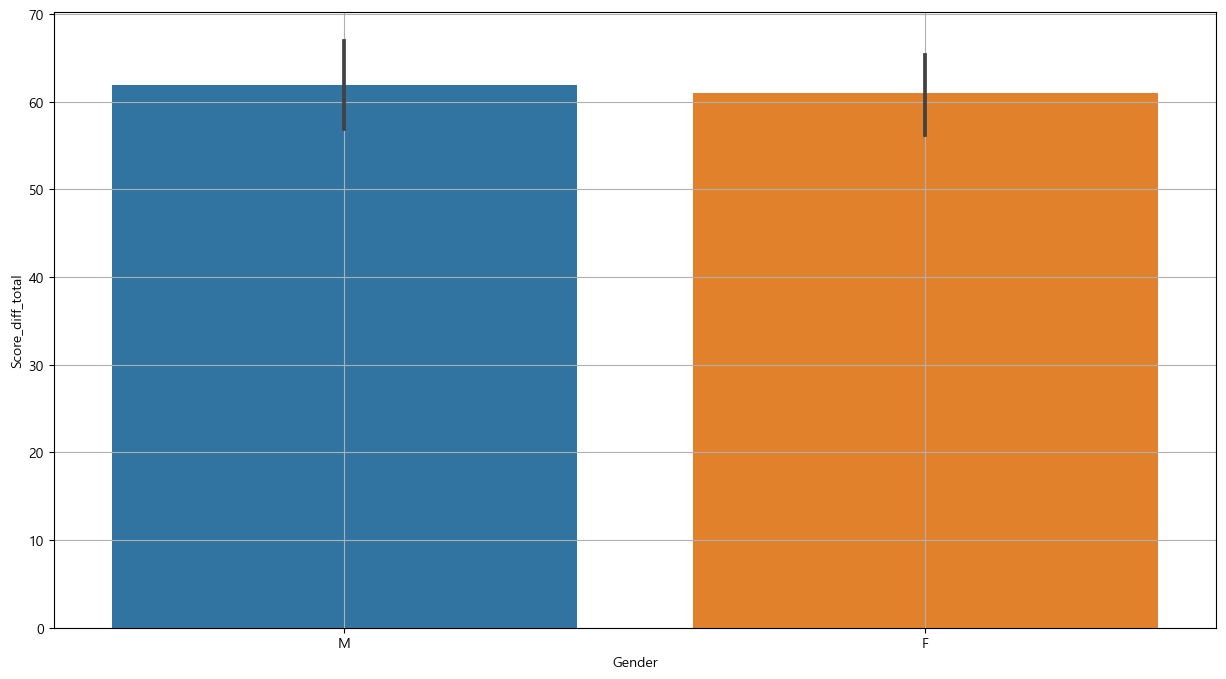
(1) Gender
plt.figure(figsize = (15,8))
sns.barplot(x='Gender', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
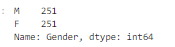
## 범주 데이터 확인 : value_counts()
base_data['Gender'].value_counts()
## 평균 분석 : ttest_ind
t_male = base_data.loc[base_data['Gender']=='M', 'Score_diff_total']
t_female = base_data.loc[base_data['Gender']=='F', 'Score_diff_total']
spst.ttest_ind(t_male, t_female)
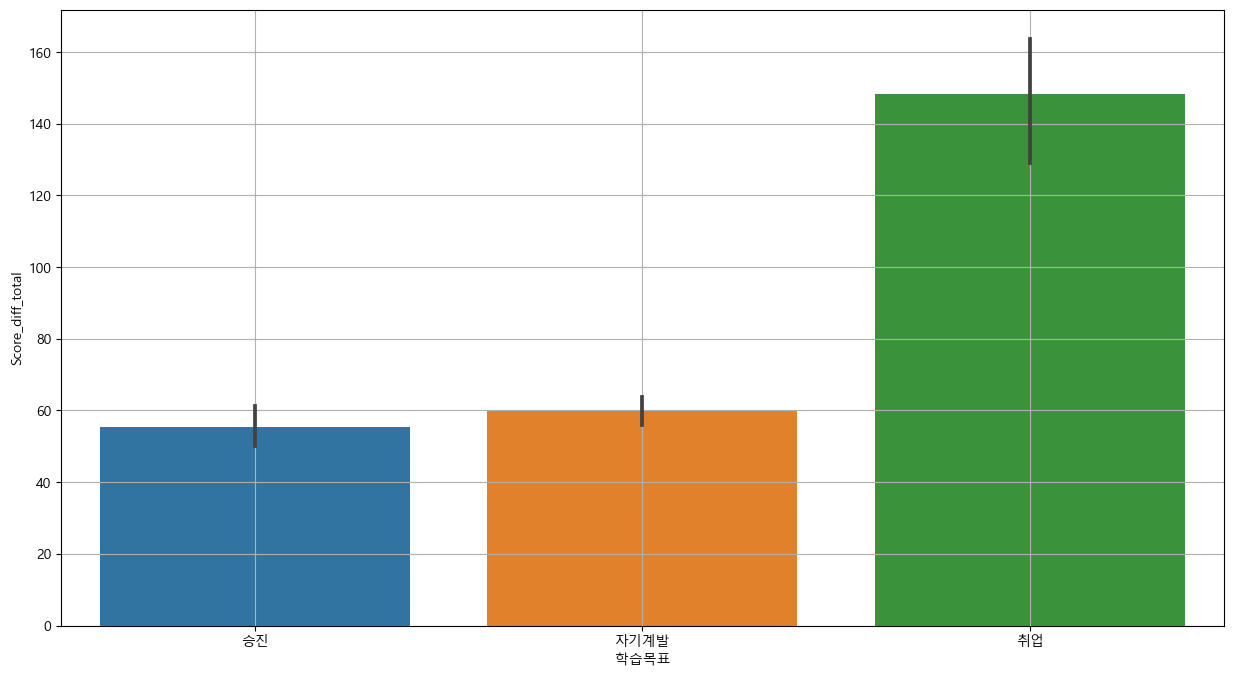
3-2-2) 학습목표
# 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습목표', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습목표'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