from datetime import datetime
from datetime import timedelta
import pandas as pd
import requests
import pprint
from os import name
import pandas as pd
import bs4
response = requests.get(url, params=params)
# xml 내용
content = response.text
print('content',content)
# 깔끔한 출력 위한 코드
pp = pprint.PrettyPrinter(indent=4)
print('pp', pp)
### xml을 DataFrame으로 변환하기 ###
from os import name
import pandas as pd
import bs4
#bs4 사용하여 item 태그 분리
xml_obj = bs4.BeautifulSoup(content,'lxml-xml')
print('xml_obj', xml_obj)
rows = xml_obj.findAll('item')
print(rows)
# 각 행의 컬럼, 이름, 값을 가지는 리스트 만들기
row_list = [] # 행값
name_list = [] # 열이름값
value_list = [] #데이터값
# xml 안의 데이터 수집
for i in range(0, len(rows)):
columns = rows[i].find_all()
#첫째 행 데이터 수집
for j in range(0,len(columns)):
if i ==0:
# 컬럼 이름 값 저장
name_list.append(columns[j].name)
# 컬럼의 각 데이터 값 저장
value_list.append(columns[j].text)
# 각 행의 value값 전체 저장
row_list.append(value_list)
# 데이터 리스트 값 초기화
value_list=[]
#xml값 DataFrame으로 만들기
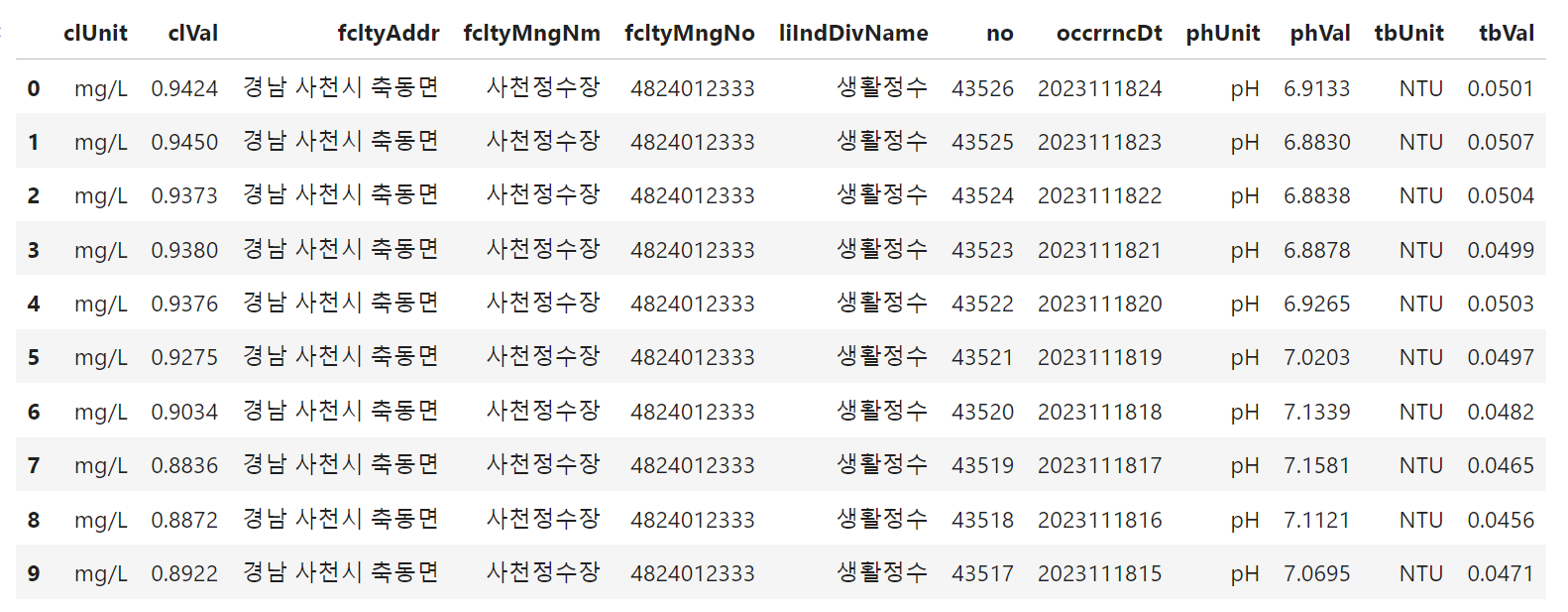
water_df = pd.DataFrame(row_list, columns=name_list)
print(water_df.head(19))
#xml값 DataFrame으로 만들기
#Assertion Error가 난 경우
water_df = pd.DataFrame(water_df)
# 이후에 컬럼을 설정해 주세요.
water_df
: 결석 없이 교육에 성실히 참여하실 경우 최대 31.6만원의 지원금을 받으며 공부하실 수 있습니다.