['학습목표']=='승진', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습목표']=='자기계발', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습목표']=='취업', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
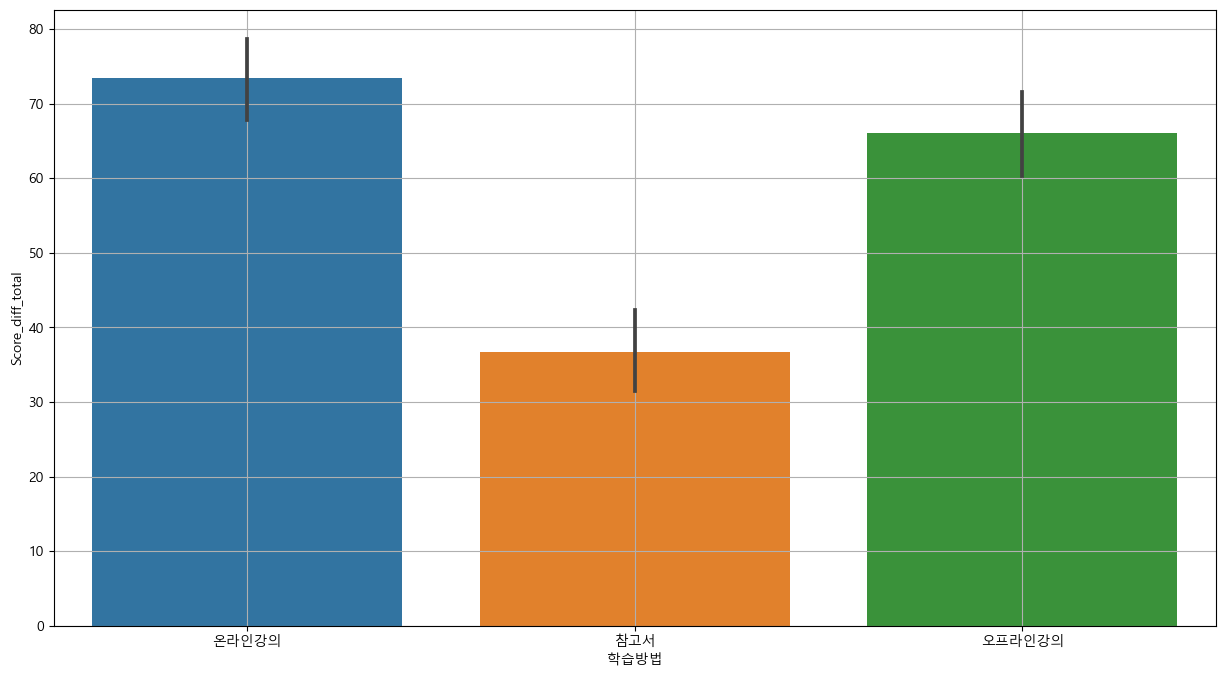
3-2-3) 학습방법
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='학습방법', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['학습방법'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['학습방법']=='온라인강의', 'Score_diff_total']
anova_2 = base_data.loc[base_data['학습방법']=='오프라인강의', 'Score_diff_total']
anova_3 = base_data.loc[base_data['학습방법']=='참고서', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3)
3-2-4) 강의 학습 교재 유형
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='강의 학습 교재 유형', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['강의 학습 교재 유형'].value_counts()
## 분산 분석 : f_oneway
anova_1 = base_data.loc[base_data['강의 학습 교재 유형']=='일반적인 영어 텍스트 기반 교재', 'Score_diff_total']
anova_2 = base_data.loc[base_data['강의 학습 교재 유형']=='영상 교재', 'Score_diff_total']
anova_3 = base_data.loc[base_data['강의 학습 교재 유형']=='뉴스/이슈 기반 교재', 'Score_diff_total']
anova_4 = base_data.loc[base_data['강의 학습 교재 유형']=='비즈니스 시뮬레이션(Role Play)', 'Score_diff_total']
spst.f_oneway(anova_1, anova_2, anova_3, anova_4)
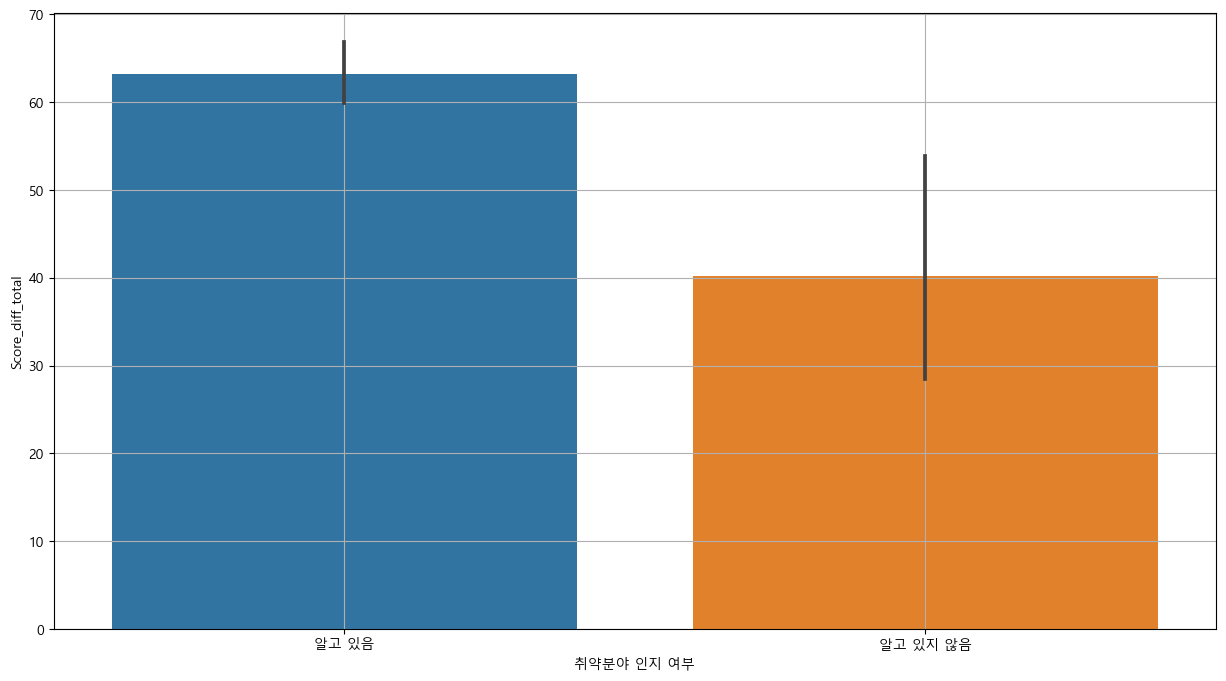