교육비가 무료인데 추가로 지원금도 받을 수 있으니 좋은 기회라고 생각했어요.
현재까지 후기
ㆍ AIVLE School에 참여하면서 좋았던 점 중에서 하나는 스터디원들을 구하기 쉽다는 것입니다.
저는 개인적으로 "백준 문제풀이", "SQL 프로그래머스 문제풀이" 스터디장을 맡아서 매주 스터디를 진행하고 있습니다.
에이블스쿨이라는 기회가 없었다면, 이렇게 좋은 스터디원들을 만나기 힘들었을 거라고 생각하고 있어요.
ㆍ 또한, 공모전에 나가고 싶을 때도 사람들을 모집하기 쉽다는 점 또한 있습니다.
위 사진은 공모전 회의를 할 때 모습입니다. Teams를 통해 자료들을 간편하게 주고 받으니 공모전을 원활하게 할 수 있었어요. 에이블스쿨에서 처음으로 진행했던 공모전이라 기억에 많이 남네요. 이때, 에이블스쿨 수업 중 "데이터 다루기", "데이터 다듬기"에서 배운 내용을 많이 활용하였고 실력을 키울 수 있는 좋은 기회였습니다.
친구 추천 이벤트
지금 Aivle School 5기 친구 추천 이벤트에 참여하시면 커피 쿠폰도 나눠드리고 있으니 참고해주세요!!
나이키와 포드를 예시로 성공적인 DX를 이루어내는 데에 중요한 요인을 배울 수 있었다. 나이키는 고객 중심으로 서비스를 기획하며 코로나 시기에도 높은 실적을 기록했다. 포드는 기술 성장을 위해 많은 돈을 들여 다양한 스타트업을 인수하고 "포드 스마트 모빌리티"를 설립했다. 하지만, 각 사업부가 독립적으로 일이 진행되면서 기술과 업무가 통합되지 않았고다. 이에 따라 포드 스마트 모빌리티는 기계의 변속기 이상, 안정성 등의 문제가 반복되는 모습을 보여주었다.
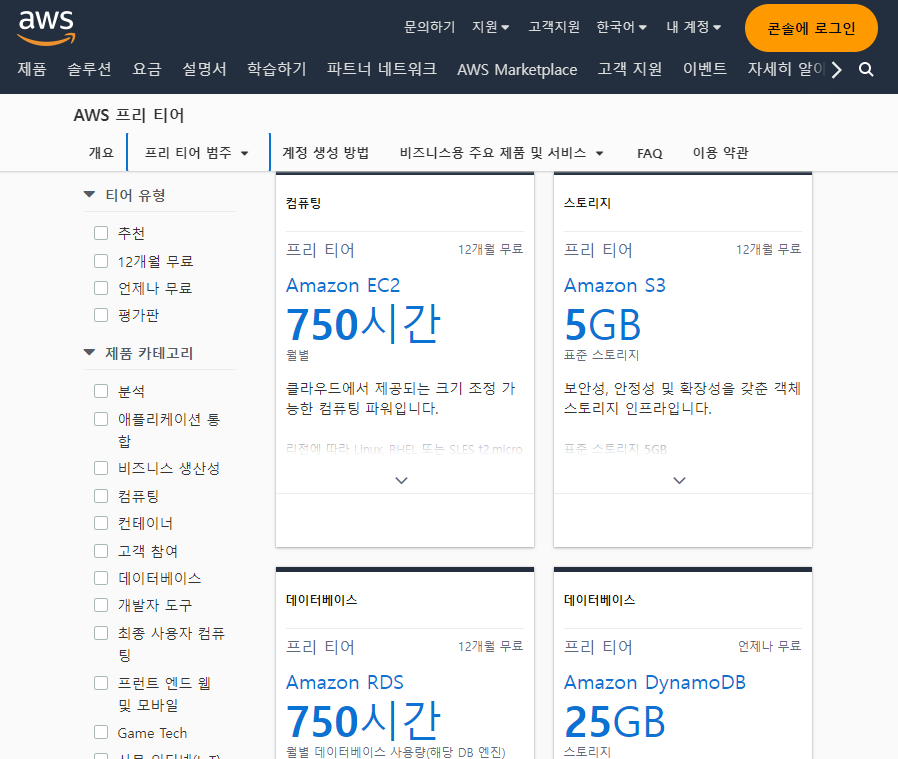
클라우드 이론 및 AWS 경험
수업 때 클라우드 이론을 배운 뒤, AWS를 통해 실습을 진행하며 VPC, Subnet, 인터넷 게이트웨이, 보안그룹 등을 다루어 보니 클라우드 개념에 대한 이해도를 높이는 데에 도움이 되었다. 수업에서 받은 계정은 금요일 수업 종료와 동시에 삭제되어 아쉬움이 있었고, AWS 홈페이지를 뒤져보며 무료로 연습을 해볼 방법이 있는지 알아보고 있다.