3-2-6) 취약분야 인지 여부
## 그래프 분석 : barplot
plt.figure(figsize = (15,8))
sns.barplot(x='취약분야 인지 여부', y='Score_diff_total', data = base_data)
plt.grid()
plt.show()
## 범주 데이터 확인 : value_counts()
base_data['취약분야 인지 여부'].value_counts()
## 평균 분석 : ttest_ind
t_yes = base_data.loc[base_data['취약분야 인지 여부']=='알고 있음', 'Score_diff_total']
t_no = base_data.loc[base_data['취약분야 인지 여부']=='알고 있지 않음', 'Score_diff_total']
spst.ttest_ind(t_yes, t_no)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as spst
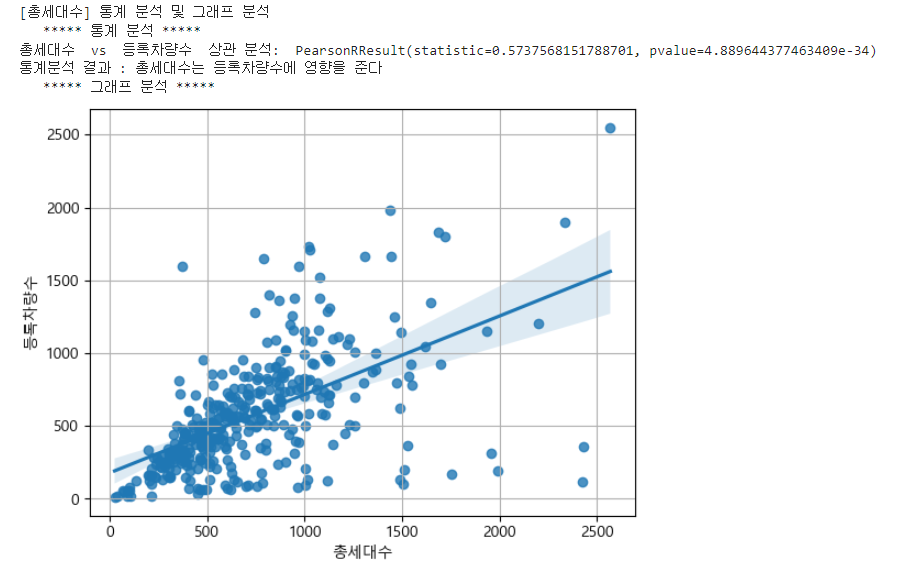
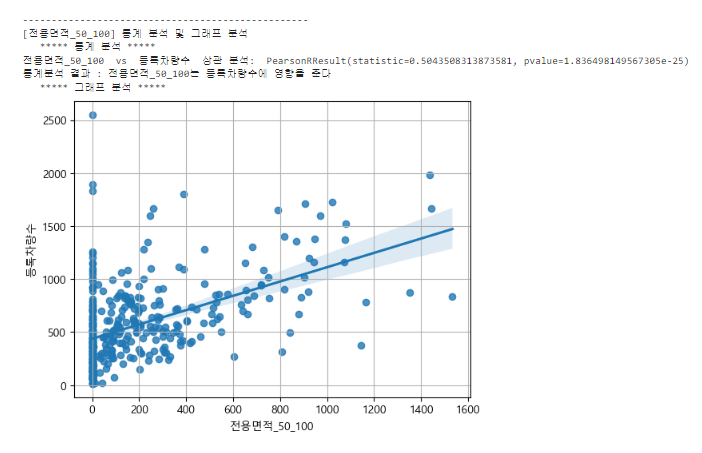
target = '등록차량수'
for feature in analyze_features:
print(f"[{feature}] 통계 분석 및 그래프 분석")