돌아오는 주에는 6차 미니 프로젝트 진행
돌아오는 주 3일 동안은 미니 프로젝트를 진행하게되었다. 현재까지 미프를 진행해온 결과, 여러 번 같은 조가 된 에이블러들을 볼 수 있었다. 현재 우리 조 상황은 조원들이 온다면 수요일에 많이 올 것으로 예상되고, 나도 상황을 보면서 대면 교육장을 갈지 결정하려고 한다.
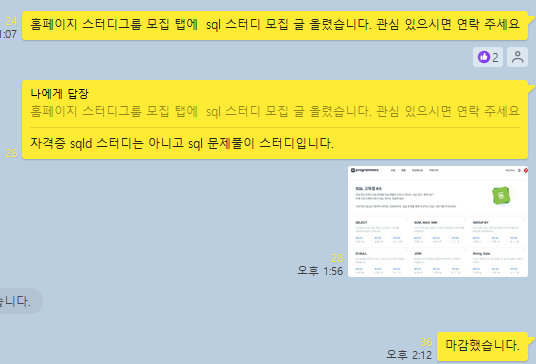
SQL 스터디원 모집
회사 채용 공고들을 보면서 느낀 결과, SQL은 많은 직무에서 우대 받을 수 있는 역량임을 볼 수 있었고, DX 과정에서는 SQL 수업을 따로 진행하지 않기 때문에 이를 꾸준히 공부하고자 직접 스터디원들을 모집했다.
하고 싶은 일이 생겼을 때는 망설이지 않는 스타일이기에 바로 KT 에이블러들 단체 카톡방에 말을 했고, DX 에이블러 스터티그룹원 모집 게시판에도 글을 올렸다. 이 부분에 비슷한 고민이 있는 사람들이 있어서였는지 생각보다 빠르게 스터디원들을 구하고 마감할 수 있었다.
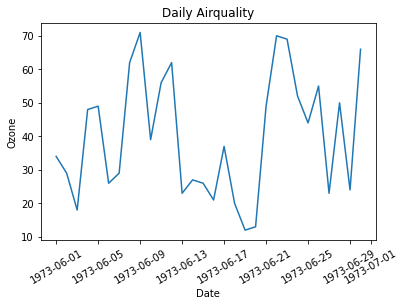
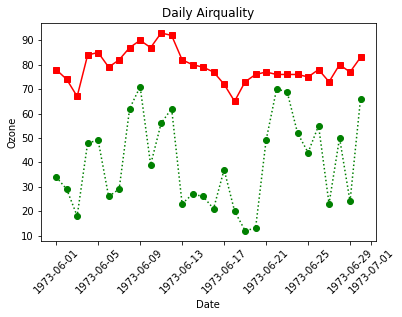
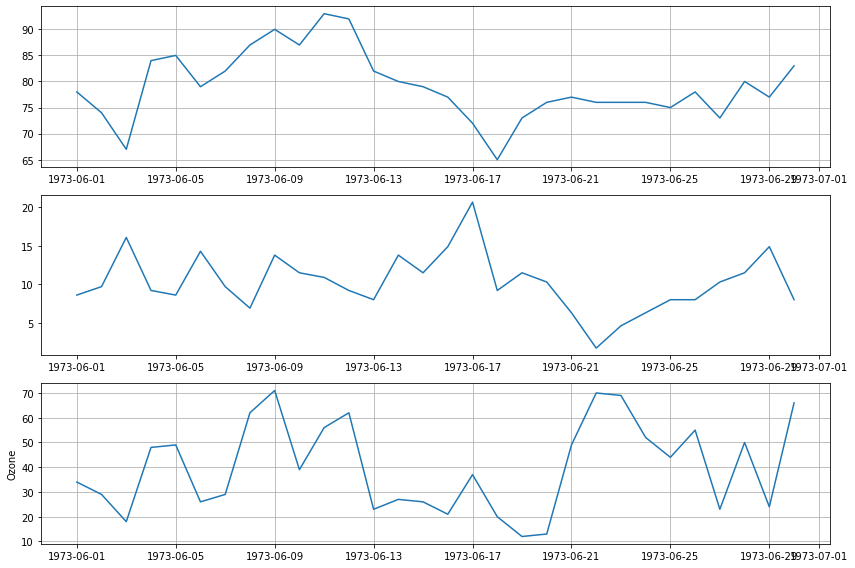
plt.plot(data['Date'], data['Ozone'])
plt.xticks(rotation = 30) # x축 값 꾸미기 : 방향을 30도 틀어서
plt.xlabel('Date') # x축 이름 지정
plt.ylabel('Ozone') # y축 이름 지정
plt.title('Daily Airquality') # 타이틀
plt.show()