# 통계 분석 : 통계 분석
print(" ***** 통계 분석 *****")
result = spst.pearsonr(data[feature], data[target])
print(feature, " vs ", target, " 상관 분석: ", spst.pearsonr(data[feature], data[target]))
if result[1] > 0.05:
print(f"통계분석 결과 : {feature}는 등록차량수에 영향을 주지 않는다")
else:
print(f"통계분석 결과 : {feature}는 등록차량수에 영향을 준다")
# 그래프 분석 : regplot
# plt.figure(figsize = (12,8))
print(" ***** 그래프 분석 *****")
sns.regplot(x = feature, y= target, data = data)
plt.grid()
plt.show()
print("")
print("-"*50)
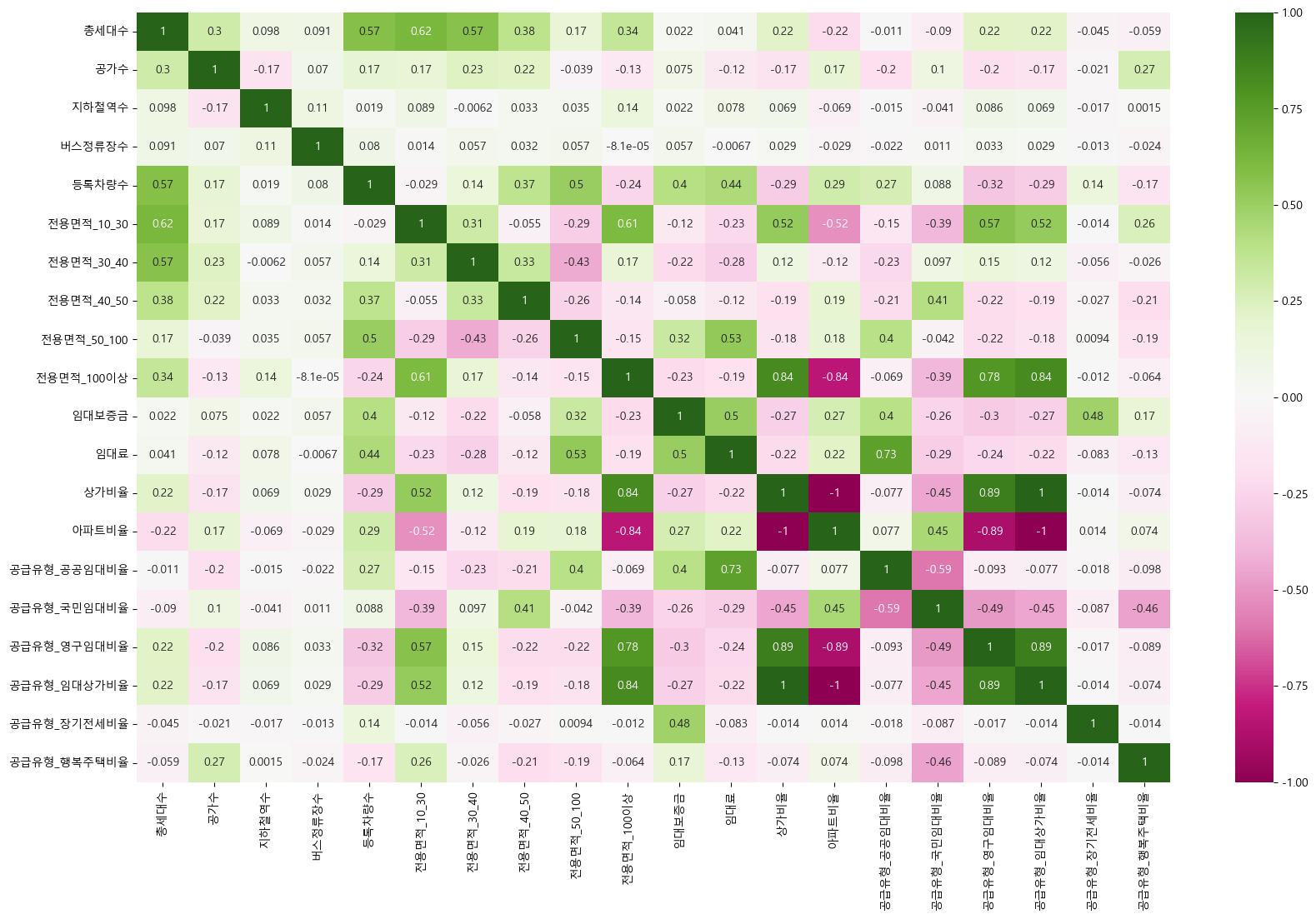
heatmap
## 각 컬럼간 상관계수에 대한 heatmap 그래프 분석
plt.figure(figsize = (20,12))
sns.heatmap(data[col_num].corr(),cmap="PiYG", annot=True)
plt.show()